MySQL 数据持久化过程讲解
目录
- 1. 过程简述
- 2. 内存中的操作
- 3. 磁盘的持久化
- 3.1 事务日志的作用
- 3.2 表结构的两步存储
1. 过程简述
理解MySQL数据的持久化过程,能很好的帮助我们加深对于MySQL底层的理解,在本文,我们以一种通俗的方式梳理一下这个过程,帮助大家建立起初步的认识,如果大家感兴趣,可以去深入学习与研究这个过程。
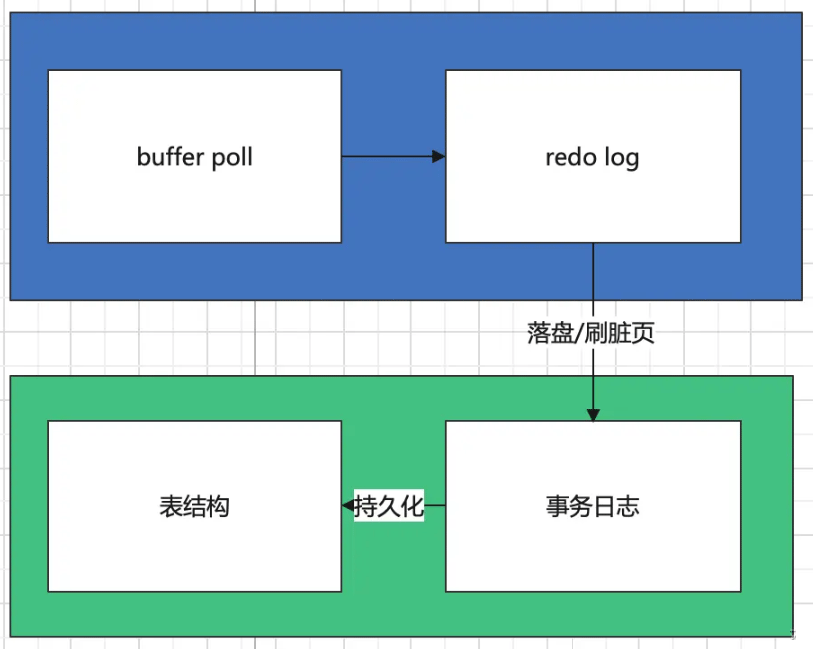
MySQL数据的存储总体上可以分为两部分,内存中的存储过程以及硬盘的持久化存储,这里,就涉及到了内存中buffer poll和redo log以及磁盘上的事务日志和表结构,在本文中,我们不具体解释每一部分的具体设计,只是给大家一个概念型的认识:
buffer poll是InnoDB引擎缓存池的一部分,我们这里可以简单理解为数据库从磁盘读进内存的内存块的缓存;redo log是内存中的逻辑日志,记录了事务的变更操作事务日志是磁盘上的食物逻辑日志表结构是真正存储数据的结构
2. 内存中的操作
buffer poll中有对于读入内存的数据的缓存,在查询命令执行时,会优先在缓存中查看是否命中,未命中就会从磁盘中将需要的数据读进来,缓存的管理使用的是改良的LRU算法,这里不做深入地介绍了。
当一条修改指令运行的时候,首先进行的是对于buffer poll中缓存的修改,被修改后的数据会被标记为脏页,同时,修改的操作也会记录在redo log中,我们常说的MVCC中的版本链就是借助redo log实现的。
需要注意的是,脏页不是立刻落到磁盘的,而是有可以设置的刷盘控制机制,例如,一个事务执行结算后立刻落盘,按照一定时间定期落盘等等。
在内存中的操作都是非持久化的,如果这时发生了意料之外的问题导致系统宕机,数据是还没有持久化的,所以理论上也不会对数据库造成破坏性的影响。
3. 磁盘的持久化
3.1 事务日志的作用
InnoDB在磁盘的持久化分为两步,第一步是逻辑日志的存储,之后再将日志中的数据刷进磁盘空间。
在讨论为什么要使用逻辑日志之前,我们需要简单理解随机IO与顺序IO的区别:
在读取磁盘数据的时候,有一个寻址的过程,即将探针移动到需要的位置,这个过程是磁盘IO的重要瓶颈之一。
顺序IO是指寻址的空间是连续的,移动距离很短,随机IO是指我们需要寻找的地址分布在各处,需要移动很长的距离。
所以,我们能很明晰的得出结论:将随机IO替换为顺序IO能有效的提高磁盘IO的效率,逻辑日志的作用正是如此,由于日志文件在磁盘上是连续的,相比于分布在各处的数据表信息,IO效率能高出很多。
只要我们在事务日志中完整更新了操作,那么这个事务就已经持久化成功了,后续会有专门负责的线程将日志信息存储到表结构中。
3.2 表结构的两步存储
日志信息存储到表结构的过程是分为两步进行的,首先,会在表头的缓存区域内进行数据更新,更新完成后,才会在对应的表结构中刷新。
两步存储的目的是保证数据存储的强一致性,防止在刷入磁盘的过程中,数据库宕机导致数据不完整。
表头的缓存区域以及表结构的存储块都有校验码来检验数据的完整性,如果前者完整,后者不完整,直接讲前者数据在后者中重新刷一份即可解决,如果前者不完整,说明从日志刷取的过程失败,重新刷取即可。
到此这篇关于MySQL 数据持久化过程讲解的文章就介绍到这了,更多相关MySQL 数据持久化 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解使用Docker部署MySQL(数据持久化)
本文简述如何使用Docker部署mysql,同时持久化数据.我们会用到tutum-docker-mysql 这个项目来搭建一个mysql,省去重头写Dockerfile的时间. 首先我们将tutum-docker-mysql跑起来. docker run -d -p 3306:3306 --name mysql tutum/mysql 如果你本地没有tutum/mysql的image,docker会先下载它的image,这一步可能会用些时间.待执行完毕我们检查一下应该会有如下样子 tutum-d
-

docker 挂载MySQL实现数据持久化的实现
目录 环境配置 MySQL数据持久化 注意事项 环境配置 本地操作系统:Win10虚拟机的操作系统:CentOS Stream 8已安装docker,可以参考详细安装教程 MySQL数据持久化 在上一节中我们已实现docker启动多个MySQL服务,当误删docker之后,docker里面运行的数据将无法保存.为了能保存docker里面运行的数据,需要使用docker挂载功能,将docker里面的数据保存在系统的本地目录,即使删掉docker仍能保存之前的数据.挂载MySQL实现数据持久化可以执
-
MySQL 数据持久化过程讲解
