python机器学习创建基于规则聊天机器人过程示例详解
目录
- 聊天机器人
- 基于规则的聊天机器人
- 创建语料库
- 创建一个聊天机器人
- 总结
还记得这个价值一个亿的AI核心代码?
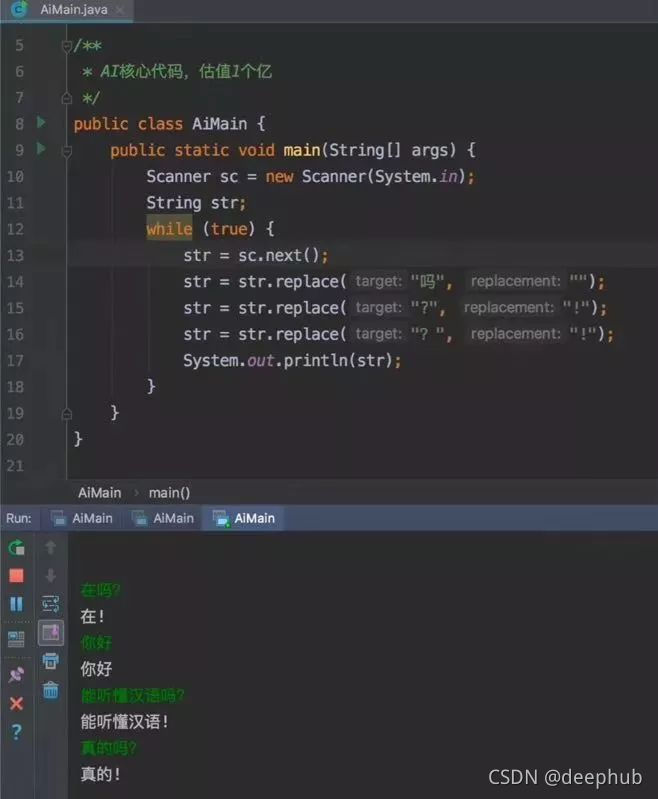
while True:
AI = input('我:')
print(AI.replace("吗", " ").replace('?','!').replace('?','!'))
以上这段代码就是我们今天的主题,基于规则的聊天机器人
聊天机器人
聊天机器人本身是一种机器或软件,它通过文本或句子模仿人类交互。 简而言之,可以使用类似于与人类对话的软件进行聊天。
为什么要尝试创建聊天机器人? 也许你对一个新项目感兴趣,或者公司需要一个,或者想去拉投资。 无论动机是什么,本文都将尝试解释如何创建一个简单的基于规则的聊天机器人。
基于规则的聊天机器人
什么是基于规则的聊天机器人?它是一种基于特定规则来回答人类给出的文本的聊天机器人。由于它基于强加的规则所以这个聊天机器人生成的响应几乎是准确的;但是,如果我们收到与规则不匹配的查询,聊天机器人将不会回答。与它相对的另一个版本是基于模型的聊天机器人,它通过机器学习模型来回答给定的查询。(二者的区别就是基于规则的需要我们指定每一条规则,而且基于模型的会通过训练模型自动生成规则,还记得我们上一篇的”机器学习介绍“吗,“机器学习为系统提供无需明确编程就能根据经验自动学习和改进的能力。”)
基于规则的聊天机器人可能基于人类给出的规则,但这并不意味着我们不使用数据集。聊天机器人的主要目标仍然是自动化人类提出的问题,所以我们还是需要数据来制定特定的规则。
在本文中,我们将利用余弦相似距离作为基础开发基于规则的聊天机器人。余弦相似度是向量(特别是内积空间的非零向量)之间的相似度度量,常用于度量两个文本之间的相似度。
我们将使用余弦相似度创建一个聊天机器人,通过对比查询与我们开发的语料库之间的相似性来回答查询提出的问题。这也是我们最初需要开发我们的语料库的原因。
创建语料库
对于这个聊天机器人示例,我想创建一个聊天机器人来回答有关猫的所有问题。 为了收集关于猫的数据,我会从网上抓取它。
import bs4 as bs
import urllib.request#Open the cat web data page
cat_data = urllib.request.urlopen('https://simple.wikipedia.org/wiki/Cat').read()
#Find all the paragraph html from the web page
cat_data_paragraphs = bs.BeautifulSoup(cat_data,'lxml').find_all('p')
#Creating the corpus of all the web page paragraphs
cat_text = ''
#Creating lower text corpus of cat paragraphs
for p in cat_data_paragraphs:
cat_text += p.text.lower()
print(cat_text)

使用上面的代码,会得到来自wikipedia页面的段落集合。 接下来,需要清理文本以去除括号编号和空格等无用的文本。
import re cat_text = re.sub(r'\s+', ' ',re.sub(r'\[[0-9]*\]', ' ', cat_text))
上述代码将从语料库中删除括号号。我特意没有去掉这些符号和标点符号,因为当与聊天机器人进行对话时,这样听起来会很自然。
最后,我将根据之前创建的语料库创建一个句子列表。
import nltk cat_sentences = nltk.sent_tokenize(cat_text)

我们的规则很简单:将聊天机器人的查询文本与句子列表中的每一个文本之间的进行余弦相似性的度量,哪个结果产生的相似度最接近(最高余弦相似度)那么它就是我们的聊天机器人的答案。
创建一个聊天机器人
我们上面的语料库仍然是文本形式,余弦相似度不接受文本数据;所以需要将语料库转换成数字向量。通常的做法是将文本转换为词袋(单词计数)或使用TF-IDF方法(频率概率)。在我们的例子中,我们将使用TF-IDF。
