python爬取企查查企业信息之selenium自动模拟登录企查查
最近接了个小项目需要批量搜索企查查上的相关企业并把指定信息保存到Excel文件中,由于企查查需要登录后才能查看所有搜索到的信息所以第一步需要模拟登录企查查。
python模拟登录企查查最重要的是自动拖拽验证插件

先介绍下项目中使用到的工具与库
Python的selenium库:
Web应用程序测试的工具,Selenium可以模拟用户在浏览器中的操作,就像真实用户使用一样。
官方技术文档:https://www.selenium.dev/selenium/docs/api/py/index.html
Chrome浏览器:
谷歌浏览器,不作过多介绍
Chromedriver:
配合Selenium操作Chrome浏览器的驱动程序,注意在下载Chromedriver时必须与已安装的Chrome浏览器版本号前3位保持一至
官方下载地址:http://chromedriver.storage.googleapis.com/index.html
获取完整项目代码请关注下面的公众号“python客栈”然后回复“qcc”

第一步:下载配置Chromedriver
假设电脑中已安装Chrome最新版(如果没有安装请自行下载安装),下载与电脑系统、Chrome版本相匹配的版本(Chromedriver的版本号必须与安装的Chrome版本号一至)。
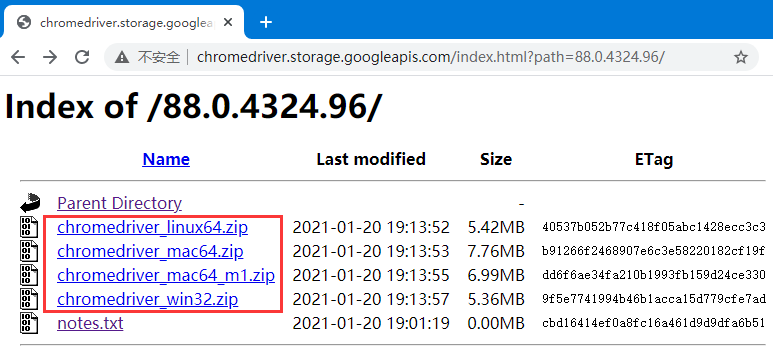
从官网下载的文件是一个压缩包,解压出Chromedriver.exe文件,
网上有很多文章说要正常使用Chromedriver.exe,需要配置系统的环境变量,其实这是一种比较麻烦的方法。
为了项目的可移动性和操作方便使用另一种方法,就是把Chrome浏览器安装目录下的整个Application目录都复制到项目目录下,这样就可以随便移动项目到新开发环境中而不用考虑新环境的系统环境变量了。

把解压出Chromedriver.exe文件复制到项目目录下的从Chrome浏览器安装目录中复制过来的Application目录下,保证Chromedriver.exe文件与chrome.exe文件在同一目录下。

第二步:安装selenium库
pip安装selenium库
pip install selenium
Pycharm开发工具安装selenium库
在Pycharm菜单栏中找到并点击【file】->【settings】

在弹出窗口中按下图所示操作

第三步:自动模拟登录企查查python代码编写
首先引入selenium相关库
import time from selenium import webdriver from selenium.webdriver import ActionChains from selenium.webdriver.support.wait import WebDriverWait from selenium.webdriver.common.by import By from selenium.webdriver.support import expected_conditions as EC from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
初始化webdriver基本配置参数
options = webdriver.ChromeOptions()
# options.add_argument('--headless') # 开启无界面模式
options.add_argument('--disable-gpu') # 禁用gpu,解决一些莫名的问题
options.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度
options.add_argument('--disable-infobars') # 禁用浏览器正在被自动化程序控制的提示
options.add_argument('--start-maximized')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
d = DesiredCapabilities.CHROME
d['goog:loggingPrefs'] = {'performance': 'ALL'}# 获取Headers必须参数
driver = webdriver.Chrome(options=options, executable_path="Application/chromedriver.exe", desired_capabilities=d)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {#清除验证插件中windows.navigator.webdriver的值
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
模拟用户在页面中的一系列操作
driver.implicitly_wait(2)#延时
driver.set_window_size(width=800, height=600)
driver.get("https://www.QCC.com/")
driver.find_element_by_xpath('//a[@class="navi-btn"][1]').click()
locator = (By.ID, "dom_id_two")
try:
WebDriverWait(driver, 20, 0.5).until(EC.presence_of_element_located(locator))
except:
driver.close()
# WebDriverWait(driver,20,0.5).until(lambda driver:driver.find_element_by_xpath('//span[@class="nc_iconfont btn_slide"]'))
# 找到账号输入框
driver.find_element_by_xpath('//input[@id="nameVerify"]').send_keys('手机号')
