Pandas数据结构详细说明及如何创建Series,DataFrame对象方法
目录
- 1. Pandas的两种数据类型
- 2. Series类型
- 通过numpy array
- 通过Python字典
- 通过标量值(Scalar)
- name属性
- 3. DataFrame类型
- 通过包含列表的Python List
- 通过包含Python 字典的Python List
- 通过Series
在网络上的Pandas教程中,很多都提到了如何使用Pandas将已有的数据(如csv,如hdfs等)直接加载成Pandas数据对象,然后在其基础上进行数据分析操作,但是,很多时候,我们需要自己创建Pandas数据对象,并填入一些数据,常见的应用场景如:我们想要将现有的数据进行处理,并生成一个新的Pandas数据对象,还有,我们想利用Pandas的数据保存功能(比如to_csv, to_json, to_hdf等等)把我们采集到的数据写入到IO里边,因此掌握Pandas对象的特性,以及如何创建也是很重要的。
有些时候我们需要利用pandas数据结构创建自己的对象,按自己的方式保存新数据,我们将在本文中介绍如何实现。
1. Pandas的两种数据类型
Pandas支持两种数据类型,分别为Series和DataFrame,其中:
Series - 是一个带有标签的一维数组,支持多种不同的类型,但是针对同一个Series里边存储的数据类型必须是一致的
DataFrame - 是一个带有标签的二维数组,是一个尺寸可以修改的表格,一个DataFrame由多个Series组成,每一列都是一个Series
一句话描述的话就是,Series是很多标量数据(Scalar)的集合,而DataFrame是很多Series的集合。
我们来看下图这个例子,在1D的Series中,下图中有三个Series,分别保存了姓名(name), 年龄(age)和得分(marks),而他们的每一行都分别对应一个不同的人的信息,在每一个Series中的每一个单元格中(比如name series的第1行,对应的Prasadi)都是一个标量(Scalar),而每一行前边的0,1,2,3这些就是数据的索引(index),也可以叫做标签,所以说,Series是带有标签的一维数组。

可以看出,利用Series只能存储一种类型的数据,比如说name series存储的数据是字符串类型,而age series存储的数据是整数型。如果我们想把name,age,marks存储在一个数据结构里,我们就需要使用DataFrame,从图中看出,DataFrame类似于一个表格数据,有行有列,行跟Series的行一致,是数据的标签,而每一列就是原来的每一个Series。
2. Series类型
如我们在前文中所说,Series结构中可以存储任何类型的数据,包括:整型,字符串类型,浮点型,甚至是Python对象等等,但是要求是,每一行的数据类型必须统一。那么如何创建一个Series对象呢,
通过numpy array
Pandas的一个主要用途是数据分析,而它也是基于Numpy实现的,因此,通过numpy array来创建Series是非常常见的。
np_array = np.random.randn(5) pd.Series(np_array, index=['a', 'b', 'c', 'd', 'e'])
上边这段代码,利用np.random.randn随机生成一个长度为5的numpy array,然后pd.Series使用这个numpy array来创建一个Series,在创建的同时,指定了每一行的index(标签)分别是a,b,c,d,e,f,输出结果为:

通过Python字典
通过上边这个示例,大家有没有发现Series跟Python内置的dict类型是不是很类似,标签相当于dict中的key,而数据内容相当于dict中的value,它们有一一对应的关系,因此,可以想象,我们能够直接通过Python的dict来创建一个Series。
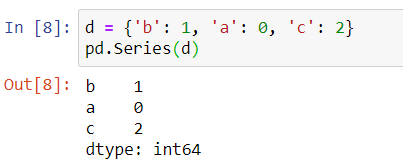
d = {'b': 1, 'a': 0, 'c': 2}
pd.Series(d)
上边这段代码,我们先创建了一个Python地点d,然后将这个字典传递给pd.Series来创建一个Pandas Series,运行结果为:
通过标量值(Scalar)
除了上边这两种方式,我们还可以通过一个简单的标量值来创建Series,特别注意的是跟上边两种方式不同,在使用这种方式创建Series的时候,我们必须指定index
pd.Series(5, index=['a', 'b', 'c', 'd', 'e'])
如上边代码所示,我们使用一个常量5,然后指定index为a,b,c,d,e,同样使用pd.Series可以创建一个Series对象,看到这里我们就能够明白为什么必须指定Index了吧,那是因为Series对象是有长度的,长度是可以大于1的,而标量的长度固定为1,我们可以通过指定Index的方式来控制生成的Series的长度,Series中的值则是重复使用这一个标量常量5。其运行结果为:

