Python学习笔记之线程
目录
- 1.自定义进程
- 2.进程与线程
- 3.多线程
- 4.Thread类方法
- 5.多线程与多进程小Case
- 6.Thread 的生命周期
- 7.自定义线程
- 8.线程共享数据与GIL(全局解释器锁)
- 9.GIL 和 Lock
- 10.线程的信号量
- 总结
1.自定义进程
自定义进程类,继承Process类,重写run方法(重写Process的run方法)。
from multiprocessing import Process
import time
import os
class MyProcess(Process):
def __init__(self, name): ##重写,需要__init__,也添加了新的参数。 ##Process.__init__(self) 不可以省略,否则报错:AttributeError:'XXXX'object has no attribute '_colsed'
Process.__init__(self)
self.name = name
def run(self):
print("子进程(%s-%s)启动" % (self.name, os.getpid()))
time.sleep(3)
print("子进程(%s-%s)结束" % (self.name, os.getpid()))
if __name__ == '__main__':
print("父进程启动")
p = MyProcess("Ail")
# 自动调用MyProcess的run()方法
p.start()
p.join()
print("父进程结束")
# 输出结果
父进程启动
子进程(Ail-38512)启动
子进程(Ail-38512)结束
父进程结束
2.进程与线程
多进程适合在CPU密集型操作(CPU操作指令比较多,如科学计算、位数多的浮点计算);
多线程适合在IO密集型操作(读写数据操作比较多的,比如爬虫、文件上传、下载)
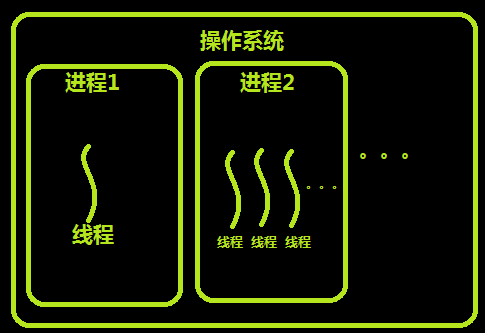
线程是并发,进程是并行:进程之间互相独立,是系统分配资源的最小单位,同一个进程中的所有线程共享资源。
进程:一个运行的程序或代码就是一个进程,一个没有运行的代码叫程序。进程是系统进行资源分配的最小单位,进程拥有自己的内存空间,所以,进程间数据不共享,开销大。
进程是程序的一次动态执行过程。每个进程都拥有自己的地址空间、内存、数据栈以及其它用于跟踪执行的辅助数据。操作系统负责其上所有进程的执行,操作系统会为这些进程合理地分配执行时间。
线程:调度执行的最小单位,也叫执行路径,不能独立存在,依赖进程的存在而存在,一个进程至少有一个线程,叫做主线程,多个线程共享内存(数据共享和全局变量),因此提升程序的运行效率。
线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。一个线程是一个execution context(执行上下文),即一个CPU执行时所需要的一串指令。
主线程:主线程就是创建线程进程中产生的第一个线程,也就是main函数对应的线程。
协程:用户态的轻量级线程,调度由用户控制,拥有自己的寄存器上下文和栈,切换基本没有内核切换的开销,切换灵活。
进程和线程的关系
3.多线程
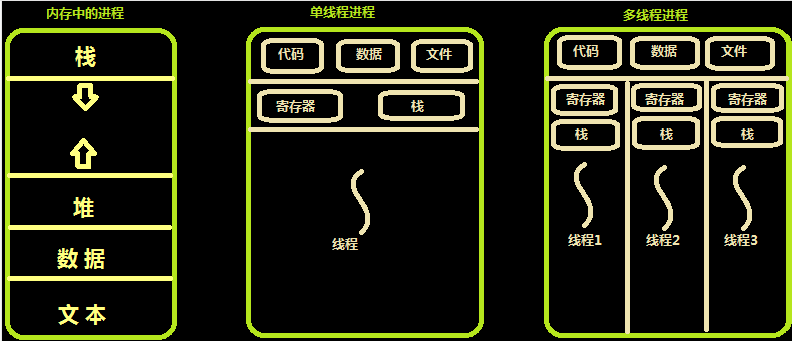
操作系统通过给不同的线程分配时间片(CPU运行时长)来调度线程,当CPU执行完一个线程的时间片后就会快速切换到下一个线程,时间片很短而且切换速度很快,以至于用户根本察觉不到。多个线程根据分配的时间片轮流被CPU执行,如今绝大多数计算机的CPU都是多核的,多个线程在操作系统的调度下,能够被多个CPU并行执行,程序的执行速度和CPU的利用效率大大提升。绝大对数主流的编程语言都能很好地支持多线程,然而,Python由于GIL锁无法实现真正的多线程。
内存中的线程
4.Thread类方法
(1)start() --开始执行该线程;
(2)run() --定义线程的方法(开发者可以在子类中重写);标准的 run() 方法会对作为 target 参数传递给该对象构造器的可调用对象(如果存在)发起调用,并附带从 args 和 kwargs 参数分别获取的位置和关键字参数。
