RabbitMQ的基础知识
目录
- RabbitMQ
- 1.对MQ的介绍
- 2.RabbitMQ的六种模式 及工作原理
- 3.hello world队列
- 4.工作队列模式
- 5.消息应答机制
- 自动应答
- 手动应答
- 消息自动进行重新入队
- 6.RabbitMQ的持久化,不公平分发及预取值
- 7.发布确认
- 8.交换机
- <1>交换机的认识
- <2>交换机具体介绍
- 9.死信队列
- <1>认识死信队列
- <2>死信实战
RabbitMQ
1.对MQ的介绍
1.说明是MQ
MQ(message queue),从字面意思上看,本质是个队列,FIFO 先入先出,只不过队列中存放的内容是
message 而已,还是一种跨进程的通信机制,用于上下游传递消息。在互联网架构中,MQ 是一种非常常
见的上下游“逻辑解耦+物理解耦”的消息通信服务。使用了 MQ 之后,消息发送上游只需要依赖 MQ,不
用依赖其他服务。
2.MQ的好处
1.流量消峰
举个例子,如果订单系统最多能处理一万次订单,这个处理能力应付正常时段的下单时绰绰有余,正常时段我们下单一秒后就能返回结果。但是在高峰期,如果有两万次下单操作系统是处理不了的,只能限制订单超过一万后不允许用户下单。使用消息队列做缓冲,我们可以取消这个限制,把一秒内下的订单分散成一段时间来处理,这时有些用户可能在下单十几秒后才能收到下单成功的操作,但是比不能下单的体验要好。
2.应用解耦
以电商应用为例,应用中有订单系统、库存系统、物流系统、支付系统。用户创建订单后,如果耦合调用库存系统、物流系统、支付系统,任何一个子系统出了故障,都会造成下单操作异常。当转变成基于消息队列的方式后,系统间调用的问题会减少很多,比如物流系统因为发生故障,需要几分钟来修复。在这几分钟的时间里,物流系统要处理的内存被缓存在消息队列中,用户的下单操作可以正常完成。当物流系统恢复后,继续处理订单信息即可,用户感受不到物流系统的故障,提升系统的可用性。

- 异步处理
有些服务间调用是异步的,例如 A 调用 B,B 需要花费很长时间执行,但是 A 需要知道 B 什么时候可以执行完,以前一般有两种方式,A 过一段时间去调用 B 的查询 api 查询。或者 A 提供一个 callback api, B 执行完之后调用 api 通知 A 服务。这两种方式都不是很优雅,使用消息总线,可以很方便解决这个问题,A 调用 B 服务后,只需要监听 B 处理完成的消息,当 B 处理完成后,会发送一条消息给 MQ,MQ 会将此消息转发给 A 服务。这样 A 服务既不用循环调用 B 的查询 api,也不用提供 callback api。同样 B 服务也不用做这些操作。A 服务还能及时的得到异步处理成功的消息。

2.RabbitMQ的六种模式 及工作原理
工作模式
依次是:hello world ,工作模式,发布订阅模式,路由模式,主题模式,发布确认模式
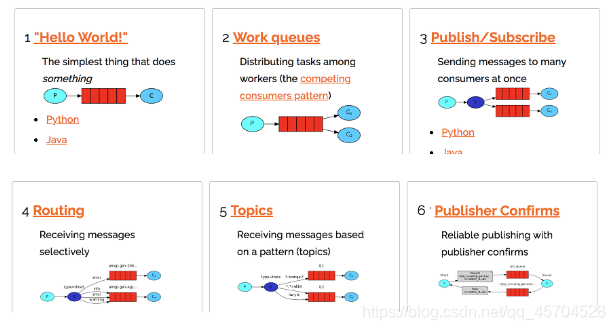
工作原理

Binding:exchange 和 queue 之间的虚拟连接,binding 中可以包含 routing key,Binding 信息被保
存到 exchange 中的查询表中,用于 message 的分发依据
依赖
<!--rabbitmq 依赖客户端--> <dependency> <groupId>com.rabbitmq</groupId> <artifactId>amqp-client</artifactId> <version>5.8.0</version> </dependency>
3.hello world队列