name属性
当我们创建一个Series的时候,我们可以指定一个名称,这个名称会被存储到Series的name属性中,后续我们还可以使用rename方法来修改这个属性,例如下边这样的代码:
s = pd.Series(np.random.randn(5), name='this_is_name') s
创建了一个名称为this_is_name的Series,然后我们使用rename方法来重命名这个Series为this_is_new_name:
s = s.rename('this_is_new_name')
s
上边这两部分代码的输入如下图:

那么这个名称有什么作用呢,这里预告一下,我们将在DataFrame中用到(别忘了DataFrame是多个Series的集合)
3. DataFrame类型
在第一节中我们介绍到,DataFrame是一个二维的表格数据结构,它有行和列的概念,跟行标签相对应的,为了能够按列索引数据,每一列都可以有一个名称,即列名,我们刚在Series章节中看到,Series可以表示一列数据,我们在本节中介绍的DataFrame就是多个这样的Series的组合,每一列就对应一个Series,而每一行也对应一个Series。读到这里,你是不是能够猜的出我们刚说的Series的name属性的用途了,对了,使用Series创建DataFrame的列的时候,Series的名称就会成为列名,如果Series作为行,则Series的名称会成为行名。
接下来我们来讲解如何创建DataFrame
通过一维numpy array或者Python List 组成的字典
大家可以想想,如果一个字典的value是array或者list的时候,那么这个字典其实就是一种表格结构,图为DataFrame是一个表格结构的数据类型,我们是可以通过这样的字典来创建DataFrame,例如下边这段代码
d = {'one': [1., 2., 3., 4.],
'two': [4., 3., 2., 1.]}
pd.DataFrame(d, index=['a', 'b', 'c', 'd'])
我们把d这个Python字典传递给pd.DataFrame来创建新的DataFrame,同时我们可以通过指定index来指定DataFrame的行名(标签),上边代码的输出为

通过包含列表的Python List
我们再来想想一下,除了字典之外可以表示表格数据,还有没有其他的方法,是的,还有Python List,例如下边这段代码
data = [(1, 2., 'Hello'), (2, 3., "World")] pd.DataFrame(data)
我们可以用data这样的Python List来表示表格数据,不同于前边提到的字典(dict),用List表示的表格数据其实是没有行名和列名的,因此Pandas默认会自动生成行名和列名,所以上边的代码输出为:

当然,自动生成的行名列名没有任何意义,为了更好的操作数据,我们还可以通过设置pd.DataFrame方法的index或者columns参数来指定自己的行名或者列名。
通过包含Python 字典的Python List
我们继续想想,还有什么能够表示表格数据?对了,包含Python字典的Python List也是可以表达表格数据的,例如下边的代码
data = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
pd.DataFrame(data)
data是一个Python List,而列表中的每一个元素都是一个字典,运行结果为:

类似的,我们也可以通过指定index或者columns参数来修改行名和列名
通过Series
我们一直在提DataFrame是很多Series的集合(注:Series在DataFrame中可以是一行,也可以是一列),因此,我们也可以通过Series来创建DataFrame,例如下边这段代码
s1 = pd.Series(np.random.randn(5), name='this_is_name') df = pd.DataFrame(s1) df
利用s1这个Series来创建只有一列的DataFrame,输出结果为:

