C++ 利用硬件加速矩阵乘法的实现
一、矩阵乘法定义
矩阵 A x × y 和 矩阵 B u × v 相乘的前提条件是 y = = u ,并且相乘后得到的矩阵为 C x × v(即 A 的行和 B 的列构成了矩阵 C的行列);
二、矩阵类封装
我们用 C++ 封装了一个 n × m 的矩阵类,用二维数组来存储数据,定义如下:
#define MAXN 1000
#define LL __int64
class Matrix {
private:
int n, m;
LL** pkData;
public:
Matrix() : n(0), m(0) {
pkData = NULL;
}
void Alloc() {
pkData = new LL *[MAXN]; // 1)
for (int i = 0; i < MAXN; ++i) {
pkData[i] = new LL[MAXN];
}
}
void Dealloc() {
if (pkData) {
for (int i = 0; i < MAXN; ++i) { // 2)
delete [] pkData[i];
}
delete[] pkData;
pkData = NULL;
}
}
};
1) p k D a t a 可以认为是一个二维数组( p k D a t a [ i ] [ j ]就是矩阵第 i 行,第 j 列的数据),之所以这里用了二维指针,是因为当 MAXN 很大时,栈上分配不了这么多空间,容易导致栈溢出,所以通过 new 把空间分配在了堆上;2)释放空间的时候,首先释放低维空间,再释放高维空间;
三、矩阵乘法实现
1、ijk式
最简单的矩阵乘法实现如下:
class Matrix {
...
public:
void Multiply_ijk(const Matrix& other, Matrix& ret) {
// assert(m == other.n);
ret.Reset(n, other.m);
int i, j, k;
for (i = 0; i < n; i++) {
for (j = 0; j < other.m; j++) {
for (k = 0; k < m; k++) {
ret.pkData[i][j] += pkData[i][k] * other.pkData[k][j];
}
}
}
}
};
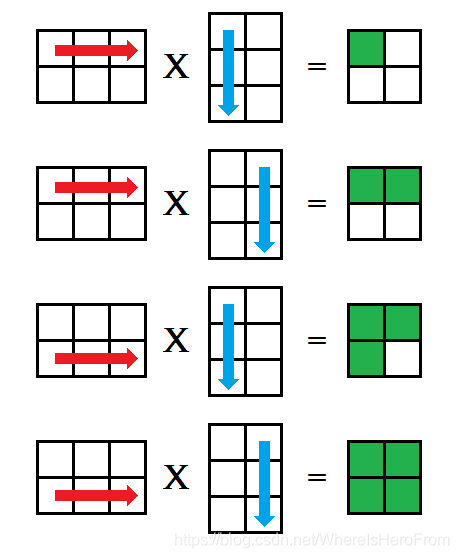
这种方法被称为ijk 式,对矩阵乘法 A × B = C ,枚举 A 的每一行,再枚举 B的每一列,分别对应相乘后放入矩阵 C的对应位置中,如下图所示;
2、 ikj 式
对上述算法进行一些改进,交换两个内层循环的位置,得到如下算法:
class Matrix {
...
public:
void Multiply_ikj(const Matrix& other, Matrix& ret) {
// assert(m == other.n);
ret.Reset(n, other.m);
int i, j, k;
for (i = 0; i < n; i++) {
for (k = 0; k < m; k++) {
LL v = pkData[i][k];
for (j = 0; j < other.m; j++) {
ret.pkData[i][j] += v * other.pkData[k][j];
}
}
}
}
};
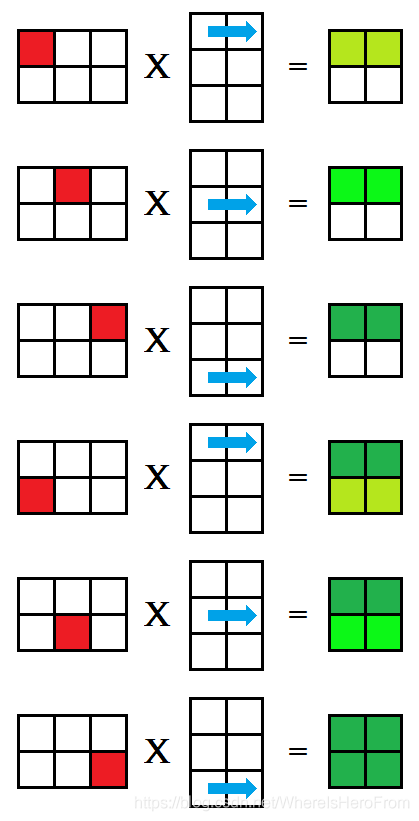
这种方法被称为 ikj 式,对矩阵乘法 A × B = C A \times B = C A×B=C,行优先枚举 A A A 的每一个格子,再枚举 B B B 的每一行,分别对应相乘后放入矩阵 C C C 的对应位置中,每次相乘得到的 C C C 都是部分积,如下图所示,用绿色的深浅来表示这个值是否已经完整求得;
3、kij 式
对上述算法再进行一些改进,交换两个外层循环的位置,得到如下算法:
class Matrix {
...