1.生产者
public class Producer {
//建立队列
private static final String QUEUE_NAME="hello";
public static void main(String[] args) {
//创建连接工场
ConnectionFactory factory=new ConnectionFactory();
factory.setHost("127.0.0.1");
factory.setUsername("guest");
factory.setUsername("guest");
try {
//建立连接和信道
//channel 实现了自动 close 接口 自动关闭 不需要显示关闭
Connection connection=factory.newConnection();
Channel channel=connection.createChannel();
/**
* 生成一个队列,并将信道和队列连接
* 1.队列名称
* 2.队列里面的消息是否持久化 默认消息存储在内存中
* 3.该队列是否只供一个消费者进行消费 是否进行共享 true 可以多个消费者消费
* 4.是否自动删除 最后一个消费者端开连接以后 该队列是否自动删除 true 自动删除
* 5.其他参数
*/
channel.queueDeclare(QUEUE_NAME,false,false,false,null);
String message="hello world";
/**
* 发送一个消息
* 1.发送到那个交换机
* 2.路由的 key 是哪个
* 3.其他的参数信息
* 4.发送消息的消息体
*/
channel.basicPublish("",QUEUE_NAME,null,message.getBytes());
System.out.println("消息发送成功");
}catch (Exception e){
e.printStackTrace();
}
}
}
消费者
public class Consumer {
//定义队列名
private static final String QUEUE_NAME="hello";
public static void main(String[] args) {
//建立连接和信道
try {
ConnectionFactory factory=new ConnectionFactory();
factory.setHost("127.0.0.1");
factory.setUsername("guest");
factory.setPassword("guest");
Connection connection=factory.newConnection();
Channel channel=connection.createChannel();
System.out.println("等待接收消息");
/**
*1.同一个会话, consumerTag 是固定的 可以做此会话的名字, deliveryTag 每次接收消息+1,可以做此消息处理通道的名字。
*2.包含消息的字节形式的类
*/
DeliverCallback deliverCallback=(consumerTag,delivery)->{
String message=new String(delivery.getBody());
System.out.println(message);
};
CancelCallback cancelCallback=(consumerTag)->{
System.out.println("消息消费被取消");
};
/* 消费者消费消息
* 1.消费哪个队列
* 2.消费成功之后是否要自动应答 true 代表自动应答 false 手动应答
* 3.消费者未成功消费的回调
* 4.消费者取消消费的回调
*/
channel.basicConsume(QUEUE_NAME,true,deliverCallback,cancelCallback);
}catch (Exception e){
e.printStackTrace();
}
}
}
4.工作队列模式

生产者
public class Producer {
public static void main(String[] args) throws IOException, InterruptedException {
Channel channel=RabbitMQChannelUtil.getChannel();
if(channel == null){
System.out.println("失败");
return;
}
channel.queueDeclare(RabbitMQChannelUtil.QUEUE_NAME,false,false,false,null);
int i=0;
while (true){
String message="消息"+i;
i++;
/**
* 发送一个消息
* 1.发送到那个交换机
* 2.路由的 key 是哪个
* 3.其他的参数信息
* 4.发送消息的消息体
*/
channel.basicPublish("",RabbitMQChannelUtil.QUEUE_NAME,null,message.getBytes());
System.out.println(message);
Thread.sleep(500);
}
}
}
消费者
public class Consumer {
public static void main(String[] args) {
Channel channel=RabbitMQChannelUtil.getChannel();
if(channel == null){
System.out.println("消费失败");
return;
}
DeliverCallback deliverCallback=(consumerTag, delivery)->{
String message=new String(delivery.getBody());
System.out.println(Thread.currentThread().getName()+"消费了"+message);
};
CancelCallback cancelCallback=(consumerTag)->{
System.out.println("消息消费被取消");
};
Thread[] threads=new Thread[5];
for (int i = 0; i <threads.length ; i++) {
threads[i]=new Thread(()->{
try {
System.out.println(Thread.currentThread().getName()+"启动等待消费");
channel.basicConsume(RabbitMQChannelUtil.QUEUE_NAME,true,deliverCallback,cancelCallback);
} catch (IOException e) {
e.printStackTrace();
}
});
}
for (int i = 0; i <threads.length ; i++) {
threads[i].start();
}
}
}
5.消息应答机制
认识
消费者处理消息时,可能在处理过程中挂掉,那么消息就会丢失为了保证消息在发送过程中不丢失,rabbitmq 引入消息应答机制,消息应答就是:消费者在接收到消息并且处理该消息之后,告诉 rabbitmq 它已经处理了rabbitmq 可以把该消息删除了。
自动应答
消息发送后立即被认为已经传送成功,这种模式需要在高吞吐量和数据传输安全性方面做权衡,因为这种模式如果消息在接收到之前,消费者那边出现连接或者 channel 关闭,那么消息就丢失了
手动应答
- Channel.basicAck(用于肯定确认)
RabbitMQ 已知道该消息并且成功的处理消息,可以将其丢弃了
- Channel.basicNack(用于否定确认)
- Channel.basicReject(用于否定确认)
与 Channel.basicNack 相比少一个参数,不处理该消息了直接拒绝,可以将其丢弃了
Channel.basicNack参数中Multiple(批量应答) 的解释
multiple 的 true 和 false 代表不同意思
- true 代表批量应答 channel 上未应答的消息
比如说 channel 上有传送 tag 的消息 5,6,7,8 当前 tag 是 8 那么此时
5-8 的这些还未应答的消息都会被确认收到消息应答
- false
只会应答 tag=8 的消息 5,6,7 这三个消息依然不会被确认收到消息应答

