pandas添加新列的5种常见方法
目录
- 前言
- 一、insert()函数
- 二、直接赋值法
- 三、reindex()函数
- 四、concat()函数
- 五、loc()函数
- 附:pandas根据现有列新添加一列
- 总结
前言
pandas为DataFrame格式数据添加新列的方法非常简单,只需要新建一个列索引,再为其赋值即可。
以下总结了5种常见添加新列的方法。
首先,创建一个DataFrame结构数据,作为数据举例。
import pandas as pd
# 创建一个DataFrame结构数据
data = {'a': ['a0', 'a1', 'a2'],
'b': ['b0', 'b1', 'b2']}
df = pd.DataFrame(data)
print('举例数据情况:\n', df)

添加新列的方法,如下:
一、insert()函数
语法:
DataFrame.insert(loc, column, value,allow_duplicates = False)
| 参数 | 说明 |
|---|---|
| loc | 必要字段,int类型数据,表示插入新列的列位置,原来在该位置的列将向右移。 |
| column | 必要字段,插入新列的列名。 |
| value | 必要字段,新列插入的值。如果仅提供一个值,将为所有行设置相同的值。可以是int,string,float等,甚至可以是series /值列表。 |
| allow_duplicates | 布尔值,用于检查是否存在具有相同名称的列。默认为False,不允许与已有的列名重复。 |
实例:插入c列
df.insert(loc=2, column='c', value=3) # 在最后一列后,插入值全为3的c列
print('插入c列:\n', df)

二、直接赋值法
语法:df[‘新列名’]=新列的值
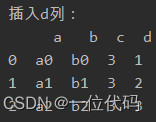
实例:插入d列
df['d'] = [1, 2, 3] # 插入值为[1,2,3]的d列
print('插入d列:\n', df)
注:该方法不可以选择插入新列的位置,默认为最后一列。如果新增的一列值相同,直接为其赋值一个常量即可;如果插入值不同,为列表格式,需与已有列的行数长度一致,如举例中原来列为3行,新增列也必须有3个值。
三、reindex()函数
语法:df.reindex(columns=[原来所有的列名,新增列名],fill_value=值)
reindex()函数用法较多,此处只是针对添加新列的用法
实例:插入e列
df1 = df.reindex(columns=['a', 'b', 'c', 'd', 'e']) # 不加fill_value参数,默认值为Nan
df2 = df.reindex(columns=['a', 'b', 'c', 'd', 'e'], fill_value=1) # 加入fill_value参数,填充值为1
print('插入e列(不加fill_value参数):\n', df1)
print('插入e列(加fill_value参数):\n', df2)

注:该方法需要把原有的列名和新列名都加上,如果列名过多,就比较麻烦。
四、concat()函数
原理:利用拼接的方式,添加新的一列。好处是可以同时新增多个列名。
concat()函数用法较多,此处只是针对添加新列的用法
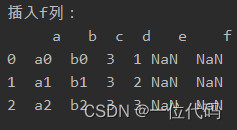
实例:插入f列
df1 = pd.concat([df1, pd.DataFrame(columns=['f'])])
print('插入f列:\n', df1)
五、loc()函数
原理:利用loc的行列索引标签来实现。
语法:df.loc[:,新列名]=值
实例:插入g列
df1.loc[:, 'g'] = 0
print('插入g列:\n', df1)

以上就是pandas添加新列的5种常见用法。
附:pandas根据现有列新添加一列
pandas中一个Dataframe,经常需要根据其中一列再新建一列,比如一个常见的例子:需要根据分数来确定等级范围,下面我们就来看一下怎么实现。
def getlevel(score):
if score < 60:
return "bad"
elif score < 80:
return "mid"
else:
return "good"
def test():
data = {'name': ['lili', 'lucy', 'tracy', 'tony', 'mike'],
'score': [85, 61, 75, 49, 90]
}
df = pd.DataFrame(data=data)
# 两种方式都可以
# df['level'] = df.apply(lambda x: getlevel(x['score']), axis=1)
df['level'] = df.apply(lambda x: getlevel(x.score), axis=1)
print(df)
上面代码运行结果
name score level
0 lili 85 good
1 lucy 61 mid
2 tracy 75 mid
3 tony 49 bad
4 mike 90 good
要实现上面的功能,主要是使用到dataframe中的apply方法。
上面的代码,对dataframe新增加一列名为level,level由分数一列而来,如果小于60分为bad,60-80之间为mid,80以上为good。
其中axis=1表示原有dataframe的行不变,列的维数发生改变。
总结
到此这篇关于pandas添加新列的5种常见方法的文章就介绍到这了,更多相关pandas添加新列内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python中pandas.DataFrame对行与列求和及添加新行与列示例
本文介绍的是python中pandas.DataFrame对行与列求和及添加新行与列的相关资料,下面话不多说,来看看详细的介绍吧. 方法如下: 导入模块: from pandas import DataFrame import pandas as pd import numpy as np 生成DataFrame数据 df = DataFrame(np.random.randn(4, 5), columns=['A', 'B', 'C', 'D', 'E']) DataFrame数据预览: A
-

