Python用requests库爬取返回为空的解决办法
首先介紹一下我們用360搜索派取城市排名前20。
我们爬取的网址:https://baike.so.com/doc/24368318-25185095.html
我们要爬取的内容:

html字段:

robots协议:

现在我们开始用python IDLE 爬取

import requests
r = requests.get("https://baike.so.com/doc/24368318-25185095.html")
r.status_code
r.text
结果分析,我们可以成功访问到该网页,但是得不到网页的结果。被360搜索识别,我们将headers修改。
输出有个小插曲,网页内容很多,我是想将前500个字符输出,第一次格式错了
import requests
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.status_code
r.text
接着我们对需要的内容进行爬取,用(.find)方法找到我们内容位置,用(.children)下行遍历的方法对内容进行爬取,用(isinstance)方法对内容进行筛选:
import requests
from bs4 import BeautifulSoup
import bs4
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.status_code
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
print([tds[0].string, tds[1].string, tds[2].string])
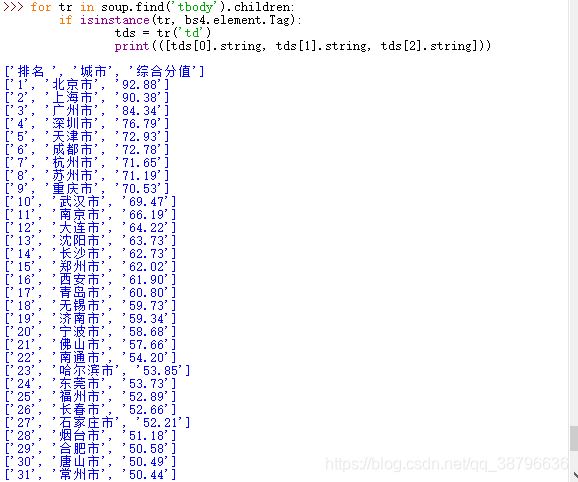
得到结果如下:
修改输出的数目,我们用Clist列表来存取所有城市的排名,将前20个输出代码如下:
import requests
from bs4 import BeautifulSoup
import bs4
Clist = list() #存所有城市的列表
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.encoding = r.apparent_encoding #将html的编码解码为utf-8格式
soup = BeautifulSoup(r.text, "html.parser") #重新排版
for tr in soup.find('tbody').children: #将tbody标签的子列全部读取
if isinstance(tr, bs4.element.Tag): #筛选tb列表,将有内容的筛选出啦
tds = tr('td')
Clist.append([tds[0].string, tds[1].string, tds[2].string])
for i in range(21):
print(Clist[i])
最终结果:

到此这篇关于Python用requests库爬取返回为空的解决办法的文章就介绍到这了,更多相关Python requests返回为空内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python:解析requests返回的response(json格式)说明
我就废话不多说了,大家还是直接看代码吧! import requests, json r = requests.get('http://192.168.207.160:9000/api/qualitygates/project_status?projectId=%s' % (p_uuid) ) state=json.loads(r.text).get('projectStatus').get('status') 返回如下: { "projectStatus": { "stat
-

Python用requests库爬取返回为空的解决办法
首先介紹一下我們用360搜索派取城市排名前20. 我们爬取的网址:https://baike.so.com/doc/24368318-25185095.html 我们要爬取的内容: html字段: robots协议: 现在我们开始用python IDLE 爬取 import requests r = requests.get("https://baike.so.com/doc/24368318-25185095.html") r.status_code r.text 结果分析,我们可以
-
python使用requests库爬取拉勾网招聘信息的实现
按F12打开开发者工具抓包,可以定位到招聘信息的接口 在请求中可以获取到接口的url和formdata,表单中pn为请求的页数,kd为关请求职位的关键字 使用python构建post请求 data = { 'first': 'true', 'pn': '1', 'kd': 'python' } headers = { 'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&a
-
Python基于requests库爬取网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML 下面这段代码便是爬取百度的信息并简单输出百度的界面信息 import requests from bs4 import BeautifulSoup r=requests.get('http://www.bai
-
通过python爬虫mechanize库爬取本机ip地址的方法
目录 需求分析 实现分析 实际使用 完整代码演示 需求分析 最近,各平台更新的ip属地功能非常火爆,因此呢,也出现了许多新的网络用语,比如说“xx加几分”,“xx扣大分”等等,非常的有趣啊 可是呢,最近一个小伙伴和我说,“仙草哥哥,我也想查看一下自己的ip地址,可是我不会啊,我应该怎么样才能查看到自己的ip地址呢?” 关于如何查看自己的ip地址,这个我记得我在很早之前已经写过了,有兴趣的话可以查看一下我的这篇文章,当然这次呢,我会换一个复古的方式,使用mechanize进行爬取 实现分析 pyt
-
Python通过正则库爬取淘宝商品信息代码实例
使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象 我们在淘宝里搜索"python",出来的结果 从url连接中可以得到搜索商品的关键字是"q=",所以我们要用的起始url为:https://s.taobao.com/search?q=python 然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44) 所以可以根据关键字"s=",来设置爬取的深度(爬取多少页)
-
python requests库爬取豆瓣电视剧数据并保存到本地详解
首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构: https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start=0 这是接口地址,可以大概的分析一下各个参数的规则: type=tv,表示的是电视剧的分类 tag=国产剧,表示是
-
Python使用requests模块爬取百度翻译
requests模块: python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高. 作用:模拟浏览器发请求. 提示:老版使用 urllib模块,但requests比urllib模块要简单好用,现在学习requests模块即可! requests模块编码流程 指定url 1.1 UA伪装 1.2 请求参数的处理 2.发起请求 3.获取响应数据 4.持久化存储 环境安装: pip install requests 案例一:破解百度翻译(post请求) 1.代码如下: #爬取百度翻
-
python3使用requests模块爬取页面内容的实战演练
1.安装pip 我的个人桌面系统用的linuxmint,系统默认没有安装pip,考虑到后面安装requests模块使用pip,所以我这里第一步先安装pip. $ sudo apt install python-pip 安装成功,查看PIP版本: $ pip -V 2.安装requests模块 这里我是通过pip方式进行安装: $ pip install requests 运行import requests,如果没提示错误,那说明已经安装成功了! 检验是否安装成功 3.安装beautifulsou
-
python爬虫---requests库的用法详解
requests是python实现的简单易用的HTTP库,使用起来比urllib简洁很多 因为是第三方库,所以使用前需要cmd安装 pip install requests 安装完成后import一下,正常则说明可以开始使用了. 基本用法: requests.get()用于请求目标网站,类型是一个HTTPresponse类型 import requests response = requests.get('http://www.baidu.com')print(response.status_c
-
Python实战快速上手BeautifulSoup库爬取专栏标题和地址
目录 安装 解析标签 解析属性 根据class值解析 根据ID解析 多层筛选 提取a标签中的网址 实战-获取博客专栏 标题+网址 BeautifulSoup库快速上手 安装 pip install beautifulsoup4 # 上面的安装失败使用下面的 使用镜像 pip install beautifulsoup4 -i https://pypi.tuna.tsinghua.edu.cn/simple 使用PyCharm的命令行 解析标签 from bs4 import BeautifulS