消息手动应答的代码
- 将手动应答开启
/* 消费者消费消息 * 1.消费哪个队列 * 2.消费成功之后是否要自动应答 true 代表自动应答 false 手动应答 * 3.当一个消息发送过来后的回调接口 * 4.消费者取消消费的回调 */ boolean ack=false; channel.basicConsume(QUEUE_NAME,ack,deliverCallback,cancelCallback);
- 消息消费回调时,使用手动应答
/**
* 消息发送过来后的回调接口
*1.同一个会话, consumerTag 是固定的 可以做此会话的名字, deliveryTag 每次接收消息+1,可以做此消息处理通道的名字。
*2.消息类
*/
DeliverCallback deliverCallback=(consumerTag,delivery)->{
String message=new String(delivery.getBody());
System.out.println(message);
/**
* 参数说明
* 1.消息的标记tag
* 2.是否批量应答
*/
channel.basicAck(delivery.getEnvelope().getDeliveryTag(),false);
};
消息自动进行重新入队
如果消费者由于某些原因失去连接(其通道已关闭,连接已关闭或 TCP 连接丢失),导致消息未发送 ACK 确认,RabbitMQ 将了解到消息未完全处理,并将对其重新排队。如果此时其他消费者可以处理,它将很快将其重新分发给另一个消费者。这样,即使某个消费者偶尔死亡,也可以确保不会丢失任何消息。

6.RabbitMQ的持久化,不公平分发及预取值
概念
刚刚我们已经看到了如何处理任务不丢失的情况,但是如何保障当 RabbitMQ 服务停掉以后消息生产者发送过来的消息不丢失。默认情况下 RabbitMQ 退出或由于某种原因崩溃时,它忽视队列和消息,除非告知它不要这样做。确保消息不会丢失需要做两件事:我们需要将队列和消息都标记为持久化。
队列持久化
- 之前我们创建的队列都是非持久化的,rabbitmq 如果重启的化,该队列就会被删除掉,如果要队列实现持久化 需要在声明队列的时候把 durable(第二个) 参数设置为持久化
- 但是需要注意的就是如果之前声明的队列不是持久化的,需要把原先队列先删除,或者重新创建一个持久化的队列,不然就会出现错误
channel.queueDeclare(RabbitMQChannelUtil.QUEUE_NAME,true,false,false,null);

这个就是持久化队列
消息持久化
- 要想让消息实现持久化需要在消息生产者修改代码,MessageProperties.PERSISTENT_TEXT_PLAIN 添加这个属性。
队列持久化为false时:
channel.basicPublish("",RabbitMQChannelUtil.QUEUE_NAME,null,message.getBytes());
队列持久化为true时
channel.basicPublish("",RabbitMQChannelUtil.QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
- 将消息标记为持久化并不能完全保证不会丢失消息。尽管它告诉 RabbitMQ 将消息保存到磁盘,但是
这里依然存在当消息刚准备存储在磁盘的时候 但是还没有存储完,消息还在缓存的一个间隔点。此时并没
有真正写入磁盘。持久性保证并不强.更强的持久化后面发布确认会讲到
不公平分发
在最开始的时候我们学习到 RabbitMQ 分发消息采用的轮训分发,但是在某种场景下这种策略并不是很好,比方说有两个消费者在处理任务,其中有个消费者 1 处理任务的速度非常快,而另外一个消费者 2处理速度却很慢,这个时候我们还是采用轮训分发的化就会到这处理速度快的这个消费者很大一部分时间处于空闲状态,而处理慢的那个消费者一直在干活,这种分配方式在这种情况下其实就不太好,但是RabbitMQ 并不知道这种情况它依然很公平的进行分发。
为了避免这种情况,我们设置不公平分发:
channel.basicQos(1);