pandas添加自增列的2种实现方案
有时候我们需要添加一列自动增加数字的列,可以用下面两种方法: 第一种 >>> import pandas as pd >>> df = pd.DataFrame([{'name':'apple', 'count':4},\ {'name':'orange', 'count':2}]) >>> df = df.reset_index() >>> df.columns.values[0] = 'New_ID' >>> d
-
pandas调整列的顺序以及添加列的实现
在对excel的操作中,调整列的顺序以及添加一些列也是经常用到的,下面我们用pandas实现这一功能. 1.调整列的顺序 >>> df = pd.read_excel(r'D:/myExcel/1.xlsx') >>> df A B C D 0 bob 12 78 87 1 millor 15 92 21 >>> df.columns Index(['A', 'B', 'C', 'D'], dtype='object') # 这是最简单常用的一种方法,
-
pandas删除行删除列增加行增加列的实现
创建df: >>> df = pd.DataFrame(np.arange(16).reshape(4, 4), columns=list('ABCD'), index=list('1234')) >>> df A B C D 1 0 1 2 3 2 4 5 6 7 3 8 9 10 11 4 12 13 14 15 1,删除行 1.1,drop 通过行名称删除: df = df.drop(['1', '2']) # 不指定axis默认为0 df.drop(['1',
-
pandas选择或添加列生成新的DataFrame操作示例
目录 如何向 pandas.DataFrame 添加新的列或行 选择某些列 选择某些列和行 添加新的列 更改某一列的值 补全缺失值 如何向 pandas.DataFrame 添加新的列或行 通过指定新的列名/行名来添加,或者用pandas.DataFrame的assign().insert().append()方法添加等方法. 这里,将描述以下内容. 将列添加到 pandas.DataFrame 通过指定新列名添加 用assign()方法添加/分配 用insert()方法添加到任意位置 使用 c
-
pandas 添加空列并赋空值案例
创建测试dataframe: >>> import pandas as pd >>> df = pd.DataFrame([{'a':1, 'b':2}, {'a':3, 'b':4}]) >>> df a b 0 1 2 1 3 4 添加两个空列 >>> df[['c','d']]=df.apply(lambda x:('',''),axis=1,result_type='expand') >>> df a b c
-
基于pandas向csv添加新的行和列
首先创建一个csv文件,创建方式为新建一个文本文档,然后将这个文本文档重命名为test.csv 再用Excel打开,添加内容 内容如下: 先来添加列 data = ['a','b','c'] df['字母'] = data import pandas as pd filename = './test.csv' df = pd.read_csv(filename,encoding='gbk') data = ['a','b','c'] df['字母'] = data df.to_csv(filen
-
Python Pandas 对列/行进行选择,增加,删除操作
一.列操作 1.1 选择列 d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print (df ['one']) # 选择其中一列进行显示,列长度为最长列的长度 # 除了 index 和 数据,还会显示 列表头名,和 数据 类型 运行结果: a 1.0 b
-
pandas添加新列的5种常见方法
目录 前言 一.insert()函数 二.直接赋值法 三.reindex()函数 四.concat()函数 五.loc()函数 附:pandas根据现有列新添加一列 总结 前言 pandas为DataFrame格式数据添加新列的方法非常简单,只需要新建一个列索引,再为其赋值即可. 以下总结了5种常见添加新列的方法. 首先,创建一个DataFrame结构数据,作为数据举例. import pandas as pd # 创建一个DataFrame结构数据 data = {'a': ['a0', 'a
-
SQL Server表中添加新列并添加描述
注: sql server 2005 及以上支持. 版本估计是不支持(工作环境2005,2008). 工作需要, 需要向SQL Server 现有表中添加新列并添加描述. 从而有个如下存储过程. (先附上存储过程然后解释) /********调用方法********** 作用: 添加列并添加列描述信息 调用: exec [SetColumnInfo] '表名', '列名', N'列说明,描述','列类型{默认:NVARCHAR(50)}','列默认值{默认:NULL}' ************
