Java超详细分析讲解哈希表
目录
- 哈希表概念
- 哈希函数的构造
- 平均数取中法
- 折叠法
- 保留余数法
- 哈希冲突问题以及解决方法
- 开放地址法
- 再哈希函数法
- 公共溢出区法
- 链式地址法
- 哈希表的填充因子
- 代码实现
- 哈希函数
- 添加数据
- 删除数据
- 判断哈希表是否为空
- 遍历哈希表
- 获得哈希表已存键值对个数
哈希表概念
- 散列表,又称为哈希表(Hash table),采用散列技术将记录存储在一块连续的存储空间中。
- 在散列表中,我们通过某个函数f,使得存储位置 = f(关键字),这样我们可以不需要比较关键字就可获得需要的记录的存储位置。
- 散列技术的记录之间不存在什么逻辑关系,它只与关键字有关联。因此,散列主要是面向查找的存储结构。
哈希函数的构造
构造原则:
- 计算简单
散列函数的计算时间不应该超过其他查找技术与关键字比较的时间。
- 散列地址分布均匀
解决冲突最好的办法就是尽量让散列地址均匀地分布在存储空间中。
- 保证存储空间的有效利用,并减少为处理冲突而耗费的时间。
构造方法:
平均数取中法
假设关键字是1234,那么它的平方就是1522756.在抽取中间的3位就是227,用作散列地址。再比如关键字4321,那么它的平方就是18671041,抽中间三位数就是671或710。平方去中法比较适合不知道关键字的分布,而位数又不是很多的情况。
折叠法
折叠法是将关键字从左到右分割成位数相等的几部分(注意最后一部分位数不够时可以短一些),然后将这几部分叠加求和,并按散列表表长,取几位作为散列表地址。
比如我们的关键字是9 8 7 6 5 4 3 2 1 0,散列表表长为3位,我们将它分为四组,987|654|321|0,然后将他们叠加求和987+654+321+0=1962,再求后3位得到散列地址为962。
有时可能这还不能够保证分布均匀,不妨从一端向另一端来回折叠后对齐相加。比如我们将987和321反转,再与654和0相加,变成789+654+123+0=1566,此时散列地址为566。
折叠法事先不需要知道关键字的分布,适合关键字位数较多的情况。
保留余数法
此方法为最常用的构造哈希函数的方法。
公式为:
f(key) = key mod p (p <= m)
代码如下:
public int hashFunc(int key){
return key % length;
}
哈希冲突问题以及解决方法
哈希冲突就是,两个不同的关键字,但是通过散列函数得出来的地址是一样的。
key1 ≠ key2,但是f(key1)= f(key2)
同义词
此时的key1 和key2就被称为这个散列函数的同义词
那可不行啊,一件单人间怎么可以住两个人呢?
