Pandas搭配lambda组合使用详解
导入模块与读取数据
我们第一步需要导入模块以及数据集
import pandas as pd
df = pd.read_csv("IMDB-Movie-Data.csv")
df.head()
创建新的列
一般我们是通过在现有两列的基础上进行一些简单的数学运算来创建新的一列,例如
df['AvgRating'] = (df['Rating'] + df['Metascore']/10)/2
但是如果要新创建的列是经过相当复杂的计算得来的,那么lambda方法就很多必要被运用到了,我们先来定义一个函数方法
def custom_rating(genre,rating):
if 'Thriller' in genre:
return min(10,rating+1)
elif 'Comedy' in genre:
return max(0,rating-1)
elif 'Drama' in genre:
return max(5, rating-1)
else:
return rating
我们对于不同类别的电影采用了不同方式的评分方法,例如对于“惊悚片”,评分的方法则是在“原来的评分+1”和10分当中取一个最小的,而对于“喜剧”类别的电影,则是在0分和“原来的评分-1”当中取一个最大的,然后我们通过apply方法和lambda方法将这个自定义的函数应用在这个DataFrame数据集当中
df["CustomRating"] = df.apply(lambda x: custom_rating(x['Genre'], x['Rating']), axis = 1)
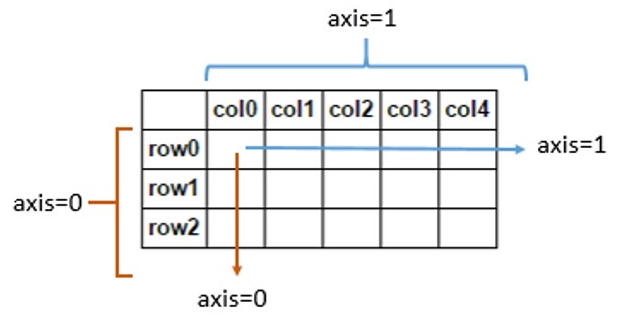
我们这里需要说明一下axis参数的作用,其中axis=1代表跨列而axis=0代表跨行,如下图所示
筛选数据
在pandas当中筛选数据相对来说比较容易,可以用到& | ~这些操作符,代码如下
# 单个条件,评分大于5分的 df_gt_5 = df[df['Rating']>5] # 多个条件: AND - 同时满足评分高于5分并且投票大于100000的 And_df = df[(df['Rating']>5) & (df['Votes']>100000)] # 多个条件: OR - 满足评分高于5分或者投票大于100000的 Or_df = df[(df['Rating']>5) | (df['Votes']>100000)] # 多个条件:NOT - 将满足评分高于5分或者投票大于100000的数据排除掉 Not_df = df[~((df['Rating']>5) | (df['Votes']>100000))]
这些都是非常简单并且是常见的例子,但是要是我们想要筛选出电影的影名长度大于5的部分,要是也采用上面的方式就会报错
df[len(df['Title'].split(" "))>=5]
output
AttributeError: 'Series' object has no attribute 'split'
这里我们还是采用apply和lambda相结合,来实现上面的功能
#创建一个新的列来存储每一影片名的长度
df['num_words_title'] = df.apply(lambda x : len(x['Title'].split(" ")),axis=1)
#筛选出影片名长度大于5的部分
new_df = df[df['num_words_title']>=5]
当然要是大家觉得上面的方法有点繁琐的话,也可以一步到位
new_df = df[df.apply(lambda x : len(x['Title'].split(" "))>=5,axis=1)]
例如我们想要筛选出那些影片的票房低于当年平均水平的数据,可以这么来做。
我们先要对每年票房的的平均值做一个归总,代码如下
year_revenue_dict = df.groupby(['Year']).agg({'Revenue(Millions)':np.mean}).to_dict()['Revenue(Millions)']
然后我们定义一个函数来判断是否存在该影片的票房低于当年平均水平的情况,返回的是布尔值
def bool_provider(revenue, year):
return revenue<year_revenue_dict[year]
然后我们通过结合apply方法和lambda方法应用到数据集当中去
new_df = df[df.apply(lambda x : bool_provider(x['Revenue(Millions)'],x['Year']),axis=1)]
我们筛选数据的时候,主要是用.loc方法,它同时也可以和lambda方法联用,例如我们想要筛选出评分在5-8分之间的电影以及它们的票房,代码如下