(3)join(timeout=None) --直至启动的线程终止之前一直挂起;除非给出了timeout(单位秒),否则一直被阻塞;因为 join() 总是返回 None ,所以要在 join() 后调用 is_alive() 才能判断是否发生超时 -- 如果线程仍然存活,则 join() 超时。一个线程可以被 join() 很多次。如果尝试加入当前线程会导致死锁, join() 会引起 RuntimeError 异常。如果尝试 join() 一个尚未开始的线程,也会抛出相同的异常。
(4)is_alive() --布尔值,表示这个线程是否还存活;当 run() 方法刚开始直到 run() 方法刚结束,这个方法返回 True 。
(5)threading.current_thread()--返回当前对应调用者的控制线程的 Thread 对象。例如,获取当前线程的名字,可以是current_thread().name。
5.多线程与多进程小Case
from threading import Thread
from multiprocessing import Process
import os
def work():
print('hello,',os.getpid())
if __name__ == '__main__':
# 在主进程下开启多个线程,每个线程都跟主进程的pid一样
t1 = Thread(target=work) # 开启一个线程
t2 = Thread(target=work) # 开启两个线程
t1.start() ##start()--It must be called at most once per thread object.It arranges for the object's run() method to be ## invoked in a separate thread of control.This method will raise a RuntimeError if called more than once on the ## same thread object.
t2.start()
print('主线程/主进程pid', os.getpid())
# 开多个进程,每个进程都有不同的pid
p1 = Process(target=work)
p2 = Process(target=work)
p1.start()
p2.start()
print('主线程/主进程pid',os.getpid())
6.Thread 的生命周期
线程的状态包括:创建、就绪、运行、阻塞、结束。
(1)创建对象时,代表 Thread 内部被初始化;
(2) 调用 start() 方法后,thread 会开始进入队列准备运行,在未获得CPU、内存资源前,称为就绪状态;轮询获取资源,进入运行状态;如果遇到sleep,则是进入阻塞状态;
(3) thread 代码正常运行结束或者是遇到异常,线程会终止。
7.自定义线程
(1)定义一个类,继承Thread;
(2)重写__init__ 和 run();
(3)创建线程类对象;
(4)启动线程。
import time
import threading
class MyThread(threading.Thread):
def __init__(self,num):
super().__init__() ###或者是Thread.__init__()
self.num = num
def run(self):
print('线程名称:', threading.current_thread().getName(), '参数:', self.num, '开始时间:', time.strftime('%Y-%m-%d %H:%M:%S'))
if __name__ == '__main__':
print('主线程开始:',time.strftime('%Y-%m-%d %H:%M:%S'))
t1 = MyThread(1)
t2 = MyThread(2)
t1.start()
t2.start()
t1.join()
t2.join()
print('主线程结束:', time.strftime('%Y-%m-%d %H:%M:%S'))
8.线程共享数据与GIL(全局解释器锁)
如果是全局变量,则每个线程是共享的;
GIL锁:可以用篮球比赛的场景来模拟,把篮球场看作是CPU,一场篮球比赛看作是一个线程,如果只有一个篮球场,多场比赛就要排队进行,类似于一个简单的单核多线程的程序;如果由多块篮球场,多场比赛同时进行,就是一个简单的多核多线程的程序。然而,Python有着特别的规定:每场比赛必须要在裁判的监督之下才允许进行,而裁判只有一个。这样不管你有几块篮球场,同一时间只允许有一个场地进行比赛,其它场地都将被闲置,其它比赛都只能等待。