我将创建一个函数,它接收查询文本,并根据以下代码中的余弦相似性给出一个输出。
让我们看一下代码。
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.feature_extraction.text import TfidfVectorizer
def chatbot_answer(user_query):
#Append the query to the sentences list
cat_sentences.append(user_query)
#Create the sentences vector based on the list
vectorizer = TfidfVectorizer()
sentences_vectors = vectorizer.fit_transform(cat_sentences)
#Measure the cosine similarity and take the second closest index because the first index is the user query
vector_values = cosine_similarity(sentences_vectors[-1], sentences_vectors)
answer = cat_sentences[vector_values.argsort()[0][-2]]
#Final check to make sure there are result present. If all the result are 0, means the text input by us are not captured in the corpus
input_check = vector_values.flatten()
input_check.sort()
if input_check[-2] == 0:
return "Please Try again"
else:
return answer
我们可以把上面的函数使用下面的流程图进行表示:

最后,使用以下代码创建一个简单的回答交互。
print("Hello, I am the Cat Chatbot. What is your meow questions?:")
while(True):
query = input().lower()
if query not in ['bye', 'good bye', 'take care']:
print("Cat Chatbot: ", end="")
print(chatbot_answer(query))
cat_sentences.remove(query)
else:
print("See You Again")
break
上面的脚本将接收查询,并通过我们之前开发的聊天机器人处理它们。

从上面的图片中看到的,结果还是可以接受的,但有也有些奇怪的回答。但是我们要想到,目前只从一个数据源中得到的结果,并且也没有做任何的优化。如果我们用额外的数据集和规则来改进它,它肯定会更好地回答问题。
总结
聊天机器人项目是一个令人兴奋的数据科学项目,因为它在许多领域都有帮助。在本文中,我们使用从网页中获取的数据,利用余弦相似度和TF-IDF,用Python创建了一个简单的聊天机器人项目,真正的将我们的1个亿的项目落地。其实这里面还有很多的改进:
向量化的选择,除了TF-IDF还可以使用word2vec,甚至使用预训练的bert提取词向量。
回答环节,其实就是通过某种特定的算法或者规则从我们的语料库中搜索最匹配的答案,本文中使用的相似度top1的方法其实就是一个最简单的类greedsearch的方法,对于答案结果的优化还可以使用类beamsearch 的算法提取回答的匹配项。
等等很多
在端到端的深度学习兴起之前,很多的聊天机器人都是这样基于规则来运行的并且也有很多落地案例,如果你想快速的做一个POC展示,这种基于规则方法还是非常有用的。
方法,对于答案结果的优化还可以使用类beamsearch 的算法提取回答的匹配项。
等等很多
在端到端的深度学习兴起之前,很多的聊天机器人都是这样基于规则来运行的并且也有很多落地案例,如果你想快速的做一个POC展示,这种基于规则方法还是非常有用的。
以上就是python实现基于规则聊天机器人过程示例详解的详细内容,更多关于python实现基于规则聊天机器人的资料请关注我们其它相关文章!