df.loc[lambda x: (x["Rating"] > 5) & (x["Rating"] < 8)][["Title", "Revenue (Millions)"]]
转变指定列的数据类型
通常我们转变指定列的数据类型,都是调用astype方法来实现的,例如我们将“Price”这一列的数据类型转变成整型的数据,代码如下
df['Price'].astype('int')
会出现如下所示的报错信息
ValueError: invalid literal for int() with base 10: '12,000'
因此当出现类似“12,000”的数据的时候,调用astype方法实现数据类型转换就会报错,因此我们还需要将到apply和lambda结合进行数据的清洗,代码如下
df['Price'] = df.apply(lambda x: int(x['Price'].replace(',', '')),axis=1)
方法调用过程的可视化
有时候我们在处理数据集比较大的时候,调用函数方法需要比较长的时间,这个时候就需要有一个要是有一个进度条,时时刻刻向我们展示数据处理的进度,就会直观很多了。
这里用到的是tqdm模块,我们将其导入进来
from tqdm import tqdm, tqdm_notebook tqdm_notebook().pandas()
然后将apply方法替换成progress_apply即可,代码如下
df["CustomRating"] = df.progress_apply(lambda x: custom_rating(x['Genre'],x['Rating']),axis=1)
output

当lambda方法遇到if-else
当然我们也可以将if-else运用在lambda自定义函数当中,代码如下
Bigger = lambda x, y : x if(x > y) else y Bigger(2, 10)
output
10
当然很多时候我们可能有多组if-else,这样写起来就有点麻烦了,代码如下
df['Rating'].apply(lambda x:"低分电影" if x < 3 else ("中等电影" if x>=3 and x < 5 else("高分电影" if x>=8 else "值得观看")))
看上去稍微有点凌乱了,这个时候,小编这里到还是推荐大家自定义函数,然后通过apply和lambda方法搭配使用。
到此这篇关于Pandas搭配lambda组合使用详解的文章就介绍到这了,更多相关Python Pandas 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python pandas之多级索引取值详解
目录 数据需求 需求拆解 需求处理 方法一 方法二 总结 最近发现周围的很多小伙伴们都不太乐意使用pandas,转而投向其他的数据操作库,身为一个数据工作者,基本上是张口pandas,闭口pandas了,故而写下此系列以让更多的小伙伴们爱上pandas. 平台: windows 10 python 3.8 pandas 1.2.4 数据需求 给定一份多级索引数据,查找指定值. 需求拆解 数据提取在pandas中,或者说在python中就是索引式提取,在单层索引中采用.loc或.iloc方法已经非
-
python Pandas中数据的合并与分组聚合
目录 一.字符串离散化示例 二.数据合并 2.1 join 2.2 merge 三.数据的分组和聚合 四.索引 总结 一.字符串离散化示例 对于一组电影数据,我们希望统计电影分类情况,应该如何处理数据?(每一个电影都有很多个分类) 思路:首先构造一个全为0的数组,列名为分类,如果某一条数据中分类出现过,就让0变为1 代码: # coding=utf-8 import pandas as pd from matplotlib import pyplot as plt import numpy as
-
python lambda的使用详解
1. lambda语法 lambda argument_list: expression lambda是Python预留的关键字,argument_list(参数列表)和expression(关于参数的表达式)由用户自定义. 2. lambda使用简单示例 lambda x, y: x*y:函数输入是x和y,输出是它们的积x*y lambda:None:函数没有输入参数,输出是None lambda *args: sum(args); 输入是任意个数的参数,输出是它们的和(隐性要求是输入参数必须
-
详解Python的lambda函数用法
lambda函数用法 lambda非常重要的一个定义.lambda在[运行时]才绑定,[不是]在定义的时候绑定.下面这个列子: 本意想:让X分别与0到1的数相加.x+0,x+1,x+2,x+3 实际运行结果是: 0 0 0 0 原因就是上面提到的,运行时才绑定.先运行的for循环,无法捕捉到循环. func = [lambda x: x + n for n in range(4)] # x+n,n是从0到3 For循环,x+0,x+1,x+3 for f in func: print(f(0))