自动拖动验证插件滑块并验证
验证插件会检测浏览器是否为webdriver即使用JS检查windows.navigator.webdriver值
所以需要在页面加载前手动修改windows.navigator.webdriver值
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
修改完成windows.navigator.webdriver值后再模拟拖动验证插件滑块
# 滑动条定位
start = driver.find_element_by_xpath('//span[@class="nc_iconfont btn_slide"]')
action = ActionChains(driver)
action.click_and_hold(start)
action.drag_and_drop_by_offset(start, 308, 0).perform()
检查验证是否成功
time.sleep(2)
style = 'position:absolute;top:0;left:0;width:100%;z-index:999;font-size:40px;line-height:100px;background:rgba(255,217,0,90%);height:100%;text-align:center;color:#000;'
driver.execute_script(
'var htm=document.getElementsByClassName("login-sao-panel")[0];htm.innerHTML+="<div style={style}><b id=tt></b><b id=ts></b></div>"'.format(
style=style))
ts = driver.find_element_by_id('ts')
tt = driver.find_element_by_id('tt')
try:
driver.find_element_by_xpath('//div[@class="errloading"][1]')
set_id_att(driver, 'tt', 'innerHTML', '请手工验证')
except:
tr = driver.find_element_by_xpath('//span[@class="nc-lang-cnt"][1]')
if tr.text != '验证通过':
set_id_att(driver, 'tt', 'innerHTML', '请手工验证')
# for i in range(1, 6):
# if tr.text == '验证通过':
# break
# set_id_att(driver, 'ts', 'innerHTML', i)
# time.sleep(1)
try:
driver.find_element_by_xpath('//a[@class="text-primary vcode-btn get-mobile-code"]').click()
except:
pass
# code=driver.find_element_by_xpath('//input[@id="vcodeNormal"]')
set_id_att(driver, 'tt', 'innerHTML', '请填入手机验证码')
# rjs='const callback = arguments[arguments.length - 1];callback({v:document.getElementById("vcodeNormal").value})'
rjs = 'return document.getElementById("vcodeNormal").value'
locator = (By.CLASS_NAME, "nav-user")
but = driver.find_element_by_xpath('//form[@id="user_login_verify"]/button')
for i in range(1, 1):
# code = driver.execute_async_script(rjs)
code = driver.execute_script(rjs)
if len(code) == 6:
but.click()
try:
#WebDriverWait(driver, 5, 0.5).until(EC.presence_of_element_located(locator))
break
except:
pass
#return 0
set_id_att(driver, 'ts', 'innerHTML', i)
time.sleep(1)
上面的代码中在页面里增加了一些状态显示元素及JS代码
style = 'position:absolute;top:0;left:0;width:100%;z-index:999;font-size:40px;line-height:100px;background:rgba(255,217,0,90%);height:100%;text-align:center;color:#000;'
driver.execute_script(
'var htm=document.getElementsByClassName("login-sao-panel")[0];htm.innerHTML+="<div style={style}><b id=tt></b><b id=ts></b></div>"'.format(
style=style))
把selenium访问页面元素写成函数方便以后操作
def set_id_att(bor, id, att, val):
bor.execute_script('document.getElementById("{a}").{b}="{c}"'.format(a=id, b=att, c=val))
def set_class_att(bor, classs, id, att, val):