9.GIL 和 Lock
GIL保证同一时间内一个进程可以有多个线程,但只有一个线程在执行;锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据。
类为threading.Lock
它有两个基本方法, acquire() 和 release() 。
当状态为非锁定时, acquire() 将状态改为 锁定 并立即返回。当状态是锁定时, acquire() 将阻塞至其他线程调用 release() 将其改为非锁定状态,然后 acquire() 调用重置其为锁定状态并返回。
release() 只在锁定状态下调用; 它将状态改为非锁定并立即返回。如果尝试释放一个非锁定的锁,则会引发 RuntimeError 异常。
Caese 如下:
from threading import Thread
from threading import Lock
import time
number = 0
def task(lock):
global number
lock.acquire() ##持有锁
for i in range(100000) number += 1
lock.release() ##释放锁
if __name__ == '__main__':
lock=Lock()
t1 = Thread(target=task,args=(lock,))
t2 = Thread(target=task,args=(lock,)) t3 = Thread(target=task,args=(lock,))
t1.start() t2.start() t3.start() t1.join() t2.join() t3.join() print('number:',number)
10.线程的信号量
class threading.Semaphore([values])
values是一个内部计数,values默认是1,如果小于0,则会抛出 ValueError 异常,可以用于控制线程数并发数。
信号量的实现方式:
s=Semaphore(?)
在内部有一个counter计数器,counter的值就是同一时间可以开启线程的个数。每当我们s.acquire()一次,计数器就进行减1处理,每当我们s.release()一次,计数器就会进行加1处理,当计数器为0的时候,其它的线程就处于等待的状态。
程序添加一个计数器功能(信号量),限制一个时间点内的线程数量,防止程序崩溃或其它异常。
Case
import time
import threading
s=threading.Semaphore(5) #添加一个计数器
def task():
s.acquire() #计数器获得锁
time.sleep(2) #程序休眠2秒
print("The task run at ",time.ctime())
s.release() #计数器释放锁
for i in range(40):
t1=threading.Thread(target=task,args=()) #创建线程
t1.start() #启动线程
也可以使用with操作,替代acquire ()和release(),上面的代码调整如下:
import time
import threading
s=threading.Semaphore(5) #添加一个计数器
def task(): with s: ## 类似打开文件的with操作
##s.acquire() #计数器获得锁
time.sleep(2) #程序休眠2秒
print("The task run at ",time.ctime())
##s.release() #计数器释放锁
for i in range(40):
t1=threading.Thread(target=task,args=()) #创建线程
t1.start() #启动线程
建议使用with。
总结
本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
Python并发编程线程消息通信机制详解
目录 1 Event事件 2 Condition 3 Queue队列 4 总结一下 前面我已经向大家介绍了,如何使用创建线程,启动线程.相信大家都会有这样一个想法,线程无非就是创建一下,然后再start()下,实在是太简单了. 可是要知道,在真实的项目中,实际场景可要我们举的例子要复杂的多得多,不同线程的执行可能是有顺序的,或者说他们的执行是有条件的,是要受控制的.如果仅仅依靠前面学的那点浅薄的知识,是远远不够的. 那今天,我们就来探讨一下如何控制线程的触发执行. 要实现对多个线程进行控制,其实