预取值
本身消息的发送就是异步发送的,所以在任何时候,channel 上肯定不止只有一个消息另外来自消费者的手动确认本质上也是异步的。因此这里就存在一个未确认的消息缓冲区,因此希望开发人员能限制此缓冲区的大小,以避免缓冲区里面无限制的未确认消息问题。这个时候就可以通过使用 basic.qos 方法设置“预取计数”值来完成的。该值定义通道上允许的未确认消息的最大数量。一旦数量达到配置的数量,RabbitMQ 将停止在通道上传递更多消息,除非至少有一个未处理的消息被确认
prefetch就是预取值数

7.发布确认
上文持久化中提到,当消息持久化存入RabbitMQ磁盘时,RabbitMQ突然宕机,则消息未成功存入,会发生消息丢失。所以发布确认即:在消息成功存入磁盘时,返还给生产者一个消息,确认已经存入磁盘
具体介绍
生产者将信道设置成 confirm 模式,一旦信道进入 confirm 模式,所有在该信道上面发布的消息都将会被指派一个唯一的 ID(从 1 开始),一旦消息被投递到所有匹配的队列之后,broker就会发送一个确认给生产者(包含消息的唯一 ID),这就使得生产者知道消息已经正确到达目的队列了,如果消息和队列是可持久化的,那么确认消息会在将消息写入磁盘之后发出,broker 回传
给生产者的确认消息中 delivery-tag 域包含了确认消息的序列号,此外 broker 也可以设置basic.ack 的 multiple 域,表示到这个序列号之前的所有消息都已经得到了处理。
为了保证消息不丢失:
- 开启队列持久化
- 开启消息持久化
- 开启信道的发布确认
开启发布确认的方法
channel.confirmSelect();
发布确认的模式
单个确认发布
public static void singleConfirm(){
try {
Channel channel=RabbitMQChannelUtil.getChannel();
if(channel == null){
System.out.println("信道建立失败");
return;
}
//开启发布确认
channel.confirmSelect();
long begin=System.currentTimeMillis();
for (int i = 0; i <MESSAGE_COUNT ; i++) {
String message=i+"";
channel.basicPublish("",QUEUE_NAME,null,message.getBytes());
//可以加时间参数,当消息发送失败或超过参数时间没成功,则返回false
boolean flag=channel.waitForConfirms();
//如果失败可以重发
if(flag){
System.out.println(message+"发送成功");
}else {
//这里可以实现重发
System.out.println(message+"发送失败");
}
}
long end=System.currentTimeMillis();
System.out.println("发送"+MESSAGE_COUNT+"条消息,耗时"+(end-begin)+"ms");
}catch (Exception e){
e.printStackTrace();
}
}
发布一个消息之后只有它被确认发布,后续的消息才能继续发布,waitForConfirmsOrDie(long)这个方法只有在消息被确认的时候才返回,如果在指定时间范围内这个消息没有被确认那么它将抛出异常。
缺点:速度太慢
2.批量发布确认模式
public static void batchConfirm(){
try {
Channel channel=RabbitMQChannelUtil.getChannel();
if(channel == null){
System.out.println("建立连接失败");
return;
}
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//当100条消息发布成功时,再确认
int ackMessageCount=100;
//未确认的消息个数
int needAckMessageCount=0;
//开启发布确认
channel.confirmSelect();
long begin=System.currentTimeMillis();
for (int i = 0; i <MESSAGE_COUNT ; i++) {
String message=i+"";
channel.basicPublish("",QUEUE_NAME,null,message.getBytes());
needAckMessageCount++;
if(needAckMessageCount == ackMessageCount){
//确认