目录 1. 过程简述 2. 内存中的操作 3. 磁盘的持久化 3.1 事务日志的作用 3.2 表结构的两步存储 1. 过程简述 理解MySQL数据的持久化过程,能很好的帮助我们加深对于MySQL底层的理解,在本文,我们以一种通俗的方式梳理一下这个过程,帮助大家建立起初步的认识,如果大家感兴趣,可以去深入学习与研究这个过程. MySQL数据的存储总体上可以分为两部分,内存中的存储过程以及硬盘的持久化存储,这里,就涉及到了内存中buffer poll和redo log以及磁盘上的事务日志和表结构,在
-
Python操作ES的方式及与Mysql数据同步过程示例
目录 Python操作Elasticsearch的两种方式 mysql和Elasticsearch同步数据 haystack的使用 Redis补充 Python操作Elasticsearch的两种方式 # 官方提供的:Elasticsearch # pip install elasticsearch # GUI:pyhon能做图形化界面编程吗? -Tkinter -pyqt # 使用(查询是重点) # pip3 install elasticsearch https://github.com/e
-
mysql数据校验过程中的字符集问题处理
场景:主库DB:utf8字符集备库DB:gbk字符集 需求:校验主备数据是否一致,并且修复 校验过程:设置主库连接为utf8,设置备库连接为gbk,分别进行查询,将返回的的结果集按记录逐字段比较. 显示结果:原本相同的汉字字符,数据校验认为不一致. 原因分析:对于主库而已,由于建立连接的字符集为UTF8,则返回的汉字字符编码为UTF8格式:对于备库而言则是GBK格式,而程序中通过字符串比较函数strcasecmp进行比较,显然不同的字符集编码,相同的字符有不同的二进制,因此结果肯定不会相等. 进
-
Python向MySQL批量插数据的实例讲解
背景:最近测试web项目需要多条测试数据,sql中嫌要写多条,就看了看python如何向MySQL批量插数据(pymysql库) 1.向MySQL批量插数据 import pymysql #import datetime #day = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')#参数值插入时间 db = pymysql.connect(host='服务器IP', user='账号', passwd='密码', port=端口号) c
-
Springboot上传excel并将表格数据导入或更新mySql数据库的过程
本文主要描述,Springboot-mybatis框架下上传excel,并将之导入mysql数据库的过程,如果用户id已存在,则进行更新修改数据库中该项信息,由于用到的是前后端分离技术,这里记录的主要是后端java部分,通过与前端接口进行对接实现功能,使用layui等前端框架与之对接,也可以自己写前端代码,本文以Controller开始,从导入过程开始讲述,其中包括字典表的转换 1.在pom.xml文件中导入注解,主要利用POI <dependency> <groupId>org.
-
MySql恢复数据方法梳理讲解
目录 一.前言 二.步骤 三.其它笔记 一.前言 mysql具有binlog功能,可以记录对表进行过的操作.执行过的sql语句: 以下主要是总结下binlog的开启方法.使用方法等: 如果误删数据库表中的某些数据.或者误删整个表.误修改表结构等,就可以使用这个方法进行恢复. 二.步骤 1.如果想使用MySql数据恢复功能,首先需要修改Mysql配置文件,开启binlog功能.(有些版本binlog默认是不开启的,因此需要手动修改配置文件开启) (1)windows环境 配置文件名称为my.ini
-
Docker安装部署Mysql8的过程(以作数据持久化)
目录 1.创建容器并进行持久化处理 2.配置远程连接并尝试 1.创建容器并进行持久化处理 #拉取镜像 docker pull mysql:8.0.20 #启动镜像,用于拷贝配置文件到宿主机 docker run -p 3306:3306 --name mysql -e MYSQL_ROOT_PASSWORD=123456 -d mysql:8.0.20 #查看是否启动成功 docker ps -a #新建挂载目录并拷贝配置文件 mkdir -p /mysqldata/ docker cp mys
-
讲解Linux系统下如何自动备份MySQL数据的基本教程
1.先创建一个数据库备份目录: mkdir backup cd backup mkdir mysqlbackup cd mysqlbackup 2.创建备份脚本 vi mysqlautobackup 3.编写脚本: filename=`date +%Y%m%d` /mysql的bin目录/mysqldump --opt 数据库名 -u(mysql账号) -p(mysql密码) | gzip > /备份到哪个目录/name$filename.gz 说明:以上采用gzip压缩,name可随意写,注意