-
Python 多线程超详细到位总结
目录 多线程threading 线程池 线程互斥 lock与Rlock的区别 在实际处理数据时,因系统内存有限,我们不可能一次把所有数据都导出进行操作,所以需要批量导出依次操作.为了加快运行,我们会采用多线程的方法进行数据处理,以下为我总结的多线程批量处理数据的模板: import threading # 从数据库提取数据的类 class Scheduler(): def __init__(self): self._lock = threading.RLock() self.start = 0
-

python 多线程与多进程效率测试
目录 1.概述 2.代码练习 3.运行结果 1.概述 在Python中,计算密集型任务适用于多进程,IO密集型任务适用于多线程 正常来讲,多线程要比多进程效率更高,因为进程间的切换需要的资源和开销更大,而线程相对更小,但是我们使用的Python大多数的解释器是Cpython,众所周知Cpython有个GIL锁,导致执行计算密集型任务时多线程实际只能是单线程,而且由于线程之间切换的开销导致多线程往往比实际的单线程还要慢,所以在 python 中计算密集型任务通常使用多进程,因为各个进程有各自独立的
-
Python 多线程处理任务实例
目录 美餐每天发一个用Excel汇总的就餐数据,我们把它导入到数据库后,行政办公服务用它和公司内的就餐数据进行比对查重. 初始实现是单线程,和import_records去掉多线程后的部分差不多. 读取Excel数据 -> 发送到行政服务接口 安全起见线上操作放在了晚上进行.运行时发现每条数据导入消耗1s多,晚上十点开始跑这几千条数据想想都让人崩溃. 等着也是干等,下楼转两圈透透气,屋里龌龊的空气让人昏昏沉沉,寒冷让人清醒不少,突然想到为什么不用多线程呢? 第一版多线程和处理业务的程序糅合在了一
-
Python进阶多线程爬取网页项目实战
目录 一.网页分析 二.代码实现 一.网页分析 这次我们选择爬取的网站是水木社区的Python页面 网页:https://www.mysmth.net/nForum/#!board/Python?p=1 根据惯例,我们第一步还是分析一下页面结构和翻页时的请求. 通过前三页的链接分析后得知,每一页链接中最后的参数是页数,我们修改它即可得到其他页面的数据. 再来分析一下,我们需要获取帖子的链接就在id 为 body 的 section下,然后一层一层找到里面的 table,我们就能遍历这些链接的标题
-
Python学习笔记之线程
目录 1.自定义进程 2.进程与线程 3.多线程 4.Thread类方法 5.多线程与多进程小Case 6.Thread 的生命周期 7.自定义线程 8.线程共享数据与GIL(全局解释器锁) 9.GIL 和 Lock 10.线程的信号量 总结 1.自定义进程 自定义进程类,继承Process类,重写run方法(重写Process的run方法). from multiprocessing import Process import time import os class MyProcess(Pr
-
Python学习笔记整理3之输入输出、python eval函数
1. python中的变量: python中的变量声明不需要像C++.Java那样指定变量数据类型(int.float等),因为python会自动地根据赋给变量的值确定其类型.如 radius = 20,area = radius * radius * 3.14159 ,python会自动的将radius看成"整型",area看成"浮点型".所以编程时不用再像之前那样小心翼翼的查看数据类型有没有出错,挺人性化的. 2. input和print: 先贴个小的程序 #
-
快速入门python学习笔记
本篇不是教给大家如何去学习python,有需要详细深入学习的朋友可以参阅:Python基础语言学习笔记总结(精华)本文通过一周快速学习python入门知识总计了学习笔记和心得,分享给大家. ##一:语法元素 ###1.注释,变量,空格的使用 注释 单行注释以#开头,多行注释以''开头和结尾 变量 变量前面不需要声明数据类型,但是必须赋值 变量命名可以使用大小写字母,数字和下划线的组合,但是首字母只能是大小写字母或者下划线,不能使用空格 中文等非字母符号也可以作为名字 空格的使用 表示缩进关系的空