-
Python中使用Lambda函数的5种用法
引言 Lambda 函数(也称为匿名函数)是函数式编程中的核心概念之一. 支持多编程范例的 Python 也提供了一种简单的方法来定义 lambda 函数. 用 Python 编写 lambda 函数的模板是: lambda arguments : expression 它包括三个部分: · Lambda 关键字 · 函数将接收的参数 · 结果为函数返回值的表达式 由于它的简单性,lambda 函数可以使我们的 Python 代码在某些使用场景中更加优雅.这篇文章将演示在 Python 中 la
-
pandas数据的合并与拼接的实现
目录 1. Merge方法 1.1 内连接 1.2 外连接 1.3 左连接 1.4 右连接 1.5 基于多列的连接算法 1.6 基于index的连接方法 2. join方法 3. concat方法 3.1 series类型的拼接方法 3.2 dataframe类型的拼接方法 4. 小结 Pandas包的merge.join.concat方法可以完成数据的合并和拼接,merge方法主要基于两个dataframe的共同列进行合并,join方法主要基于两个dataframe的索引进行合并,concat
-
Python Pandas删除替换并提取其中的缺失值NaN(dropna,fillna,isnull)
目录 前言 Pandas中缺少值NaN的介绍 将缺失值作为Pandas中的缺少值NaN 缺少值NaN的删除方法 删除所有值均缺失的行/列 删除至少包含一个缺失值的行/列 根据不缺少值的元素数量删除行/列 删除特定行/列中缺少值的列/行 pandas.Series 替换(填充)缺失值 用通用值统一替换 为每列替换不同的值 用每列的平均值,中位数,众数等替换 替换为上一个或下一个值 指定连续更换的最大数量 pandas.Series 提取缺失值 提取特定行/列中缺少值的列/行 提取至少包含一个缺失值
-
pandas如何优雅的列转行及行转列详解
目录 一.列转行 1.背景描述 2.方法描述 2.1 方法1 2.2 方法2 2.3 方法3 2.4 方法4 3 思考与总结 4 思维延伸 4.1 例子1 4.2 例子2 二.行转列 1.准备数据 2.行转列实现 2.1 方法1 2.2 方法2 2.3 方法3 3.思考与总结 三.行列转换(长宽互换) 总结 一.列转行 1.背景描述 在日常处理数据过程中,你们可能会经常遇到这种类型的数据: 而我们用pandas进行统计分析时,往往需要将结果转换成以下类型的数据: 2.方法描述 准备数据 df =
-
详解python中的lambda与sorted函数
lambda表达式 python中形如: lambda parameters: expression 称为lambda表达式,用于创建匿名函数,该表达式会产生一个函数对象. 该对象的行为类似于用以下方式定义的函数: def <lambda>(parameters): return expression python中的lambda函数可以接受任意数量的参数,但只能有一个表达式.也就是说,lambda表达式适用于表示内部仅包含1行表达式的函数.那么lambda表达式的优势就很明显了: 使用lam
-
Pandas搭配lambda组合使用详解
导入模块与读取数据 我们第一步需要导入模块以及数据集 import pandas as pd df = pd.read_csv("IMDB-Movie-Data.csv") df.head() 创建新的列 一般我们是通过在现有两列的基础上进行一些简单的数学运算来创建新的一列,例如 df['AvgRating'] = (df['Rating'] + df['Metascore']/10)/2 但是如果要新创建的列是经过相当复杂的计算得来的,那么lambda方法就很多必要被运用到了,我们先
-
对pandas中to_dict的用法详解
简介:pandas 中的to_dict 可以对DataFrame类型的数据进行转换 可以选择六种的转换类型,分别对应于参数 'dict', 'list', 'series', 'split', 'records', 'index',下面逐一介绍每种的用法 Help on method to_dict in module pandas.core.frame: to_dict(orient='dict') method of pandas.core.frame.DataFrame instance
-
python pandas.DataFrame.loc函数使用详解