channel.waitForConfirms();
needAckMessageCount=0;
}
}
//判断可能还有消息未发送,再发送依次
if(needAckMessageCount > 0){
channel.waitForConfirms();
}
long end= System.currentTimeMillis();
System.out.println("发送"+MESSAGE_COUNT+"条消息,耗时"+(end-begin)+"ms");
}catch (Exception e){
e.printStackTrace();
}
}
缺点:当发生故障导致发布出现问题时,不知道是哪个消息出现问题
3.异步确认发布
原理
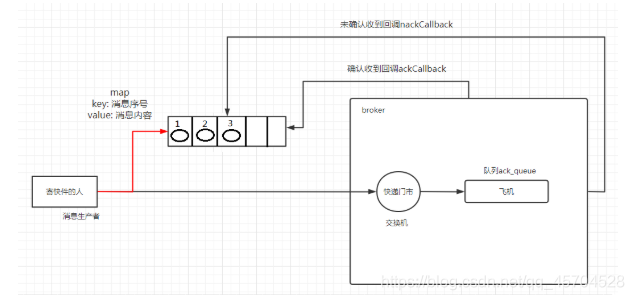
有单独一个队列保存确认信号
public static void asyncConfirm() throws Exception {
try (Channel channel = RabbitMQChannelUtil.getChannel()) {
if(channel == null){
return;
}
channel.queueDeclare(QUEUE_NAME, false, false, false, null);
//开启发布确认
channel.confirmSelect();
/**
* 线程安全有序的一个哈希表,适用于高并发的情况
* 1.轻松的将序号与消息进行关联
* 2.轻松批量删除条目 只要给到序列号
* 3.支持并发访问
*/
ConcurrentSkipListMap<Long, String> outstandingConfirms = new
ConcurrentSkipListMap<>();
/**
* 确认收到消息的一个回调
* 1.消息序列号
* 2.true 可以确认小于等于当前序列号的消息
* false 确认当前序列号消息
*/
ConfirmCallback ackCallback = (sequenceNumber, multiple) -> {
if (multiple) {
//返回的是小于等于当前序列号的未确认消息 是一个 map
ConcurrentNavigableMap<Long, String> confirmed =
outstandingConfirms.headMap(sequenceNumber, true);
//清除该部分未确认消息
confirmed.clear();
}else{
//只清除当前序列号的消息
outstandingConfirms.remove(sequenceNumber);
}
};
ConfirmCallback nackCallback = (sequenceNumber, multiple) -> {
String message = outstandingConfirms.get(sequenceNumber);
System.out.println("发布的消息"+message+"未被确认,序列号"+sequenceNumber);
};
/**
* 添加一个异步确认的监听器
* 1.确认收到消息的回调
* 2.未收到消息的回调
*/
channel.addConfirmListener(ackCallback, null);
long begin = System.currentTimeMillis();
for (int i = 0; i < MESSAGE_COUNT; i++) {
String message = "消息" + i;
/**
* channel.getNextPublishSeqNo()获取下一个消息的序列号
* 通过序列号与消息体进行一个关联
* 全部都是未确认的消息体
*/
outstandingConfirms.put(channel.getNextPublishSeqNo(), message);
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
}
long end = System.currentTimeMillis();
System.out.println("发布" + MESSAGE_COUNT + "个异步确认消息,耗时" + (end - begin) +
"ms");
}
}
8.交换机
<1>交换机的认识
1.1 概念
RabbitMQ 消息传递模型的核心思想是: 生产者生产的消息从不会直接发送到队列。实际上,通常生产者甚至都不知道这些消息传递传递到了哪些队列中。
相反,生产者只能将消息发送到交换机(exchange),交换机工作的内容非常简单,一方面它接收来自生产者的消息,另一方面将它们推入队列。交换机必须确切知道如何处理收到的消息。是应该把这些消息放到特定队列还是说把他们到许多队列中还是说应该丢弃它们。这就的由交换机的类型来决定。

