三大Python翻译神器再也不用担心学不好英语
导语

hello everyone! I'm kimiko!
Miss me???
嘿!中秋结束了,开始正式营业给大家继续送福利啦!

中秋在家发现:家里的小孩子在最后上学那天开始赶作业了!果然每个孩子的童年都是一样的!哈哈哈啊~
看了一眼侄女儿正在写英语翻译题目, 啊这一看不得了题目写的乱七八糟!!!
这让我有点儿上头啊,刚巧直接给我姐说了:‘'‘这英语还要加强学习撒'
老姐说:‘'回家我也不会教不了,学校的也没学好,一句完整的句子都讲不出来.......‘“

那肯定是拿上我30米的鼠标键盘,开始敲代码!这款中英文翻译神器,小孩子学习英文很轻松啊~回家就给我侄女儿装上电脑了!
正文
你是不是也经常遇到这些问题:往下看!!今天教大家写一款三大翻译神器,你值得拥有!
环境安装:python3.6、pycharm2021,以及自带的模块。
pip install -i https://pypi.douban.com/simple/ requests pip install -i https://pypi.douban.com/simple/ pyqt5
简单的界面可优化哈:
class Translator(QWidget):
def __init__(self, parent=None, **kwargs):
super(Translator, self).__init__(parent)
self.setWindowTitle('三大翻译软件')
self.setWindowIcon(QIcon('data/icon.jpg'))
self.Label1 = QLabel('原文')
self.Label2 = QLabel('译文')
self.LineEdit1 = QLineEdit()
self.LineEdit2 = QLineEdit()
self.translateButton1 = QPushButton()
self.translateButton2 = QPushButton()
self.translateButton3 = QPushButton()
self.translateButton1.setText('百度翻译')
self.translateButton2.setText('有道翻译')
self.translateButton3.setText('谷歌翻译')
self.grid = QGridLayout()
self.grid.setSpacing(12)
self.grid.addWidget(self.Label1, 1, 0)
self.grid.addWidget(self.LineEdit1, 1, 1)
self.grid.addWidget(self.Label2, 2, 0)
self.grid.addWidget(self.LineEdit2, 2, 1)
self.grid.addWidget(self.translateButton1, 1, 2)
self.grid.addWidget(self.translateButton2, 2, 2)
self.grid.addWidget(self.translateButton3, 3, 2)
self.setLayout(self.grid)
self.resize(400, 150)
self.translateButton1.clicked.connect(lambda : self.translate(api='baidu'))
self.translateButton2.clicked.connect(lambda : self.translate(api='youdao'))
self.translateButton3.clicked.connect(lambda : self.translate(api='google'))
self.bd_translate = baidu()
self.yd_translate = youdao()
self.gg_translate = google()
def translate(self, api='baidu'):
word = self.LineEdit1.text()
if not word:
return
if api == 'baidu':
results = self.bd_translate.translate(word)
elif api == 'youdao':
results = self.yd_translate.translate(word)
elif api == 'google':
results = self.gg_translate.translate(word)
else:
raise RuntimeError('Api should be <baidu> or <youdao> or <google>...')