bor.execute_script('document.getElementsByClassName("{a}")[{d}].{b}="{c}"'.format(a=classs, b=att, c=val, d=id))
登录成功后还需要获取页面的headers、Cookie方便后面的requests库使用
selenium获取页面headers头部信息
def getheader(browser):
for responseReceived in browser.get_log('performance'):
try:
response = json.loads(responseReceived[u'message'])[u'message'][u'params'][u'response']
if response[u'url'] == browser.current_url:
return response[u'requestHeaders']
except:
pass
return None
selenium获取页面登录后Cookie
cookie = [item["name"] + "=" + item["value"] for item in driver.get_cookies()] headers['cookie'] = ';'.join(item for item in cookie)
完整代码如下
import time
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
def getheader(browser):
for responseReceived in browser.get_log('performance'):
try:
response = json.loads(responseReceived[u'message'])[u'message'][u'params'][u'response']
if response[u'url'] == browser.current_url:
return response[u'requestHeaders']
except:
pass
return None
def set_id_att(bor, id, att, val):
bor.execute_script('document.getElementById("{a}").{b}="{c}"'.format(a=id, b=att, c=val))
def set_class_att(bor, classs, id, att, val):
bor.execute_script('document.getElementsByClassName("{a}")[{d}].{b}="{c}"'.format(a=classs, b=att, c=val, d=id))
def login():
options = webdriver.ChromeOptions()
# options.add_argument('--headless') # 开启无界面模式
options.add_argument('--disable-gpu') # 禁用gpu,解决一些莫名的问题
options.add_argument('blink-settings=imagesEnabled=false') # 不加载图片, 提升速度
options.add_argument('--disable-infobars') # 禁用浏览器正在被自动化程序控制的提示
options.add_argument('--start-maximized')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
d = DesiredCapabilities.CHROME
d['goog:loggingPrefs'] = {'performance': 'ALL'}
driver = webdriver.Chrome(options=options, executable_path="Application/chromedriver.exe", desired_capabilities=d)
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
driver.implicitly_wait(2)
driver.set_window_size(width=800, height=600)
driver.get("https://www.QCC.com/",)
driver.find_element_by_xpath('//a[@class="navi-btn"][1]').click()
locator = (By.ID, "dom_id_two")
try:
WebDriverWait(driver, 20, 0.5).until(EC.presence_of_element_located(locator))
except:
driver.close()
# WebDriverWait(driver,20,0.5).until(lambda driver:driver.find_element_by_xpath('//span[@class="nc_iconfont btn_slide"]'))
# 找到账号输入框
driver.find_element_by_xpath('//input[@id="nameVerify"]').send_keys('19942496979')
# 滑动条定位
start = driver.find_element_by_xpath('//span[@class="nc_iconfont btn_slide"]')
action = ActionChains(driver)
action.click_and_hold(start)
action.drag_and_drop_by_offset(start, 308, 0).perform()
time.sleep(2)