别担心,这个问题自然已经被神通广大的大佬们解决了。
开放地址法
开发定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只需要散列表足够大,空的散列地址总能找到,并将记录存入
例子:
19 01 23 14 55 68 11 86 37
要存储在表长11的数组中,其中H(key)=key MOD 11
再哈希函数法
对于我们的哈希表来说,我们事先需要准备多个哈希函数。每当发生散列地址冲突时,就换一个哈希函数,总有一个哈希函数能够使关键字不聚集。
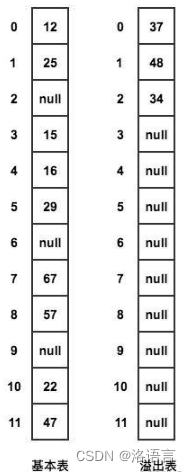
公共溢出区法
在原先基础表的基础上再添加一个溢出表
当发生冲突时,就将该数据放到溢出表中
在查找时,对给定值通过散列函数计算出散列地址后,先与基本表的相应位置进行对比,如果相等就查找成功,如果不相等,则到溢出表进行顺序查找。
链式地址法
就时用链表将发生冲突的数据链起来,在查找时,只需要遍历链表即可,此方法也是最常用的方法。
如图:

哈希表的填充因子
填充因子就是 :填入表中的键值对个数 / 哈希表长度
填充因子标志着哈希表的装满程度,散列表的平均查找长度取决于填充因子,而不是取决于查找集合的键值对个数。Java中的HashMap默认初始容量为16,默认加载因子为0.75(当底层数组容量占用75%时,数组开始扩容,扩容后容量是原容量的二倍),此时虽然浪费了一定空间,但是换来的是查找效率的大大提升。
代码实现
下面用链式地址法来实现哈希表。
public class HashTableDemo {
//哈希表每个位置链表的节点
class Node{
//关键字
int key;
String value;
Node next;
//无参构造
Node(){}
//有参构造
Node(int key, String value){
this.key = key;
this.value = value;
next = null;
}
//重写哈希表的equals()方法
public boolean equals(Node node){
if(this == node) return true;
else{
if(node == null) return false;
else{
return this.value == node.value && this.key == node.key;
}
}
}
}
//哈希表的长度
int length;
//哈希表存的键值对个数
int size;
//存储数据容器
Node table[];
//不指定初始化长度的无参构造
public HashTableDemo(){
length = 16;
size = 0;
table = new Node[length];
//为哈希表每一个位置初始化
for (int i = 0; i < length; i++) {
table[i] = new Node(i,null);
}
}
//指定初始化长度的有参构造
public HashTableDemo(int length){
this.length = length;
size = 0;
table = new Node[length];
for (int i = 0; i < length; i++) {
table[i] = new Node(i,null);
}
}
}
哈希函数
public int hashFunc(int key){
return key % length;
}
添加数据
思路:
- 先通过哈希函数算出该键值对在table中的位置。
- 遍历该处的链表的每一个节点,若发现某节点的key与传入的key相等,那么就更新此处的value。
- 若未发现相等的key,那么在链表末尾添加新的节点.
- 最后返回value。
代码如下:
public String put(int key, String value){
int index = hashFunc(key);
//保证cur2始终是cur的前一个节点。
Node cur = table[index].next;
Node cur2 = table[index];
while(cur != null){
if(cur.key == key){
cur.value = value;
return value;
}
cur = cur.next;
cur2 = cur2.next;
}
cur2.next = new Node(key, value);
size++;
return value;
}
删除数据
思路:
- 先通过哈希函数算出该键值对在table中的位置。