1.2Exchanges 的类型
总共有以下类型:
直接(direct), 主题(topic) ,标题(headers) , 扇出(fanout)
1.3无名Exchange
channel.basicPublish("", QUEUE_NAME, null, message.getBytes());
第一个参数是交换机的名称。空字符串表示默认或无名称交换机:消息能路由发送到队列中其实
是由 routingKey(bindingkey)绑定 key 指定的,如果它存在的话
1.4临时队列
每当我们连接到 Rabbit 时,我们都需要一个全新的空队列,为此我们可以创建一个具有随机名称的队列,或者能让服务器为我们选择一个随机队列名称那就更好了。其次一旦我们断开了消费者的连接,队列将被自动删除。
String queueName = channel.queueDeclare().getQueue();
1.5队列和交换机之间的绑定
String queueName = channel.queueDeclare().getQueue();
<2>交换机具体介绍
Fanout 删除(广播)
将接收到的所有消息广播到它知道的所有队列中。
Direct (直接)
将详细发送到对应路由键的队列上去

在上面这张图中,我们可以看到 X 绑定了两个队列,绑定类型是 direct。队列 Q1 绑定键为 orange,队列 Q2 绑定键有两个:一个绑定键为 black,另一个绑定键为 green.
在这种绑定情况下,生产者发布消息到 exchange 上,绑定键为 orange 的消息会被发布到队列Q1。绑定键为 blackgreen 和的消息会被发布到队列 Q2,其他消息类型的消息将被丢弃。
绑定
//声明交换机名称及类型 channel.exchangeDeclare(EXCHANGE_NAME, "fanout"); //把该临时队列绑定我们的 exchange 其中 routingkey(也称之为 binding key)为空字符串 channel.queueBind(queueName, EXCHANGE_NAME, "");
Topics(主题)
- 尽管使用 direct 交换机改进了我们的系统,但是它仍然存在局限性-比方说我们想接收的日志类型有info.base 和 info.advantage,某个队列只想 info.base 的消息,那这个时候 direct 就办不到了。这个时候就只能使用 topic 类型
- 发送到类型是 topic 交换机的消息的 routing_key 不能随意写,必须满足一定的要求,它**必须是一个单词列表,以点号分隔开。这些单词可以是任意单词。但这个单词列表最多不能超过 255 个字节。
- 可以代替一个单词
- 可以替代零个或多个单词

9.死信队列
<1>认识死信队列
概念
- 死信,顾名思义就是无法被消费的消息,字面意思可以这样理解,一般来说,producer 将消息投递到 broker 或者直接到 queue 里了,consumer 从 queue 取出消息进行消费,但某些时候由于特定的原因导致 queue中的某些消息无法被消费,这样的消息如果没有后续的处理,就变成了死信,有死信自然就有了死信队列。
- 应用场景:为了保证订单业务的消息数据不丢失,需要使用到 RabbitMQ 的死信队列机制,当消息消费发生异常时,将消息投入死信队列中.还有比如说: 用户在商城下单成功并点击去支付后在指定时间未支付时自动失效
来源
- 消息超出最大存活时间过期队
- 列达到最大长度(队列满了,无法再添加数据到 mq 中)
- 消息被拒绝(basic.reject 或 basic.nack)并且 requeue=false.
<2>死信实战
2.1架构图

2.2TTL模拟死信队列
生产者
public class Producer {
private static final String NORMAL_EXCHANGE="normal_exchange";
public static void main(String[] args) {
try {
Channel channel= RabbitMQChannelUtil.getChannel();
if(channel == null){
return;
}
//声明交换机类型
channel.exchangeDeclare(NORMAL_EXCHANGE, BuiltinExchangeType.DIRECT);
//设置消息TTL时间
AMQP.BasicProperties basicProperties=new AMQP.BasicProperties().builder().expiration("1000").build();
//用作演示消息队列的限制个数
for (int i = 0; i <10 ; i++) {
String message="info"+i;
channel.basicPublish(NORMAL_EXCHANGE,"zhangsan",basicProperties,message.getBytes());
System.out.println("生产者发送消息");
}
}catch (Exception e){
e.printStackTrace();
}
}
}
普通消费者:启动之后关闭,模拟接收不到消息
public class NormalConsumer {
//普通交换机名称
private static final String NORMAL_EXCHANGE = "normal_exchange";
//死信交换机名称
private static final String DEAD_EXCHANGE = "dead_exchange";
public static void main(String[] argv) throws Exception {
Channel channel = RabbitMQChannelUtil.getChannel();
if(channel == null){
return;
}
//声明死信和普通交换机 类型为 direct
channel.exchangeDeclare(NORMAL_EXCHANGE, BuiltinExchangeType.DIRECT);
channel.exchangeDeclare(DEAD_EXCHANGE, BuiltinExchangeType.DIRECT);
//声明死信队列
String deadQueue = "dead-queue";
channel.queueDeclare(deadQueue, false, false, false, null);
//死信队列绑定死信交换机与 routingkey
channel.queueBind(deadQueue, DEAD_EXCHANGE, "lisi");
//正常队列绑定死信队列信息
Map<String, Object> params = new HashMap<>();
//正常队列设置死信交换机 参数 key 是固定值
params.put("x-dead-letter-exchange", DEAD_EXCHANGE);
//正常队列设置死信 routing-key 参数 key 是固定值
params.put("x-dead-letter-routing-key", "lisi");
String normalQueue = "normal-queue";
channel.queueDeclare(normalQueue, false, false, false, params);
channel.queueBind(normalQueue, NORMAL_EXCHANGE, "zhangsan");
System.out.println("等待接收消息.....");
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println("NormalConsumer 接收到消息"+message);
};
channel.basicConsume(normalQueue, true, deliverCallback, consumerTag -> {
});
}
}
死信队列消费者
public class DeadConsumer {
private static final String DEAD_EXCHANGE = "dead_exchange";
public static void main(String[] argv) throws Exception {
Channel channel = RabbitMQChannelUtil.getChannel();
if (channel == null) {
return;
}
channel.exchangeDeclare(DEAD_EXCHANGE, BuiltinExchangeType.DIRECT);
String deadQueue = "dead-queue";
channel.queueDeclare(deadQueue, false, false, false, null);
channel.queueBind(deadQueue, DEAD_EXCHANGE, "lisi");
System.out.println("等待接收死信队列消息.....");
DeliverCallback deliverCallback = (consumerTag, delivery) -> {
String message = new String(delivery.getBody(), "UTF-8");
System.out.println("DeadConsumer 接收死信队列的消息" + message);
};
channel.basicConsume(deadQueue, true, deliverCallback, consumerTag -> {
});
}
另外两种思路相同.
到此这篇关于RabbitMQ的基础知识的文章就介绍到这了,更多相关RabbitMQ基础内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