-
Android开发中数据库升级且表添加新列的方法
本文实例讲述了Android开发中数据库升级且表添加新列的方法.分享给大家供大家参考,具体如下: 今天突然想到我们android版本升级的时候经常会遇到升级版本的时候在新版本中数据库可能会修改,今天我们就以数据库升级且表添加新列为例子写一个测试程序. 首先在要创建一个数据库,一般我们先创建一个DbHelper,继承SQLiteOpenHelper,构造函数我们使用传递版本号的: public DbHelper(Context context, String name, int version){
-
vue中向data添加新属性的三种方式小结
目录 向data添加新属性的三种方式 原理分析 三种方式 vue组件 data等属性介绍 向data添加新属性的三种方式 原理分析 首先在了解这三种方式之前,我觉的有必要说一下,为啥不能直接手动给data中的对象添加属性呢? 下面咱们一块分析下: vue2 是通过数据劫持 “Object.defineProperty” 实现数据响应式: const obj = {}; let val = 'kk' Object.defineProperty(obj,'na
-
ASP.NET中弹出消息框的几种常见方法
本文实例讲述了ASP.NET中弹出消息框的几种常见方法.分享给大家供大家参考.具体分析如下: 在ASP.NET网站开发中,经常需要使用到alert消息框,尤其是在提交网页的时候,往往需要在服务器端对数据进行检验,并给出提示或警告. 这里,仅介绍几种不同的实现方法. 1.众所周知的方法是采用如下代码来实现: 复制代码 代码如下: Response.Write("<script>alert('弹出的消息')</script>"); 不可否认,这种方法是最常用,也是最
-
python列表去重的5种常见方法实例
目录 前言 一.使用for循环实现列表去重 二.使用列表推导式去重 三.使用集合转换函数set()实现列表去重 四.使用新建字典方式实现列表去重 五.删除列表中存在重复的数据 附:Python 二维数组元素去重 np.unique()函数的使用 总结 前言 列表去重在python实际运用中,十分常见,也是最基础的重点知识. 以下总结了5种常见的列表去重方法 一.使用for循环实现列表去重 此方法去重后,原顺序保持不变. # for循环实现列表去重 list1 = ['a', 'b', 1, 3,
-
JavaScript数组合并的8种常见方法小结
目录 1.ES6 解构 2.遍历添加 3.concat 4.join & split 5.解构添加 6.splice解构 7.apply 8.call 补充:两个数组的交叉合并 总结 1.ES6 解构 [...arr, ...array] 不改原数组值,生成新的数组. 2.遍历添加 array.forEach(item => { arr.push(item) }) 遍历方法:forEach.map.filter.every.for.for in.for of等. 添加方法:push(后追加)
-
C#中txt数据写入的几种常见方法
前言 小伙伴们在使用C#开发时,可能需要将一些信息写入到txt,这里就给大家介绍几种常用的方法. 方法: 1.将由字符串组成的数组写入txt 此种方法不需要使用Flush和Close(). 如果没有WriteLines.txt,系统会自动帮忙创建一个 string[] lines = { "这是第一行", "这是第二行", "这是第三行" }; System.IO.File.WriteAllLines(@"想保存的位置\WriteLin
-
Python爬虫定时计划任务的几种常见方法(推荐)
记得以前的Windows任务定时是可以正常使用的,今天试了下,发现不能正常使用了,任务计划总是挂起.接下来记录下Python爬虫定时任务的几种解决方法. 1.方法一.while True 首先最容易的是while true死循环挂起,不废话,直接上代码: import os import time import sys from datetime import datetime, timedelta def One_Plan(): # 设置启动周期 Second_update_time = 24
-
Django 添加静态文件的两种实现方法(必看篇)
Django添加静态文件有两种方法: 首先setting.py配置文件中添加静态文件的路径: STATICFILES_DIRS = [ os.path.join(BASE_DIR, "statics"),] statices为你所建立的存放静态文件的文件夹名 然后进行引用. 1.html 文件中通过 /static/资源名的方式,就可以访问到资源 2.①html 文件头部填写 {% load staticfiles %},②路径填写 {% static 'css/xx.css'