style = 'position:absolute;top:0;left:0;width:100%;z-index:999;font-size:40px;line-height:100px;background:rgba(255,217,0,90%);height:100%;text-align:center;color:#000;'
driver.execute_script(
'var htm=document.getElementsByClassName("login-sao-panel")[0];htm.innerHTML+="<div style={style}><b id=tt></b><b id=ts></b></div>"'.format(
style=style))
ts = driver.find_element_by_id('ts')
tt = driver.find_element_by_id('tt')
try:
driver.find_element_by_xpath('//div[@class="errloading"][1]')
set_id_att(driver, 'tt', 'innerHTML', '请手工验证')
except:
tr = driver.find_element_by_xpath('//span[@class="nc-lang-cnt"][1]')
if tr.text != '验证通过':
set_id_att(driver, 'tt', 'innerHTML', '请手工验证')
# for i in range(1, 6):
# if tr.text == '验证通过':
# break
# set_id_att(driver, 'ts', 'innerHTML', i)
# time.sleep(1)
try:
driver.find_element_by_xpath('//a[@class="text-primary vcode-btn get-mobile-code"]').click()
except:
pass
# code=driver.find_element_by_xpath('//input[@id="vcodeNormal"]')
set_id_att(driver, 'tt', 'innerHTML', '请填入手机验证码')
# rjs='const callback = arguments[arguments.length - 1];callback({v:document.getElementById("vcodeNormal").value})'
rjs = 'return document.getElementById("vcodeNormal").value'
locator = (By.CLASS_NAME, "nav-user")
but = driver.find_element_by_xpath('//form[@id="user_login_verify"]/button')
for i in range(1, 1):
# code = driver.execute_async_script(rjs)
code = driver.execute_script(rjs)
if len(code) == 6:
but.click()
try:
#WebDriverWait(driver, 5, 0.5).until(EC.presence_of_element_located(locator))
break
except:
pass
#return 0
set_id_att(driver, 'ts', 'innerHTML', i)
time.sleep(1)
headers = getheader(driver)#获取headers
ip = "202.121.178.244"
if headers:
#获取cookie并存入headers中
cookie = [item["name"] + "=" + item["value"] for item in driver.get_cookies()]
headers['cookie'] = ';'.join(item for item in cookie)
del headers[':authority']
del headers[':method']
del headers[':path']
del headers[':scheme']
headers['X-Forwarded-For'] = ip
headers['X-Remote-IP'] = ip
headers['X-Originating-IP'] = ip
headers['X-Remote-Addr'] = ip
headers['X-Client-IP'] = ip
return headers
headers=login()#自动登录并获取登录后的Headers包括cookies
要获取完整项目代码(selenium模拟登录企查查+requests库自动搜索获取指定信息并保存Excel)请关注上面的公众号“python客栈”然后回复“qcc”
本文主要介绍了如何使用python的selenium模拟登录企查查,主要介绍了如何使用selenium保存Cookies与headers、自动验证及selenium库对页面元素的一些操作方法
下一篇将介绍Python使用requests库自动在企查查上搜索相关企业并获取指定信息
相关推荐
-

利用Python实现学生信息管理系统的完整实例
项目要求: 读完题目,首先我们要确定程序思路 我们要全部通过类去实现 也就是 我们要实现管理员.学生.讲师.课程.教师五个类 管理员类 class Administration(object): def __init__(self): self.data = self.__load() self.login_data = {} def __load(self) -> list: try: Adm = open('Administration.csv', 'r') readers = csv.Di
-
python实现学生信息管理系统源码