- 遍历该处的链表的每一个节点,若发现某节点的key与传入的key相等,那么就删除此节点,并返回它的value。
- 若未发现相等的key,返回null。
代码如下:
public String remove(int key){
int index = hashFunc(key);
Node cur = table[index];
while(cur.next != null){
if(cur.next.key == key){
size--;
String value = cur.next.value;
cur.next = cur.next.next;
return value;
}
cur = cur.next;
}
return null;
}
判断哈希表是否为空
思路:判断哈希表每个位置处的链表是否为空。
public boolean isEmpty(){
for(int i = 0; i < length; i++){
if(table[i].next != null)
return false;
}
return true;
}
遍历哈希表
public void print(){
for(int i = 0; i < length; i++){
Node cur = table[i];
System.out.printf("第%d条链表: ",i);
if(cur.next == null){
System.out.println("null");
continue;
}
cur = cur.next;
while(cur != null){
System.out.print(cur.key + "---"+ cur.value + " ");
cur = cur.next;
}
System.out.println();
}
}
获得哈希表已存键值对个数
//返回哈希表已存数据个数
public int size(){
return size;
}
到此这篇关于Java超详细分析讲解哈希表的文章就介绍到这了,更多相关Java哈希表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java实现哈希表的基本功能
一.哈希表头插法放入元素 /** * user:ypc: * date:2021-05-20; * time: 11:05; */ public class HashBuck { class Node { public int key; int value; Node next; Node(int key, int value) { this.key = key; this.value = value; } } public int usedSize; public Node[] array;
-
JAVA中哈希表HashMap的深入学习
深入浅出学Java--HashMap 哈希表(hash table) 也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,本文会对java集合框架中HashMap的实现原理进行讲解,并对JDK7的HashMap源码进行分析. 一.什么是哈希表 在讨论哈希表之前,我们先大概了解下其他数据结构在新增,查找等基础操作执行性能 数组:采用一段连续的存储单元来存储数据.对于指定下标的查找,时间复杂度为O(1):通过给定值进
-
一文彻底搞定Java哈希表和哈希冲突
一.什么是哈希表? 哈希表也叫散列表,它是基于数组的.这间接带来了一个优点:查找的时间复杂度为 O(1).当然,它的插入时间复杂度也是 O(1).还有一个缺点:数组创建后扩容成本较高. 哈希表中有一个"主流"思想:转换.一个重要的概念是将「键」或「关键字」转换成数组下标.这由"哈希函数"完成. 二.什么是哈希函数? 由上,其作用就是将非 int 的键/关键字转化为 int 的值,使可以用来做数组下标. 比如,HashMap 中就这样实现了哈希函数: static f
-
带你了解Java数据结构和算法之哈希表
目录 1.哈希函数的引入 ①.把数字相加 ②.幂的连乘 2.冲突 3.开放地址法 ①.线性探测 ②.装填因子 ③.二次探测 ④.再哈希法 4.链地址法 5.桶 6.总结 1.哈希函数的引入 大家都用过字典,字典的优点是我们可以通过前面的目录快速定位到所要查找的单词.如果我们想把一本英文字典的每个单词,从 a 到 zyzzyva(这是牛津字典的最后一个单词),都写入计算机内存,以便快速读写,那么哈希表是个不错的选择. 这里我们将范围缩小点,比如想在内存中存储5000个英文单词.我们可能想到每个单词
-
Java深入了解数据结构之哈希表篇