-
Python学习笔记之pandas索引列、过滤、分组、求和功能示例
本文实例讲述了Python学习笔记之pandas索引列.过滤.分组.求和功能.分享给大家供大家参考,具体如下: 解析html内容,保存为csv文件 //www.jb51.net/article/162401.htm 前面我们已经把519961(基金编码)这种基金的历史净值明细表html内容抓取到了本地,现在我们还是需要 解析html,取出相关的值,然后保存为csv文件以便pandas来统计分析. from bs4 import BeautifulSoup import os import csv
-
Python学习笔记之读取文件、OS模块、异常处理、with as语法示例
本文实例讲述了Python学习笔记之读取文件.OS模块.异常处理.with as语法.分享给大家供大家参考,具体如下: 文件读取 #读取文件 f = open("test.txt","r") print(f.read()) #打印文件内容 #关闭文件 f.close() 获取文件绝对路径:OS模块 os.environ["xxx"] 获取系统环境变量 os.getcwd 获取当前python脚本工作路径 os.getpid() 获取当前进程ID
-
Python学习笔记之自定义函数用法详解
本文实例讲述了Python学习笔记之自定义函数用法.分享给大家供大家参考,具体如下: 函数能提高应用的模块性,和代码的重复利用率.Python提供了许多内建函数,比如print()等.也可以创建用户自定义函数. 函数定义 函数定义的简单规则: 函数代码块以def关键词开头,后接函数标识符名称和圆括号(),任何传入参数和自变量必须放在圆括号中间 函数内容以冒号起始,并且缩进 若有返回值,Return[expression] 结束函数:不带return 表达式相当于返回None 函数通常使用三个单引
-
Python学习笔记基本数据结构之序列类型list tuple range用法分析
本文实例讲述了Python学习笔记基本数据结构之序列类型list tuple range用法.分享给大家供大家参考,具体如下: list 和 tuple list:列表,由 [] 标识: 有序:可改变列表元素 tuple:元组,由 () 标识: 有序:不可改变元组元素(和list的主要区别) list 和 tuple 的创建: print([]) # 空list print(["a",1,True]) # 元素类型不限 print([x for x in range(0,6)]) #
-
Python学习笔记之Django创建第一个数据库模型的方法
Django里面集成了SQLite的数据库,对于初期研究来说,可以用这个学习. 第一步,创建数据库就涉及到建表等一系列的工作,在此之前,要先在cmd执行一个命令: python manage.py migrate 这个命令就看成一个打包安装的命令,它会根据mysite/settings.py的配置安装一系列必要的数据库表 第二步,我们要建立一个Model层,修改demo/model.py: from django.db import models classQuestion(models.Mod
-
Python学习笔记之lambda表达式用法详解
本文实例讲述了Python学习笔记之lambda表达式用法.分享给大家供大家参考,具体如下: Lambda 表达式 使用 Lambda 表达式创建匿名函数,即没有名称的函数.lambda 表达式非常适合快速创建在代码中以后不会用到的函数. 麻烦的写法: def multiply(x, y): return x * y 使用Lambda之后: double = lambda x, y: x * y Lambda 函数的组成部分: 关键字 lambda 表示这是一个 lambda 表达式. lamb
-
Python学习笔记之迭代器和生成器用法实例详解
本文实例讲述了Python学习笔记之迭代器和生成器用法.分享给大家供大家参考,具体如下: 迭代器和生成器 迭代器 每次可以返回一个对象元素的对象,例如返回一个列表.我们到目前为止使用的很多内置函数(例如 enumerate)都会返回一个迭代器. 是一种表示数据流的对象.这与列表不同,列表是可迭代对象,但不是迭代器,因为它不是数据流. 生成器 是使用函数创建迭代器的简单方式.也可以使用类定义迭代器 下面是一个叫做 my_range 的生成器函数,它会生成一个从 0 到 (x - 1) 的数字流: