pytorch查看网络参数显存占用量等操作
1.使用torchstat
pip install torchstat from torchstat import stat import torchvision.models as models model = models.resnet152() stat(model, (3, 224, 224))
关于stat函数的参数,第一个应该是模型,第二个则是输入尺寸,3为通道数。我没有调研该函数的详细参数,也不知道为什么使用的时候并不提示相应的参数。
2.使用torchsummary
pip install torchsummary from torchsummary import summary summary(model.cuda(),input_size=(3,32,32),batch_size=-1)
使用该函数直接对参数进行提示,可以发现直接有显式输入batch_size的地方,我自己的感觉好像该函数更好一些。但是!!!不知道为什么,该函数在我的机器上一直报错!!!
TypeError: can't convert CUDA tensor to numpy. Use Tensor.cpu() to copy the tensor to host memory first.
Update:经过论坛咨询,报错的原因找到了,只需要把
pip install torchsummary
修改为
pip install torch-summary
补充:Pytorch查看模型参数并计算模型参数量与可训练参数量
查看模型参数(以AlexNet为例)
import torch
import torch.nn as nn
import torchvision
class AlexNet(nn.Module):
def __init__(self,num_classes=1000):
super(AlexNet,self).__init__()
self.feature_extraction = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=96,kernel_size=11,stride=4,padding=2,bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2,padding=0),
nn.Conv2d(in_channels=96,out_channels=192,kernel_size=5,stride=1,padding=2,bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2,padding=0),
nn.Conv2d(in_channels=192,out_channels=384,kernel_size=3,stride=1,padding=1,bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=384,out_channels=256,kernel_size=3,stride=1,padding=1,bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=256,out_channels=256,kernel_size=3,stride=1,padding=1,bias=False),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(in_features=256*6*6,out_features=4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(in_features=4096, out_features=4096),
nn.ReLU(inplace=True),
nn.Linear(in_features=4096, out_features=num_classes),
)
def forward(self,x):
x = self.feature_extraction(x)
x = x.view(x.size(0),256*6*6)
x = self.classifier(x)
return x
if __name__ =='__main__':
# model = torchvision.models.AlexNet()
model = AlexNet()
# 打印模型参数
#for param in model.parameters():
#print(param)
#打印模型名称与shape
for name,parameters in model.named_parameters():
print(name,':',parameters.size())
feature_extraction.0.weight : torch.Size([96, 3, 11, 11]) feature_extraction.3.weight : torch.Size([192, 96, 5, 5]) feature_extraction.6.weight : torch.Size([384, 192, 3, 3]) feature_extraction.8.weight : torch.Size([256, 384, 3, 3]) feature_extraction.10.weight : torch.Size([256, 256, 3, 3]) classifier.1.weight : torch.Size([4096, 9216]) classifier.1.bias : torch.Size([4096]) classifier.4.weight : torch.Size([4096, 4096]) classifier.4.bias : torch.Size([4096]) classifier.6.weight : torch.Size([1000, 4096]) classifier.6.bias : torch.Size([1000])
计算参数量与可训练参数量
def get_parameter_number(model):
total_num = sum(p.numel() for p in model.parameters())
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
return {'Total': total_num, 'Trainable': trainable_num}
第三方工具
from torchstat import stat import torchvision.models as models model = models.alexnet() stat(model, (3, 224, 224))
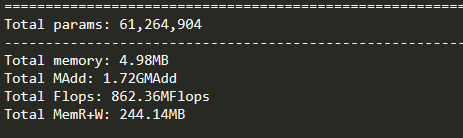
from torchvision.models import alexnet import torch from thop import profile model = alexnet() input = torch.randn(1, 3, 224, 224) flops, params = profile(model, inputs=(input, )) print(flops, params)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
PyTorch和Keras计算模型参数的例子
Pytorch中,变量参数,用numel得到参数数目,累加 def get_parameter_number(net): total_num = sum(p.numel() for p in net.parameters()) trainable_num = sum(p.numel() for p in net.parameters() if p.requires_grad) return {'Total': total_num, 'Trainable': trainable_num} Kera
-
在pytorch中查看可训练参数的例子
pytorch中我们有时候可能需要设定某些变量是参与训练的,这时候就需要查看哪些是可训练参数,以确定这些设置是成功的. pytorch中model.parameters()函数定义如下: def parameters(self): r"""Returns an iterator over module parameters. This is typically passed to an optimizer. Yields: Parameter: module paramete
-

pytorch 计算Parameter和FLOP的操作
深度学习中,模型训练完后,查看模型的参数量和浮点计算量,在此记录下: 1 THOP 在pytorch中有现成的包thop用于计算参数数量和FLOP,首先安装thop: pip install thop 注意安装thop时可能出现如下错误: 解决方法: pip install --upgrade git+https://github.com/Lyken17/pytorch-OpCounter.git # 下载源码安装 使用方法如下: from torchvision.models import r
-
pytorch获取模型某一层参数名及参数值方式
1.Motivation: I wanna modify the value of some param; I wanna check the value of some param. The needed function: 2.state_dict() #generator type model.modules()#generator type named_parameters()#OrderDict type from torch import nn import torch #creat
-
pytorch查看网络参数显存占用量等操作
1.使用torchstat pip install torchstat from torchstat import stat import torchvision.models as models model = models.resnet152() stat(model, (3, 224, 224)) 关于stat函数的参数,第一个应该是模型,第二个则是输入尺寸,3为通道数.我没有调研该函数的详细参数,也不知道为什么使用的时候并不提示相应的参数. 2.使用torchsummary pip in
-
pytorch 一行代码查看网络参数总量的实现
大家还是直接看代码吧~ netG = Generator() print('# generator parameters:', sum(param.numel() for param in netG.parameters())) netD = Discriminator() print('# discriminator parameters:', sum(param.numel() for param in netD.parameters())) 补充:PyTorch查看网络模型的参数量PARA
-
pytorch显存一直变大的解决方案
在代码中添加以下两行可以解决: torch.backends.cudnn.enabled = True torch.backends.cudnn.benchmark = True 补充:pytorch训练过程显存一直增加的问题 之前遇到了爆显存的问题,卡了很久,试了很多方法,总算解决了. 总结下自己试过的几种方法: **1. 使用torch.cuda.empty_cache() 在每一个训练epoch后都添加这一行代码,可以让训练从较低显存的地方开始,但并不适用爆显存的问题,随着epoch的增加
-
Keras - GPU ID 和显存占用设定步骤
初步尝试 Keras (基于 Tensorflow 后端)深度框架时, 发现其对于 GPU 的使用比较神奇, 默认竟然是全部占满显存, 1080Ti 跑个小分类问题, 就一下子满了. 而且是服务器上的两张 1080Ti. 服务器上的多张 GPU 都占满, 有点浪费性能. 因此, 需要类似于 Caffe 等框架的可以设定 GPU ID 和显存自动按需分配. 实际中发现, Keras 还可以限制 GPU 显存占用量. 这里涉及到的内容有: GPU ID 设定 GPU 显存占用按需分配 GPU 显存占
-
详解Pytorch显存动态分配规律探索
下面通过实验来探索Pytorch分配显存的方式. 实验显存到主存 我使用VSCode的jupyter来进行实验,首先只导入pytorch,代码如下: import torch 打开任务管理器查看主存与显存情况.情况分别如下: 在显存中创建1GB的张量,赋值给a,代码如下: a = torch.zeros([256,1024,1024],device= 'cpu') 查看主存与显存情况: 可以看到主存与显存都变大了,而且显存不止变大了1G,多出来的内存是pytorch运行所需的一些配置变量,我们这
-
pytorch 实现查看网络中的参数
可以通过model.state_dict()或者model.named_parameters()函数查看现在的全部可训练参数(包括通过继承得到的父类中的参数) 可示例代码如下: params = list(model.named_parameters()) (name, param) = params[28] print(name) print(param.grad) print('-------------------------------------------------') (name
-
pytorch 在网络中添加可训练参数,修改预训练权重文件的方法
实践中,针对不同的任务需求,我们经常会在现成的网络结构上做一定的修改来实现特定的目的. 假如我们现在有一个简单的两层感知机网络: # -*- coding: utf-8 -*- import torch from torch.autograd import Variable import torch.optim as optim x = Variable(torch.FloatTensor([1, 2, 3])).cuda() y = Variable(torch.FloatTensor([4,
-
Pytorch GPU显存充足却显示out of memory的解决方式
今天在测试一个pytorch代码的时候显示显存不足,但是这个网络框架明明很简单,用CPU跑起来都没有问题,GPU却一直提示out of memory. 在网上找了很多方法都行不通,最后我想也许是pytorch版本的问题,原来我的pytorch版本是0.4.1,于是我就把这个版本卸载,然后安装了pytorch1.1.0,程序就可以神奇的运行了,不会再有OOM的提示了.虽然具体原因还不知道为何,这里还是先mark一下,具体过程如下: 卸载旧版本pytorch: conda uninstall pyt
-
弄清Pytorch显存的分配机制
对于显存不充足的炼丹研究者来说,弄清楚Pytorch显存的分配机制是很有必要的.下面直接通过实验来推出Pytorch显存的分配过程. 实验实验代码如下: import torch from torch import cuda x = torch.zeros([3,1024,1024,256],requires_grad=True,device='cuda') print("1", cuda.memory_allocated()/1024**2) y = 5 * x print(&quo
-
Pytorch反向求导更新网络参数的方法
方法一:手动计算变量的梯度,然后更新梯度 import torch from torch.autograd import Variable # 定义参数 w1 = Variable(torch.FloatTensor([1,2,3]),requires_grad = True) # 定义输出 d = torch.mean(w1) # 反向求导 d.backward() # 定义学习率等参数 lr = 0.001 # 手动更新参数 w1.data.zero_() # BP求导更新参数之前,需先对导