还记得不,我们前边提到了Series的name属性,在使用Series创建DataFrame的时候,这个属性会用来作为列名(或者行名,我们在下边的列子可以看得出),例如下边的这段代码,如果有两个Series,我们还可以用下边这样的方式创建DataFrame
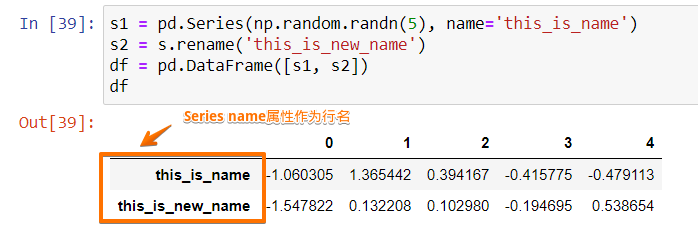
s1 = pd.Series(np.random.randn(5), name='this_is_name')
s2 = s.rename('this_is_new_name')
df = pd.DataFrame([s1, s2])
df
这里我们使用了两个名分别为this_is_name和this_is_new_name的Series来创建DataFrame,得到的结果为:
到这里,相信读者已经对Pandas提供的数据类型有了一个全面的认识了,并且有能力自己创建Pandas数据结构,并存储自己的数据了,一个常见的应用场景就是我们通过爬虫获取到数据以后,可以将这些非结构化的数据以Pandas的表格格式保存,值得注意的是数据存储在Pandas数据结构中的时候,数据其实是在内存中的,当程序被关闭以后,数据就丢失了,如果我们需要将数据持久化保存到硬盘或者数据库中的话,则可以通过简单的调用Pandas提供的to_csv, to_json, to_hdf等等接口将数据永久保存下来。
更多Python Pandas库的相关文章,请点击下面的相关文章
相关推荐
-
pandas 数据结构之Series的使用方法
1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index). 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会使用默认索引(从0到N-1). # 引入Series和DataFrame In [16]: from pandas import Series,DataFrame In [17]: import pandas as pd In [18]: ser1 = Series([1,2,3,4]) In [1
-
浅析pandas 数据结构中的DataFrame
DataFrame 类型类似于数据库表结构的数据结构,其含有行索引和列索引,可以将DataFrame 想成是由相同索引的Series组成的Dict类型.在其底层是通过二维以及一维的数据块实现. 1. DataFrame 对象的构建 1.1 用包含等长的列表或者是NumPy数组的字典创建DataFrame对象 In [68]: import pandas as pd In [69]: from pandas import Series,DataFrame # 建立包含等长列表的字典类型 In [7
-
Python Pandas数据结构简单介绍
Series Series 类似一维数组,由一组数据及一组相关数据标签组成.使用pandas的Series类即可创建. import pandas as pd s1 = pd.Series(['a', 'b', 'c,', 'd']) print(s1) #输出: 0 a # 1 b # 2 c # 3 d # dtype: object 上面是传入一个列表实现,上面的0,1,2,3就是数据的默认标签.另外可以通过index属性自定义标签. s2 = pd.Series(['1', '2', '
-
Pandas 稀疏数据结构的实现
目录 简介 Spare data的例子 SparseArray SparseDtype Sparse的属性 Sparse的计算 SparseSeries 和 SparseDataFrame 简介 如果数据中有很多NaN的值,存储起来就会浪费空间.为了解决这个问题,Pandas引入了一种叫做Sparse data的结构,来有效的存储这些NaN的值. Spare data的例子 我们创建一个数组,然后将其大部分数据设置为NaN,接着使用这个数组来创建SparseArray: In [1]: arr
-