目录 1,概念 2,冲突-避免 3,冲突-避免-哈希函数设计 4,冲突-避免-负载因子调节 5,冲突-解决-闭散列 ①线性探测 ②二次探测 6,冲突-解决-开散列/哈希桶 7,完整代码 1,概念 顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素时,必须要经过关键 码的多次比较.顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( ),搜索的效率取决于搜索过程中 元素的比较次数. 理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素. 如果构造一
-
java数据结构和算法中哈希表知识点详解
树的结构说得差不多了,现在我们来说说一种数据结构叫做哈希表(hash table),哈希表有是干什么用的呢?我们知道树的操作的时间复杂度通常为O(logN),那有没有更快的数据结构?当然有,那就是哈希表: 1.哈希表简介 哈希表(hash table)是一种数据结构,提供很快速的插入和查找操作(有的时候甚至删除操作也是),时间复杂度为O(1),对比时间复杂度就可以知道哈希表比树的效率快得多,并且哈希表的实现也相对容易,然而没有任何一种数据结构是完美的,哈希表也是:哈希表最大的缺陷就是基于数组,因
-
java中哈希表及其应用详解
哈希表也称为散列表,是用来存储群体对象的集合类结构. 什么是哈希表 数组和向量都可以存储对象,但对象的存储位置是随机的,也就是说对象本身与其存储位置之间没有必然的联系.当要查找一个对象时,只能以某种顺序(如顺序查找或二分查找)与各个元素进行比较,当数组或向量中的元素数量很多时,查找的效率会明显的降低. 一种有效的存储方式,是不与其他元素进行比较,一次存取便能得到所需要的记录.这就需要在对象的存储位置和对象的关键属性(设为 k)之间建立一个特定的对应关系(设为 f),使每个对象与一个唯一的存储位置
-
Java数据结构之实现哈希表的分离链接法
哈希表的分离链接法 原理 Hash Table可以看作是一种特殊的数组.他的原理基本上跟数组相同,给他一个数据,经过自己设置的哈希函数变换得到一个位置,并在这个位置当中放置该数据.哦对了,他还有个名字叫散列 0 1 数据1 数据2 就像这个数组,0号位置放着数据1,1号位置放数据2 而我们的哈希表则是通过一个函数f(x) 把数据1变成0,把数据2变成1,然后在得到位置插入数据1和数据2. 非常重要的是哈希表的长度为素数最好!! 而且当插入数据大于一半的时候我们要进行扩充!!! 冲突问题产生 现在
-
Java 哈希表详解(google 公司的上机题)
1 哈希表(散列)-Google 上机题 1) 看一个实际需求,google 公司的一个上机题: 2) 有一个公司,当有新的员工来报道时,要求将该员工的信息加入(id,性别,年龄,住址..),当输入该员工的 id 时,要求查 找到该员工的 所有信息. 3) 要求: 不使用数据库,尽量节省内存,速度越快越好=>哈希表(散列) 2 哈希表的基本介绍 散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构.也就是说,它通 过把关键码值映射到表中一个位置
-
Java超详细分析讲解哈希表
目录 哈希表概念 哈希函数的构造 平均数取中法 折叠法 保留余数法 哈希冲突问题以及解决方法 开放地址法 再哈希函数法 公共溢出区法 链式地址法 哈希表的填充因子 代码实现 哈希函数 添加数据 删除数据 判断哈希表是否为空 遍历哈希表 获得哈希表已存键值对个数 哈希表概念 散列表,又称为哈希表(Hash table),采用散列技术将记录存储在一块连续的存储空间中. 在散列表中,我们通过某个函数f,使得存储位置 = f(关键字),这样我们可以不需要比较关键字就可获得需要的记录的存储位置. 散列技术
-
Java超详细分析讲解final关键字的用法
目录 基本介绍 final细节01 final细节02 基本介绍 final 可以修饰类.属性.方法和局部变量. 在某些情况下,程序员可能有以下需求,就会使用到final: Base Sub 类 1)当不希望类被继承时,可以用final修饰. 2)当不希望父类的某个方法被子类覆盖/重写(override)时,可以用final关键字 修饰.[案例演示:访问修饰符 final 返回类型方法名] 3)当不希望类的的某个属性的值被修改,可以用final修饰.[案例演示: public final dou
-
Java 栈与队列超详细分析讲解