self.LineEdit2.setText(';'.join(results))
三大翻译之一:百度翻译类。
class baidu():
def __init__(self):
self.session = requests.Session()
self.session.cookies.set('BAIDUID', '19288887A223954909730262637D1DEB:FG=1;')
self.session.cookies.set('PSTM', '%d;' % int(time.time()))
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
self.data = {
'from': '',
'to': '',
'query': '',
'transtype': 'translang',
'simple_means_flag': '3',
'sign': '',
'token': '',
'domain': 'common'
}
self.url = 'https://fanyi.baidu.com/v2transapi'
self.langdetect_url = 'https://fanyi.baidu.com/langdetect'
def translate(self, word):
self.data['from'] = self.detectLanguage(word)
self.data['to'] = 'en' if self.data['from'] == 'zh' else 'zh'
self.data['query'] = word
self.data['token'], gtk = self.getTokenGtk()
self.data['token'] = '6482f137ca44f07742b2677f5ffd39e1'
self.data['sign'] = self.getSign(gtk, word)
res = self.session.post(self.url, data=self.data)
return [res.json()['trans_result']['data'][0]['result'][0][1]]
def getTokenGtk(self):
url = 'https://fanyi.baidu.com/'
res = requests.get(url, headers=self.headers)
token = re.findall(r"token: '(.*?)'", res.text)[0]
gtk = re.findall(r";window.gtk = ('.*?');", res.text)[0]
return token, gtk
def getSign(self, gtk, word):
evaljs = js2py.EvalJs()
js_code = js.bd_js_code
js_code = js_code.replace('null !== i ? i : (i = window[l] || "") || ""', gtk)
evaljs.execute(js_code)
sign = evaljs.e(word)
return sign
def detectLanguage(self, word):
data = {
'query': word
}
res = self.session.post(self.langdetect_url, headers=self.headers, data=data)
return res.json()['lan']
三大翻译之二:有道翻译类。
class youdao():
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'Referer': 'http://fanyi.youdao.com/',
'Cookie': 'OUTFOX_SEARCH_USER_ID=-481680322@10.169.0.83;'
}
self.data = {
'i': None,
'from': 'AUTO',
'to': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': None,
'sign': None,
'ts': None,
'bv': None,
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'action': 'FY_BY_REALTlME'
}
self.url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
def translate(self, word):
ts = str(int(time.time()*10000))
salt = ts + str(int(random.random()*10))
sign = 'fanyideskweb' + word + salt + '97_3(jkMYg@T[KZQmqjTK'
sign = hashlib.md5(sign.encode('utf-8')).hexdigest()
bv = '5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
bv = hashlib.md5(bv.encode('utf-8')).hexdigest()
self.data['i'] = word
self.data['salt'] = salt
self.data['sign'] = sign
self.data['ts'] = ts
self.data['bv'] = bv
res = requests.post(self.url, headers=self.headers, data=self.data)
return [res.json()['translateResult'][0][0].get('tgt')]
三大翻译之三:Google翻译类。
class google():
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
}
self.url = 'https://translate.google.cn/translate_a/single?client=t&sl=auto&tl={}&hl=zh-CN&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&tk={}&q={}'
def translate(self, word):
if len(word) > 4891:
raise RuntimeError('The length of word should be less than 4891...')
languages = ['zh-CN', 'en']
if not self.isChinese(word):
target_language = languages[0]
else:
target_language = languages[1]
res = requests.get(self.url.format(target_language, self.getTk(word), word), headers=self.headers)
return [res.json()[0][0][0]]
def getTk(self, word):
evaljs = js2py.EvalJs()
js_code = js.gg_js_code
evaljs.execute(js_code)
tk = evaljs.TL(word)
return tk
def isChinese(self, word):
for w in word:
if '\u4e00' <= w <= '\u9fa5':
return True
return False
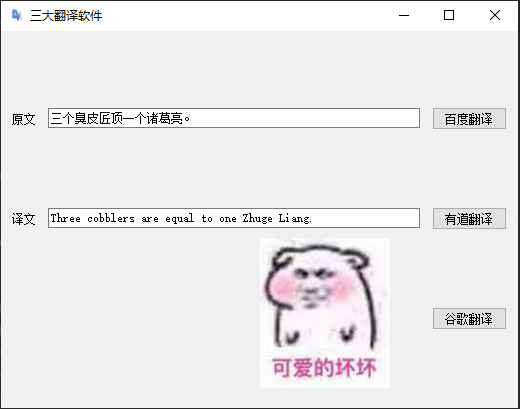
效果如下:中英文各一句哈!

总结
每天进步一点点!记得“三连哦~爱你”,坚持学习!!!