Pandas数据结构详细说明及如何创建Series,DataFrame对象方法
目录 1. Pandas的两种数据类型 2. Series类型 通过numpy array 通过Python字典 通过标量值(Scalar) name属性 3. DataFrame类型 通过包含列表的Python List 通过包含Python 字典的Python List 通过Series 在网络上的Pandas教程中,很多都提到了如何使用Pandas将已有的数据(如csv,如hdfs等)直接加载成Pandas数据对象,然后在其基础上进行数据分析操作,但是,很多时候,我们需要自己创建Panda
-
pandas如何使用列表和字典创建 Series
目录 01 使用列表创建 Series 02 使用 name 参数创建 Series 03 使用简写的列表创建 Series 04 使用字典创建 Series 05 如何使用 Numpy 函数创建 Series 06 如何获取 Series 的索引和值 07 如何在创建 Series 时指定索引 08 如何获取 Series 的大小和形状 09 如何获取 Series 开始或末尾几行数据 10 使用切片获取 Series 子集 前言: Pandas 纳入了大量库和一些标准的数据模型,提供了高效地
-
python-pandas创建Series数据类型的操作
1.什么是pandas 2.查看pandas版本信息 print(pd.__version__) 输出: 0.24.1 3.常见数据类型 常见的数据类型: - 一维: Series - 二维: DataFrame - 三维: Panel - - 四维: Panel4D - - N维: PanelND - 4.pandas创建Series数据类型对象 1). 通过列表创建Series对象 array = ["粉条", "粉丝", "粉带"] # 如
-
Pandas数据结构之Series的使用
目录 一. Series 简介 二. 实例化 Series 2.1 使用一维数组实例化 2.2 使用字典实例化 2.3 使用标量例化 三.Series 简单使用 3.1 为Series添加Name属性 3.2 基于位置的切片 3.3 基于索引的切片 3.4 基于条件的切片 3.5 其他操作 一. Series 简介 Series是一种类似于一维数组的对象,是由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成.仅由一组数据也可产生简单的Series对象 Series 总的
-
pandas创建series的三种方法小结
目录 pandas创建series方法 创建方法一 Series 创建方法二 Series 创建方法三 Pandas的Series常用方法 1. 创建Series 2. Series追加 3. Series删除 4. Series改 5. Series查 pandas创建series方法 print("====创建series方法一===") dic={"a":1,"b":2,"c":3,"4":4} s=
-
Python Pandas学习之Pandas数据结构详解
目录 1Pandas介绍 2Pandas数据结构 2.1Series 2.2DataFrame 1 Pandas介绍 2008年WesMcKinney开发出的库 专门用于数据挖掘的开源python库 以Numpy为基础,借力Numpy模块在计算方面性能高的优势 基于matplotlib,能够简便的画图 独特的数据结构 Numpy已经能够帮助我们处理数据,能够结合matplotlib解决部分数据展示等问题,那么pandas学习的目的在什么地方呢? 增强图表可读性 便捷的数据处理能力 读取文件方便
-
Python 中pandas.read_excel详细介绍
Python 中pandas.read_excel详细介绍 #coding:utf-8 import pandas as pd import numpy as np filefullpath = r"/home/geeklee/temp/all_gov_file/pol_gov_mon/downloads/1.xls" #filefullpath = r"/home/geeklee/temp/all_gov_file/pol_gov_mon/downloads/26368f3
-
pandas创建新Dataframe并添加多行的实例
处理数据的时候,偶然遇到要把一个Dataframe中的某些行添加至一个空白的Dataframe中的问题. 最先想到的方法是创建Dataframe,从原有的Dataframe中逐行筛选出指定的行(类型为pandas的Series),并使用append方法进行添加.这种方法速度很慢,而且添加之后总会出现奇怪的问题,数据类型也不对. 较快的方法为,首先创建空的list,对原有的Dataframe进行逐行筛选,筛选出的行转化为dict类型,append进list中.全部添加完毕后,再将整个list转化为
-
Python数据结构详细
目录 1. 关于列表更多的内容 1.1. 把列表当作堆栈使用 1.2. 把列表当作队列使用 1.3. 列表推导式 1.4. 嵌套的列表推导式 2. del 语句 3. 元组和序列 4. 集合 6. 循环技巧 7. 深入条件控制 8. 比较序列和其它类型 1. 关于列表更多的内容 Python 的列表数据类型包含更多的方法.这里是所有的列表对象方法: list.``append(x) 把一个元素添加到列表的结尾,相当于 a[len(a):] = [x] list.``extend(L) 将一个给定