官方函数 DataFrame.loc Access a group of rows and columns by label(s) or a boolean array. .loc[] is primarily label based, but may also be used with a boolean array. # 可以使用label值,但是也可以使用布尔值 Allowed inputs are: # 可以接受单个的label,多个label的列表,多个label的切片 A singl
-
Pandas中GroupBy具体用法详解
目录 简介 分割数据 多index get_group dropna groups属性 index的层级 group的遍历 聚合操作 通用聚合方法 同时使用多个聚合方法 NamedAgg 不同的列指定不同的聚合方法 转换操作 过滤操作 Apply操作 简介 pandas中的DF数据类型可以像数据库表格一样进行groupby操作.通常来说groupby操作可以分为三部分:分割数据,应用变换和和合并数据. 本文将会详细讲解Pandas中的groupby操作. 分割数据 分割数据的目的是将DF分割成为
-
Python Pandas学习之基本数据操作详解
目录 1索引操作 1.1直接使用行列索引(先列后行) 1.2结合loc或者iloc使用索引 1.3使用ix组合索引 2赋值操作 3排序 3.1DataFrame排序 3.2Series排序 为了更好的理解这些基本操作,下面会通过读取一个股票数据,来进行Pandas基本数据操作的语法介绍. # 读取文件(读取保存文件后面会专门进行讲解,这里先直接调用下api) data = pd.read_csv("./data/stock_day.csv") # 读取当前目录下一个csv文件 # 删
-
JS 面向对象之继承---多种组合继承详解
这一次要讲 组合.原型式.寄生式.寄生组合式继承方式. 1. 组合继承:又叫伪经典继承,是指将原型链和借用构造函数技术组合在一块的一种继承方式. 下面来看一个例子: function SuperType(name) { this.name = name; this.colors = ["red", "blue", "green"]; } SuperType.prototype.sayName = function() { alert(this.n
-
Java8 新特性Lambda表达式实例详解
Java8 新特性Lambda表达式实例详解 在介绍Lambda表达式之前,我们先来看只有单个方法的Interface(通常我们称之为回调接口): public interface OnClickListener { void onClick(View v); } 我们是这样使用它的: button.setOnClickListener(new View.OnClickListener() { @Override public void onClick(View v) { v.setText("
-
Java 8 lambda表达式引入详解及实例
Java 8 lambda表达式引入详解及实例 eclipse 下载安装 Help -> EclipseMarketplace -> 搜索Java 8 Kepler ->Java 8 support for eclipse Kepler SR2 安装完成后需要重启 Android Studio 在project的build.gradle文件中添加 buildscript { dependencies { classpath 'me.tatarka:gradle-retrolambda:3
-
pandas中的series数据类型详解
本文介绍了pandas中的series数据类型详解,分享给大家,具体如下: import pandas as pd import numpy as np import names ''' 写在前面的话: 1.series与array类型的不同之处为series有索引,而另一个没有;series中的数据必须是一维的,而array类型不一定 2.可以把series看成一个定长的有序字典,可以通过shape,index,values等得到series的属性 ''' # 1.series的创建 '''
-
Python的Lambda函数用法详解
在Python中有两种函数,一种是def定义的函数,另一种是lambda函数,也就是大家常说的匿名函数.今天我就和大家聊聊lambda函数,在Python编程中,大家习惯将其称为表达式. 1.为什么要用lambda函数? 先举一个例子:将一个列表里的每个元素都平方. 先用def来定义函数,代码如下 def sq(x): return x*x map(sq,[y for y in range(10)]) 再用lambda函数来编写代码 map(lambda x: x*x,[y for y in r