到此这篇关于三大Python翻译神器再也不用担心学不好英语的文章就介绍到这了,更多相关Python 翻译内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

教你如何利用Python批量翻译英文Word文档并保留格式
一.需求描述 手上有大量外文文档(本案例以5份为例,分别命名为 test1.docx test2.docx 以此类推),其中一份如下: 基本需求:「批量将这些文档的内容全部翻译成中文,并转存到新的文件中」,效果如下: 高级需求:基本需求满足的同时,要求 「保留原文档的格式」,效果如下: 二.逻辑梳理 2.1 翻译 API 本需求的核心是翻译,策略是利用网络的翻译 API,这里推荐百度翻译开放平台,不考虑并发数的话可以用标准版,免费使用不限字符量! " 百度翻译开放平台:http://api.fa
-
python爬虫之爬取百度翻译
破解百度翻译 翻译是一件麻烦的事情,如果可以写一个爬虫程序直接爬取百度翻译的翻译结果就好了,可当我打开百度翻译的页面,输入要翻译的词时突然发现不管我要翻译什么,网址都没有任何变化,那么百度翻译要怎么爬取呢? 爬取百度翻译之前,我们先要明白百度翻译是怎么在不改变网址的情况下实现翻译的.百度做到这一点是用 AJAX 实现的,简单地说,AJAX的作用是在不重新加载网页的情况下进行局部的刷新. 了解了这一点,那么我们要怎么得到 AJAX 工作时请求的URL呢?老规矩,使用抓包工具. 爬虫步骤 在 "百度
-
python做翻译软件详解,小白也看得明白
目录 前言 一.需要的库 二.分析处理 1.步骤 2.思路 三.代码的实现 1.翻译部分 2.图形界面代码 3.整合 总结 前言 对于我这种英语比较差的人来说,无论是敲代码还是看文档, 那都是离不开翻译软件的,于是我想自己用python做一个翻译软件, 花了一个小时,终于做了出来了,支持各种语言的翻译 一.需要的库 translate: 谷歌翻译的第三方包,可以实现多种语言之间的相互翻译. tkinter: Tkinter 是 Python 的标准 GUI 库.Python 使用 Tkinter
-
告别网页搜索!教你用python实现一款属于自己的翻译词典软件
一.设计理念 1.先写一个登录的py文件,用python的tkinter库 2.再写一个py文件用于爬取有道翻译输出栏的内容 3.再利用python的tkinter库,完成软件运行的窗口 4.将窗口的返回值与爬取有道翻译的结果接口对一下 5.第二个py文件里import第一个py文件,两个文件相关联 二.代码解析 请求方式为post,要注意from data里的值,这里可以在网页上再输一个想要翻译的内容,观察from data里的值的变化,可以确定'salt'. 'sign'. 'lts'这三个
-
用 Python 写的文档批量翻译工具效果竟然超出想象
大家好,我是启航. 本文将给大家分享一个实用的Python办公自动化脚本 「利用Python批量翻译英文Word文档并保留格式」,最终效果甚至比部分收费的软件还要好!先来看看具体的工作内容. 一.需求描述 手上有大量外文文档(本案例以5份为例,分别命名为 test1.docx test2.docx 以此类推),其中一份如下: 基本需求:「批量将这些文档的内容全部翻译成中文,并转存到新的文件中」,效果如下: 高级需求:基本需求满足的同时,要求 「保留原文档的格式」,效果如下: 二.逻辑梳理 1.
-
三大Python翻译神器再也不用担心学不好英语
导语 hello everyone! I'm kimiko! Miss me??? 嘿!中秋结束了,开始正式营业给大家继续送福利啦! 中秋在家发现:家里的小孩子在最后上学那天开始赶作业了!果然每个孩子的童年都是一样的!哈哈哈啊~ 看了一眼侄女儿正在写英语翻译题目, 啊这一看不得了题目写的乱七八糟!!! 这让我有点儿上头啊,刚巧直接给我姐说了:'''这英语还要加强学习撒' 老姐说:''回家我也不会教不了,学校的也没学好,一句完整的句子都讲不出来.......'" 那肯定是拿上我30
-
Python永久配置国内镜像源安装再也不用担心卡顿
目录 问题来源 配置国内镜像源 问题来源 今天在使用pip install xlutils安装xlutils包的时候,一直出现了该错误 ReadTimeoutError: HTTPSConnectionPool(host='files.pythonhosted.org', port=443): Read timed out. 可能原因是由于,使用这种方式安装某些库的时候,会从国外的镜像源去下载,最终导致反应超时的情况发生. 太扎心了,有时候想要使用某个库,却一直下载不下来,着急没办法呀!如何解决
-
微软开源最强Python自动化神器Playwright(不用写一行代码)