RabbitMQ交换机与Springboot整合的简单实现
RabbitMQ-交换机 1.交换机是干什么的? 消息(Message)由Client发送,RabbitMQ接收到消息之后通过交换机转发到对应的队列上面.Worker会从队列中获取未被读取的数据处理. 1.交换机的种类 RabbitMQ包含四种不同的交换机类型: Direct exchange:直连交换机,转发消息到routigKey指定的队列 Fanout exchange:扇形交换机,转发消息到所有绑定队列(速度最快) Topic exchange:主题交换机,按规则转发消息(最灵活) He
-
RabbitMQ 的七种队列模式和应用场景
七种模式介绍与应用场景 简单模式(Hello World) 做最简单的事情,一个生产者对应一个消费者,RabbitMQ相当于一个消息代理,负责将A的消息转发给B 应用场景:将发送的电子邮件放到消息队列,然后邮件服务在队列中获取邮件并发送给收件人 工作队列模式(Work queues) 在多个消费者之间分配任务(竞争的消费者模式),一个生产者对应多个消费者,一般适用于执行资源密集型任务,单个消费者处理不过来,需要多个消费者进行处理 应用场景:一个订单的处理需要10s,有多个订单可以同时放到消息队列
-
RabbitMQ 如何解决消息幂等性的问题
前言 关于MQ消费者的幂等性问题,在于MQ的重试机制,因为网络原因或客户端延迟消费导致重复消费.使用MQ重试机制需要注意的事项以及如何解决消费者幂等性问题以下将逐一讲解. 1. RabbitMQ自动重试机制 消费者在消费消息的时候,如果消费者业务逻辑出现程序异常,这个时候我们如何处理? 使用重试机制,RabbitMQ默认开启重试机制. 实现原理: @RabbitHandler注解 底层使用Aop拦截,如果程序(消费者)没有抛出异常,自动提交事务 如果Aop使用异常通知拦截获取到异常后,自动实现补
-
RabbitMQ的基础知识
目录 RabbitMQ 1.对MQ的介绍 2.RabbitMQ的六种模式 及工作原理 3.hello world队列 4.工作队列模式 5.消息应答机制 自动应答 手动应答 消息自动进行重新入队 6.RabbitMQ的持久化,不公平分发及预取值 7.发布确认 8.交换机 <1>交换机的认识 <2>交换机具体介绍 9.死信队列 <1>认识死信队列 <2>死信实战 RabbitMQ 1.对MQ的介绍 1.说明是MQ MQ(message queue),从字面意思
-
AngularJS实用基础知识_入门必备篇(推荐)
前言 今天来和大家学习一下AngularJS-- AngularJS 通过新的属性和表达式扩展了 HTML. AngularJS 可以构建一个单一页面应用程序. AngularJS 学习起来非常简单. 一.AngularJS指令与表达式 [AngularJS常用指令] 1.ng-app:声明Angular所管辖的区域,一般写在body或HTML上,原则上一个页面只有一个. 2.ng-model:把元素值(比如输入域的值)绑定到应用程序的变量中. eg:<input type="text&q
-
AngularJS 最常用的八种功能(基础知识)
AngularJS 使用基础知识 第一 迭代输出之ng-repeat标签 ng-repeat让table ul ol等标签和js里的数组完美结合 <ul> <li ng-repeat="person in persons"> {{person.name}} is {{person.age}} years old. </li> </ul> 你甚至可以指定输出的顺序: <li ng-repeat="person in pers
-
PHP小白必须要知道的php基础知识(超实用)