本文实例为大家分享了python实现学生信息管理系统的具体代码,供大家参考,具体内容如下 代码如下: Project.py文件内容: class Student(object): # 建立学生信息储存的列表(嵌套的方式) studentInformation = [] # 对学生对象的数据进行说明 studentShow = ["学号:", "姓名:", "年龄:"] # 录入学生 def addstudent(self): sno = inpu
-
python中的被动信息搜集
概述: 被动信息搜集主要通过搜索引擎或者社交等方式对目标资产信息进行提取,通常包括IP查询,Whois查询,子域名搜集等.进行被动信息搜集时不与目标产生交互,可以在不接触到目标系统的情况下挖掘目标信息. 主要方法:DNS解析,子域名挖掘,邮件爬取等. DNS解析: 1.概述: DNS(Domain Name System,域名系统)是一种分布式网络目录服务,主要用于域名与IP地址的相互转换,能够使用户更方便地访问互联网,而不用去记住一长串数字(能够被机器直接读取的IP). 2.IP查询: IP查
-
基于python制作简易版学生信息管理系统
一.前言 本篇博客对于文件操作.字典.列表.匿名函数以及sort()等内置函数进行了系统的整理操作,以设计一个学生信息管理系统的形式展示,具体概念方法等会在代码后进行分析讲述,请读者仔细分析每一处解析,对于基础巩固将会有很大的帮助,其中还有每一块代码的设计思路图,逻辑分析会有一定的提升. 二.需求分析 本程序需要用到os模板首先导入,并命名要存储信息的文件 import os File_Object_Name = 'Student_Inforation.txt' 三.主函数 def Main()
-
用python爬虫爬取CSDN博主信息
一.项目介绍 爬取网址:CSDN首页的Python.Java.前端.架构以及数据库栏目.简单分析其各自的URL不难发现,都是https://www.csdn.net/nav/+栏目名样式,这样我们就可以爬取不同栏目了. 以Python目录页为例,如下图所示: 爬取内容:每篇文章的博主信息,如博主姓名.码龄.原创数.访问量.粉丝数.获赞数.评论数.收藏数 (考虑到周排名.总排名.积分都是根据上述信息综合得到的,对后续分析没实质性的作用,这里暂不爬取.) 不想看代码的朋友可直接跳到第三部分~ 二.S
-
Python爬取OPGG上英雄联盟英雄胜率及选取率信息的操作
本次爬取网站为opgg,网址为:" http://www.op.gg/champion/statistics" 由网站界面可以看出,右侧有英雄的详细信息,以Garen为例,胜率为53.84%,选取率为16.99%,常用位置为上单 现对网页源代码进行分析(右键鼠标在菜单中即可找到查看网页源代码).通过查找"53.84%"快速定位Garen所在位置 由代码可看出,英雄名.胜率及选取率都在td标签中,而每一个英雄信息在一个tr标签中,td父标签为tr标签,tr父标签为tb
-
python 获取计算机的网卡信息
0. 前言 正常情况下,如果想要查看电脑的网卡IP地址或是MAC地址,直接通过界面找到网卡进行查看就有了,亦或是通过命令如linux的ifconfig得到IP等信息,那么本节教大家如何通过python的方式获取网卡的IP/MAC信息. 1. 测试环境及关键代码解释 1.1 测试环境 1.1.1 系统: Ubuntu 16.04.6 LTS Windows 10 x64 1.1.2 开发工具: pycharm 专业版 备注:专业版支持本地远程linux调试. 2. 模块介绍及演示 本次只需要用到3
-
python批量提取图片信息并保存的实现
程序运行环境 code # -*- coding:utf-8 -*- # ----------------------------------- # @Time : 2021/2/3 9:23 # @Author : HaoWu # @File : OutPixel.py # ------------------------------------ import sys import os from glob import glob from PIL import Image sys.path.
-
Python爬虫之爬取二手房信息
前言 说到二手房信息,不知道你们心里最先跳出来的公司(网站)是什么,反正我心里第一个跳出来的是网站是 58 同城.哎呦,我这暴脾气,想到就赶紧去干. 但很显然,我失败了.说显然,而不是不幸,这是因为 58 同城是大公司,我这点本事爬不了数据是再正常不过的了.下面来看看 58 同城的反爬手段了.这是我爬取下来的网页源码. 我们看到爬取下来的源码有很多英文大写字母和数字是网页源码中没有的,后来我了解到 58 同城对自己的网站的源码进行了文本加密,所以就出现了我爬取到的情况. 爬取二手房信息 我打开
-
使用python实现学生信息管理系统
本文实例为大家分享了python实现学生信息管理系统的具体代码,供大家参考,具体内容如下 学生管理系统的开发步骤: 1.显示学生管理系统的功能菜单 2.接收用户输入的功能选项 3.判断用户输入的功能选项,并完成相关的操作 把功能代码抽取到函数的目的:提供功能代码的复用性,减少功能代码的冗余. # 学生列表,专门来负责管理每一个学生信息 student_list = [] # 显示学生管理系统菜单的功能函数 def show_menu(): print("=================== 学
-
Python如何利用正则表达式爬取网页信息及图片
一.正则表达式是什么? 概念: 正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符.及这些特定字符的组合,组成一个"规则字符串",这个"规则字符串"用来表达对字符串的一种过滤逻辑. 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. 个人理解: 简单来说就是使用正则表达式来写一个过滤器来过滤了掉杂乱的无用的信息(eg:网页源代码-)从中来获取自己想要的内容 二.实战项目 1.爬取内容 获取上海所有三甲医院的名称并保