相关推荐
-

Python实现聊天机器人的示例代码
一.AIML是什么 AIML全名为Artificial Intelligence Markup Language(人工智能标记语言),是一种创建自然语言软件代理的XML语言,是由RichardS. Wallace 博士和Alicebot开源软件组织于1995-2000年间发明创造的.AIML是一种为了匹配模式和确定响应而进行规则定义的 XML 格式. 二.实现第一个聊天机器人 (一)安装Python aiml库 pip install aiml (二)获取alice资源 Python aiml安
-
基于Python如何使用AIML搭建聊天机器人
借助 Python 的 AIML 包,我们很容易实现人工智能聊天机器人.AIML,全名为Artificial Intelligence Markup Language(人工智能标记语言),是一种创建自然语言软件代理的XML语言,是由Richard Wallace和世界各地的自由软件社区在1995年至2002年发明的. AIML 是什么? AIML由Richard Wallace发明.他设计了一个名为 A.L.I.C.E. (Artificial Linguistics Internet Comp
-
Python如何实现机器人聊天
今天午休的时候,无意之中看了一篇博客,名字叫Python实现机器人,感觉挺有的意思的. 于是用其写了一个简单的Python聊天,源码如下所示: # -*- coding: utf-8 -*- import aiml import sys import os def get_module_dir(name): print("module", sys.modules[name]) path = getattr(sys.modules[name], '__file__', None) pri
-
使用Python AIML搭建聊天机器人的方法示例
AIML全名为Artificial Intelligence Markup Language(人工智能标记语言),是一种创建自然语言软件代理的XML语言,是由RichardS. Wallace 博士和Alicebot开源软件组织于1995-2000年间发明创造的.AIML是一种为了匹配模式和确定响应而进行规则定义的 XML 格式. AIML的设计目标如下: AIML应当为大众所易学易会. AIML应当使最小的概念得以编码使之基于L.I.C.E支持一种刺激-响应学科系统组件. AIML应当兼容XM
-
教你用Python创建微信聊天机器人
最近研究微信API,发现个非常好用的python库:wxpy.wxpy基于itchat,使用了 Web 微信的通讯协议,实现了微信登录.收发消息.搜索好友.数据统计等功能. 这里我们就来介绍一下这个库,并在最后实现一个聊天机器人. 有没有很兴奋?有没有很期待? 好了,接下来,开始我们的正题. 准备工作 安装非常简单,从官方源下载安装 pip install -U wxpy 或者从豆瓣源安装 pip install -U wxpy -i "https://pypi.doubanio.com/sim
-
python机器学习创建基于规则聊天机器人过程示例详解
目录 聊天机器人 基于规则的聊天机器人 创建语料库 创建一个聊天机器人 总结 还记得这个价值一个亿的AI核心代码? while True: AI = input('我:') print(AI.replace("吗", " ").replace('?','!').replace('?','!')) 以上这段代码就是我们今天的主题,基于规则的聊天机器人 聊天机器人 聊天机器人本身是一种机器或软件,它通过文本或句子模仿人类交互. 简而言之,可以使用类似于与人类对话的软件进
-
Python程序包的构建和发布过程示例详解
关于我 编程界的一名小程序猿,目前在一个创业团队任team lead,技术栈涉及Android.Python.Java和Go,这个也是我们团队的主要技术栈. 联系:hylinux1024@gmail.com 当我们开发了一个开源项目时,就希望把这个项目打包然后发布到 pypi.org 上,别人就可以通过 pip install 的命令进行安装.本文的教程来自于 Python 官方文档 , 如有不正确的地方欢迎评论拍砖. 0x00 创建项目 本文使用到的项目目录为 ➜ packaging-tuto
-
利用Python打造一个多人聊天室的示例详解