相信玩过爬虫的朋友都知道selenium,一个自动化测试的神器工具.写个Python自动化脚本解放双手基本上是常规的操作了,爬虫爬不了的,就用自动化测试凑一凑. 虽然selenium有完备的文档,但也需要一定的学习成本,对于一个纯小白来讲还是有些门槛的. 最近,微软开源了一个项目叫「playwright-python」,简直碉堡了!这个项目是针对Python语言的纯自动化工具,连代码都不用写,就能实现自动化功能. 可能你会觉得有点不可思议,但它就是这么厉害.下面我们一起看下这个神器. 1. Pl
-
这么设置IDEA中的Maven,再也不用担心依赖下载失败了
一.Maven 设置 当我们下载安装 Maven 之后,如果不修改 maven 中 setting 文件的. 那默认情况下, Maven 远程中央仓库地址为是个国外的地址. http://repo1.maven.org/maven2 那我们国内的网络,因为神秘的力量的影响,访问国外的地址就会比较慢. 如果你的网络情况很差,那么用默认的地址下载依赖资源就会很慢,有可能运行到一半下载失败. 那这种情况下,我们可以通过设置 Maven 仓库镜像地址从而解决这个问题. 那国内可以用的 Maven 的镜像
-
Python实现桌面翻译工具【新手必学】
Python 用了好长一段时间了,起初是基于对爬虫的兴趣而接触到的.随着不断的深入,慢慢的转了其它语言,毕竟工作机会真的太少了.很多技能长时间不去用,就会出现遗忘,也就有了整理一下,供初学者学习和讨论.相对于其它语言,你可以用很少的代码,便能实现一个完整的功能. ps:另外很多人在学习Python的过程中,往往因为遇问题解决不了从而导致自己放弃,为此我建了个Python全栈开发交流.裙 :一久武其而而流一思(数字的谐音)转换下可以找到了,里面有最新Python教程项目可拿,不懂的问题有老司机解决
-
学会用Python实现滑雪小游戏,再也不用去北海道啦
一.效果图 二.必要工具 Python3.7 pycharm2019 再然后配置它的文件,设置游戏屏幕的大小,图片路径. 代码如下 '''配置文件''' import os '''FPS''' FPS = 40 '''游戏屏幕大小''' SCREENSIZE = (640, 640) '''图片路径''' SKIER_IMAGE_PATHS = [ os.path.join(os.getcwd(), 'resources/images/skier_forward.png'), os.path.j
-
再也不用花钱买漫画!Python爬取某漫画的脚本及源码
一.工具 python3 第三方类库requests python3-pyqt5(GUI依赖,不用GUI可不装) ubuntu系列系统使用以下命令安装依赖: URL格式: 漫画首页的URL,如http://m.ac.qq.com/Comic/view/id/518333(移动版) 或 http://ac.qq.com/Comic/comicInfo/id/17114, http://ac.qq.com/naruto(PC版) 注意: 火影忍者彩漫需要访问m.ac.qq.com搜索火影忍者,因为P
-
Python利用PySimpleGUI实现自制桌面翻译神器
目录 一.基本思路 二.PySimpleGUI是什么 三.代码分析 1.引入包 2.谷歌翻译网址 3.构建翻译函数 4.GUI构建 四.Github开源地址 一.基本思路 基于PySimpleGUI开发桌面GUI→获取键盘输入→接入谷歌翻译API→爬虫获取翻译结果[其中涉及到正则表达式匹配翻译结果输出翻译结果口翻译完成. 二.PySimpleGUI是什么 创建图形用户界面(GUI)可能很困难,有许多不同的PythonGUI工具包可供选择.最常提到的前三名是 Tkinter,wxPython和Py
-
再也不用怕! 让你彻底搞明白Java内存分布
一.堆内内存 堆内内存分为三大部分,年轻代 , 老年代 和 元空间,所以 堆内内存 = 年轻代 + 老年代 + 元空间,下面细聊下三部分 1.1 年轻代-Young Generation 存放的是new 生成的对象 年轻代是为了尽可能快速的回收掉那些生命周期短的对象 Eden 大部分对象在Eden区中生成 当Eden区满时,会做一次young gc, 依然存活的对象将被复制到Survivor区, 当一个Survivor 区满时, 此区的存活对象将被复制到另外一个Survivor区 Survivo
-
Python可视化神器pyecharts绘制柱状图
目录 主题介绍 图表参数 主题详解 柱状图模板系列 海量数据柱状图动画展示 收入支出柱状图(适用于记账) 三维数据叠加 柱状图与折线图多维展示(同屏展示) 单列多维数据展示 3D柱状图 主题介绍 pyecharts里面有很多的主题可以供我们选择,我们可以根据自己的需要完成主题的配置,这样就告别了软件的限制,可以随意的发挥自己的艺术细胞了. 图表参数 ''' def add_yaxis( # 系列名称,用于 tooltip 的显示,legend 的图例筛选. series_name: str, #