public:
void Multiply_kij(const Matrix& other, Matrix& ret) {
// assert(m == other.n);
ret.Reset(n, other.m);
int i, j, k;
for (k = 0; k < m; k++) {
for (i = 0; i < n; i++) {
LL v = pkData[i][k];
for (j = 0; j < other.m; j++) {
ret.pkData[i][j] += v * other.pkData[k][j];
}
}
}
}
};
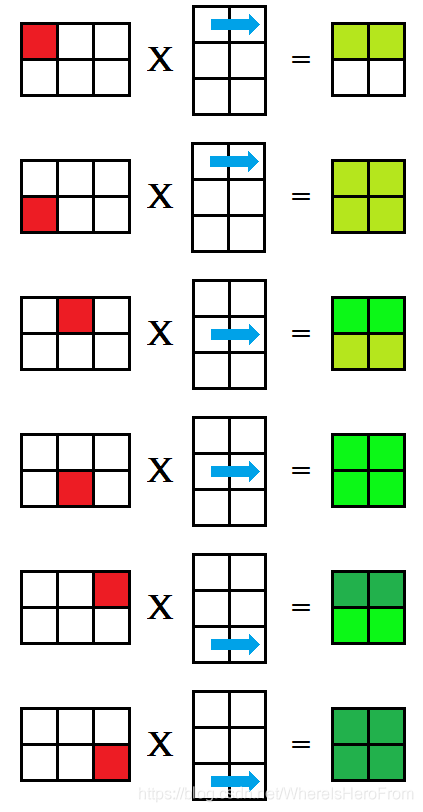
这种方法被称为 k i j kij kij 式,对矩阵乘法 A × B = C A \times B = C A×B=C,列优先枚举 A A A 的每一个格子,再枚举 B B B 的每一行,分别对应相乘后放入矩阵 C C C 的对应位置中,每次相乘得到的 C C C 都是部分积,如下图所示,用绿色的深浅来表示这个值是否已经完整求得;
四、时间测试
| 矩阵阶数 | i j k ijkijk | i k j ikjikj | k i j kijkij |
|---|---|---|---|
| 200 | 47 ms | 31 ms | 16 ms |
| 500 | 781 ms | 438 ms | 453 ms |
| 1000 | 8657 ms | 3687 ms | 3688 ms |
| 2000 | 69547 ms | 28000 ms | 29672 ms |
由于矩阵乘法本身的时间复杂度是 O(N3) 的,所以数据量越大,越能看出实际效果;
五、原理分析
原因是因为 CPU 访问内存的速度比 CPU 计算速度慢得多,为了解决速度不匹配的问题,在 CPU 与 内存 之间加了高速缓存cache。高速缓存 cache 的存在大大提高了 CPU 访问数据的速度。但是当内存访问不连续的时候,就会导致 cache 命中率降低,所以为了加速,就要尽可能使内存访问连续,即不要跳来跳去。矩阵
六、最后结论
运行速度: ikj ≈ kij > ijk
模板地址:矩阵乘法模板
到此这篇关于C++ 利用硬件加速矩阵乘法的实现的文章就介绍到这了,更多相关C++ 矩阵乘法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C++稀疏矩阵的各种基本运算并实现加法乘法
代码: #include <iostream> #include<malloc.h> #include<cstdio> using namespace std; #define M 4 #define N 4 #define MaxSize 100 typedef int ElemType; typedef struct { int r; int c; ElemType d;///元素值 } TupNode; ///三元组定义 typedef struct { int
-
C++中实现矩阵的加法和乘法实例
C++中实现矩阵的加法和乘法实例 实现效果图: 实例代码: #include<iostream> using namespace std; class Matrix { int row;//矩阵的行 int col;//矩阵的列 int **a;//保存二维数组的元素 public: Matrix();//默认构造函数 Matrix(int r, int c); Matrix(const Matrix &is);//拷贝构造函数 void Madd(const Matrix &
-
C++ 利用硬件加速矩阵乘法的实现
一.矩阵乘法定义 矩阵 A x × y 和 矩阵 B u × v 相乘的前提条件是 y = = u ,并且相乘后得到的矩阵为 C x × v(即 A 的行和 B 的列构成了矩阵 C的行列): 二.矩阵类封装 我们用 C++ 封装了一个 n × m 的矩阵类,用二维数组来存储数据,定义如下: #define MAXN 1000 #define LL __int64 class Matrix { private: int n, m; LL** pkData; public: Matrix() : n
-
浅谈Android硬件加速原理与实现简介
在手机客户端尤其是Android应用的开发过程中,我们经常会接触到"硬件加速"这个词.由于操作系统对底层软硬件封装非常完善,上层软件开发者往往对硬件加速的底层原理了解很少,也不清楚了解底层原理的意义,因此常会有一些误解,如硬件加速是不是通过特殊算法实现页面渲染加速,或是通过硬件提高CPU/GPU运算速率实现渲染加速. 本文尝试从底层硬件原理,一直到上层代码实现,对硬件加速技术进行简单介绍,其中上层实现基于Android 6.0. 了解硬件加速对App开发的意义 对于App开发者,简单了
-
C++ Qt利用GPU加速计算的示例详解