一.实验名称 建立聊天工具 二.实验目的 掌握Socket编程中流套接字的技术,实现多台电脑之间的聊天. 三.实验内容和要求 vii.掌握利用Socket进行编程的技术 viii.必须掌握多线程技术,保证双方可以同时发送 ix.建立聊天工具 x.可以和多个人同时进行聊天 xi.必须使用图形界面,显示双方的语录 四.实验环境 PC多台,操作系统Win7,win10(32位.64位) 具备软件python3.6 . 五.操作方法与实验步骤 服务端 1.调入多线程.与scoket包,用于实现多线程连接
-
python中前缀运算符 *和 **的用法示例详解
这篇主要探讨 ** 和 * 前缀运算符,**在变量之前使用的*and **运算符. 一个星(*):表示接收的参数作为元组来处理 两个星(**):表示接收的参数作为字典来处理 简单示例: >>> numbers = [2, 1, 3, 4, 7] >>> more_numbers = [*numbers, 11, 18] >>> print(*more_numbers, sep=', ') 2, 1, 3, 4, 7, 11, 18 用途: 使用 * 和
-
Python爬虫之爬取淘女郎照片示例详解
本篇目标 抓取淘宝MM的姓名,头像,年龄 抓取每一个MM的资料简介以及写真图片 把每一个MM的写真图片按照文件夹保存到本地 熟悉文件保存的过程 1.URL的格式 在这里我们用到的URL是 http://mm.taobao.com/json/request_top_list.htm?page=1,问号前面是基地址,后面的参数page是代表第几页,可以随意更换地址.点击开之后,会发现有一些淘宝MM的简介,并附有超链接链接到个人详情页面. 我们需要抓取本页面的头像地址,MM姓名,MM年龄,MM居住地,
-
JS实现一个微信录音功能过程示例详解
目录 功能原型图 拆解需求 评估时间 代码实现 功能原型图 其实就是微信发送语音的功能.没有转文字的功能. 拆解需求 根据原型图可以很容易的得出我们需要做的内容包括下面三个部分: 接入微信的语音SDK 调用微信SDK的API逻辑 界面和交互的实现 其中第一点和第二点属于业务逻辑部分,第三点属于交互逻辑部分.对于业务逻辑和交互逻辑的关系在我的另外一篇文章描述过,我在vue中是这样拆分组件的 从原型图可以分析出如下的流程图: 评估时间 第三事情是评估时间.在接到这个需求的时候,我们需要假设我们在此之
-
微信小程序之高德地图多点路线规划过程示例详解
调用 如何调用高德api? 高德官方给出的https://lbs.amap.com/api/wx/summary/开放文档比较详细: 第一步,注册高德开发者 第二部,去控制台创建应用 即点击右上角的控制平台创建应用 创建应用绑定服务记得选择微信小程序:同时在https://lbs.amap.com/api/wx/gettingstarted中下载开发包 第三步,登陆微信公众平台在开发设置中将高德域名配置上 https://restapi.amap.com 第四步,打开微信开发者工具,打开微信小程
-
Python Process创建进程的2种方法详解
前面介绍了使用 os.fork() 函数实现多进程编程,该方法最明显的缺陷就是不适用于 Windows 系统.本节将介绍一种支持 Python 在 Windows 平台上创建新进程的方法. Python multiprocessing 模块提供了 Process 类,该类可用来在 Windows 平台上创建新进程.和使用 Thread 类创建多线程方法类似,使用 Process 类创建多进程也有以下 2 种方式: 直接创建 Process 类的实例对象,由此就可以创建一个新的进程: 通过继承 P
-
Python异步爬虫多线程与线程池示例详解
目录 背景 异步爬虫方式 多线程,多进程(不建议) 线程池,进程池(适当使用) 单线程+异步协程(推荐) 多线程 线程池 背景 当对多个url发送请求时,只有请求完第一个url才会接着请求第二个url(requests是一个阻塞的操作),存在等待的时间,这样效率是很低的.那我们能不能在发送请求等待的时候,为其单独开启进程或者线程,继续请求下一个url,执行并行请求 异步爬虫方式 多线程,多进程(不建议) 好处:可以为相关阻塞的操作单独开启线程或者进程,阻塞操作就可以异步会执行 弊端:不能无限制开
-
Python黑魔法库安装及操作字典示例详解
目录 1. 安装方法 2. 简单示例 3. 兼容字典的所有操作 4. 设置返回默认值 5. 工厂函数自动创建key 6. 序列化的支持 7. 说说局限性 本篇文章收录于<Python黑魔法手册>v3.0 第七章,手册完整版在线阅读地址:Python黑魔法手册 3.0 文档 字典是 Python 中基础的数据结构之一,字典的使用,可以说是非常的简单粗暴,但即便是这样一个与世无争的数据结构,仍然有很多人 "用不惯它" . 也许你并不觉得,但我相信,你看了这篇文章后,一定会和我一