目录 一.栈(Stack) 1.什么是栈? 2.栈的常见方法 3.自己实现一个栈(底层用一个数组实现) 二.队列(Queue) 1.什么是队列? 2.队列的常见方法 3.队列的实现(单链表实现) 4.循环队列 一.栈(Stack) 1.什么是栈? 栈其实就是一种数据结构 - 先进后出(先入栈的数据后出来,最先入栈的数据会被压入栈底) 什么是java虚拟机栈? java虚拟机栈只是JVM当中的一块内存,该内存一般用来存放 例如:局部变量当调用函数时,我们会为函数开辟一块内存,叫做 栈帧,在 jav
-
Java超详细分析泛型与通配符
目录 1.泛型 1.1泛型的用法 1.1.1泛型的概念 1.1.2泛型类 1.1.3类型推导 1.2裸类型 1.3擦除机制 1.3.1关于泛型数组 1.3.2泛型的编译与擦除 1.4泛型的上界 1.4.1泛型的上界 1.4.2特殊的泛型上界 1.4.3泛型方法 1.4.4类型推导 2.通配符 2.1通配符的概念 2.2通配符的上界 2.3通配符的下界 题外话: 泛型与通配符是Java语法中比较难懂的两个语法,学习泛型和通配符的主要目的是能够看懂源码,实际使用的不多. 1.泛型 1.1泛型的用法
-
Java超详细透彻讲解static
目录 1. 引入 2. 理解 3. 使用 3.1 使用范围 3.2 static修饰属性 3.2.1 设计思想 3.2.2 分类 3.2.3 注意 3.2.4 举例 3.2.5 类变量内存解析 3.3 static修饰方法 3.3.1 设计思想 3.3.2 理解 3.3.3 使用 3.3.4 注意 3.3.5 举例 4. 注意 5. 单例 (Singleton)设计模式 5.1 概述 5.2 优点 5.3 单例设计模式-饿汉式 5.4 单例设计模式-懒汉式 5.5 应用场景 1. 引入 当我们编
-
Java超详细整理讲解各种排序
目录 稳定性 直接插入排序 希尔排序 选择排序 堆排序 冒泡排序 快速排序 归并排序 计数排序 稳定性 两个相等的数据,如果经过排序后,排序算法能保证其相对位置不发生变化,则我们称该算法是具备稳定性的排序算法. 直接插入排序 直接插入排序就是每次选择无序区间的第一个元素,在有序区间内选择合适的位置插入. 从数组下标为1开始,将下标为1上的值取出来放在tmp中,然后它和前面的下标j上的值进行比较,如果前面下标j上的值比它大,则前面下标j上的值往后走一步,直到比到j回退到了-1或者j下标上的值比tm
-
Java超详细分析抽象类和接口的使用
目录 什么是抽象类 抽象类语法 总结抽象类: 接口 怎么定义接口 接口间的继承 几个重要的接口 接口comparable comparator接口-比较器 cloneable接口深入理解深拷贝与浅拷贝 怎么使用cloneable接口 浅拷贝: 深拷贝 什么是抽象类 什么是抽象类呢?抽象类顾名思义就是很抽象,就是当我们没有足够的信息去描述这个类的时候我们就可以先不用描述,这样的类就是抽象类. 用代码举个例子: class Shape { public void draw() { System.ou
-
Java超详细分析垃圾回收机制
目录 前言 垃圾回收概述 内存溢出和内存泄漏 垃圾回收算法 标记阶段 STW(Stop-the-World) 回收阶段 标记-清除算法 复制算法 标记-压缩算法 三种算法的比较 总结 前言 在前面我们对类加载, 运行时数据区 ,执行引擎等作了详细的介绍 , 这节我们来看另一重点 : 垃圾回收. 垃圾回收概述 垃圾回收是java的招牌能力 ,极大的提高了开发效率, java是自动化的垃圾回收, 其他语言有的则需要程序员手动回收 , 那么什么是垃圾呢? 垃圾是指在运行程序中没有任何引用指向的对象,这
-
Java超详细分析继承与重写的特点
概念:继承是面向对象语法三大特征之一,继承可以降低代码的沉余度,提高编程的效率.通过继承子类可以随意调用父类中的某些属性与方法,一个子类只能继承一个父类,一个父类可以被多个子类继承.它就好比与我们显示生活中孩子继承父亲的财产.重写的好处在于子类可以根据需要,定义特定于自己的行为. 也就是说子类能够根据需要实现父类的方法,就好比金毛与哈士奇他的特征都是来自狗,仓鼠与松鼠他们他们的特征来自老鼠,而他们身上的不同属于基因突变就相当于重写 继承的特点: 1):java中只支持单根继承,即一个类只能有一个
-
Java超详细透彻讲解接口
目录 一.引入 二.理解 三.使用 四.应用-代理模式(Proxy) 1. 应用场景 2. 分类 3. 代码演示 五.接口和抽象类之间的对比 六.经典题目(排错) 一.引入 一方面,有时必须从几个类中派生出一个子类,继承它们所有的属性和方法.但是,Java不支持多重继承.有了接口,就可以得到多重继承的效果. 另一方面,有时必须从几个类中抽取出一些共同的行为特征,而它们之间又没有is-a的关系,仅仅是具有相同的行为特征而已.例如:鼠标.键盘.打印机.扫描仪.摄像头.充电器.MP3机.手机.数码相机