在 C++ 和 Qt 中,可以通过以下方式利用 GPU 进行加速计算: 使用 GPU 编程框架:可以使用类似 CUDA.OpenCL.DirectCompute 等 GPU 编程框架,这些框架提供了对 GPU 的访问和操作,可以使用 GPU 进行并行计算,从而加速计算速度. 使用图形 API:在 Qt 中,可以使用 QOpenGLFunctions 等 API 访问 GPU,这些 API 可以用于执行图形渲染.图像处理等任务,利用 GPU 进行计算. 使用高性能计算库:在 C++ 中,有一些高性
-
理解Android硬件加速原理(小白文)
前言 硬件加速,直观上说就是依赖 GPU 实现图形绘制加速,同软硬件加速的区别主要是图形的绘制究竟是 GPU 来处理还是 CPU,如果是GPU,就认为是硬件加速绘制,反之,软件绘制.在 Android 中也是如此,不过相对于普通的软件绘制,硬件加速还做了其他方面优化,不仅仅限定在绘制方面,绘制之前,在如何构建绘制区域上,硬件加速也做出了很大优化,因此硬件加速特性可以从下面两部分来分析: 1.前期策略:如何构建需要绘制的区域 2.后期绘制:单独渲染线程,依赖 GPU 进行绘制 无论是软件绘制还是硬
-
C++使用cuBLAS加速矩阵乘法运算的实现代码
本博客主要参考cuBLAS 库 词条实现,与原文不同的是,本博客: 将cuBLAS库的乘法运算进行了封装,方便了算法调用: 将原文的结果转置实现为了不转置,这样可以直接使用计算结果: 测试并更改了乘法参数,解决了原文中更改矩阵大小时报错的问题. 总的来说,本博客的代码利用cuBLAS库实现了两个矩阵相乘,提高了矩阵乘法的计算速度. test.cpp #include "cuda_runtime.h" #include "cublas_v2.h" #include &
-
详解Android开发中硬件加速支持的使用方法
Android从3.0(API Level 11)开始,在绘制View的时候支持硬件加速,充分利用GPU的特性,使得绘制更加平滑,但是会多消耗一些内存. 开启或关闭硬件加速: 由于硬件加速自身并非完美无缺,所以Android提供选项来打开或者关闭硬件加速,默认是关闭.可以在4个级别上打开或者关闭硬件加速: Application级别:<applicationandroid:hardwareAccelerated="true" ...>
-
利用CDN加速react webpack打包后的文件详解
此文不介绍webpack基本配置,如果对基本配置有疑问请查阅官方文档. 1.配置webpack.config.js 将output.publicPath改成上传到的cdn地址, 例(对应上面上传配置): publicPath: "https://your_base_cdn_url" + process.env.NODE_ENV + "/cdn/" 打包 NODE_ENV=production node_modules/webpack/bin/webpack.js -
-
浅谈利用numpy对矩阵进行归一化处理的方法
本文不讲归一化原理,只介绍实现(事实上看了代码就会懂原理),代码如下: def Normalize(data): m = np.mean(data) mx = max(data) mn = min(data) return [(float(i) - m) / (mx - mn) for i in data] 代码只有5行并不复杂,但是需要注意的一点是一定要将计算的均值以及矩阵的最大.最小值存为变量放到循环里,如果直接在循环里计算对应的值会造成归一化特别慢,笔者之前有过深切的酸爽体验-. 以上这篇
-
NumPy 矩阵乘法的实现示例
NumPy 支持的几类矩阵乘法也很重要. 元素级乘法 你已看过了一些元素级乘法.你可以使用 multiply 函数或 * 运算符来实现.回顾一下,它看起来是这样的: m = np.array([[1,2,3],[4,5,6]]) m # 显示以下结果: # array([[1, 2, 3], # [4, 5, 6]]) n = m * 0.25 n # 显示以下结果: # array([[ 0.25, 0.5 , 0.75], # [ 1. , 1.25, 1.5 ]]) m * n # 显示以
-
全网最强下载神器IDM使用教程之利用IDM加速下载百度网盘大文件的方法
目录 01 开发背景 02 功能介绍 03 如何下载百度网盘 1.安装IDM软件 2.配置IDM软件 3.安装油猴脚本 4.下载百度网盘文件 推荐阅读: IDM 6.40.11.2 弹窗的完美解决思路 一个假冒的序列号被用来注册Internet Download Manager,IDM正在退出的解决办法 超实用Internet Download Manager(IDM)破解注册码,全版本通用 自从不限速度盘下载工具Pandownload被封杀后,有些网友纷纷表示:幸好我们还有IDM. 但是,对于