很多人看到PHP就以为是程序员,就以为钱很多(虽然是事实),但是也要考虑下自己是不是适合这一行,知道PHP是什么吗?PHP都有什么样的功能,都能用来干嘛? PHP是什么? •PHP(PHP: Hypertext Preprocessor,超文本预处理器的缩写),是一 种被广泛应用的开放源代码的.基于服务器端的用于产生动态网页 的.可嵌入HTML中的脚本程序语言,尤其适合 WEB 开发. •当客户端向服务器的程序提出请求时,web服务器根据请求晌应对应 的页面,当页面中含有php脚本时,服务器会交
-
ASP新手必备的基础知识
我们都知道,ASP是Active Server Page的缩写,意为"动态服务器页面".ASP是微软公司开发的代替CGI脚本程序的一种应用,它可以与数据库和其它程序进行交互,是一种简单.方便的编程工具.下面介绍一些基本知识,供大家参考. 一.数据库连接 以下为引用的内容: <% set conn=server.createobject("adodb.connection") conn.open "driver={microsoft access dr
-
学习shell脚本之前的基础知识[图文]
日常的linux系统管理工作中必不可少的就是shell脚本,如果不会写shell脚本,那么你就不算一个合格的管理员.目前很多单位在招聘linux系统管理员时,shell脚本的编写是必考的项目.有的单位甚至用shell脚本的编写能力来衡量这个linux系统管理员的经验是否丰富.笔者讲这些的目的只有一个,那就是让你认真对待shell脚本,从一开始就要把基础知识掌握牢固,然后要不断的练习,只要你shell脚本写的好,相信你的linux求职路就会轻松的多.笔者在这一章中并不会多么详细的介绍shell脚本
-
HTTP报文及ajax基础知识
HTTP报文 客户端传递给服务器的内容 和 服务器传递给客户端的内容 都属于HTTP报文 起始行:请求起始行 响应起始行 首部:请求首部 响应首部 通用首部(请求和响应都有的) 自定义首部 主体:请求主体 响应主体 客户端传递给服务器端数据: 请求URL后面问号传参的方式传递给服务器 /getList?name=zhangsan&age=7 设置请求的首部(设置请求头信息) 设置请求主体,把传递给服务器的内容放在请求主体中传递给服务器 服务器端传递给客户端数据: 设置响应头信息 设置响应主
-
Lua中函数与面向对象编程的基础知识整理
函数 1. 基础知识 调用函数都需要写圆括号,即使没有参数,但有一种特殊例外:函数若只有一个参数且参数是字面字符串或table构造式,则圆括号可有可无,如dofile 'a.lua',f{x=10, y=20}. Lua为面向对象式的调用提供冒号操作符的特殊语法,如o.foo(o, x)等价于o:foo(x).和Javascript类似,调用函数时提供的实参数量可以与形参数量不同,若实参多了则舍弃,不足则多余的形参初始化为nil. 1.1 多重返回值 Lua允许函数返回多个结果,函数返回如ret
-
GO语言(golang)基础知识
今天说一些golang的基础知识,还有你们学习会遇到的问题,先讲解hello word 复制代码 代码如下: package main import "fmt" func main() { fmt.Println("你好,我们"); } package name 包机制,每一个独立的go程序都需要有一个package main的申明,主要是要为下边入口函数main()做申明的,import和java一样导入包用的 就是下边我们函数用的fmt.Println()
-
sql注入之必备的基础知识
什么是SQL注入(SQL Injection) 所谓SQL注入式攻击,就是攻击者把SQL命令插入到Web表单的输入域或页面请求的查询字符串,欺骗服务器执行恶意的SQL命令.在某些表单中,用户输入的内容直接用来构造(或者影响)动态SQL命令,或作为存储过程的输入参数,这类表单特别容易受到SQL注入式攻击. mysql常用注释 # --[空格]或者是--+ /*-*/ 在注意过程中,这些注释可能都需要进行urlencode. mysql认证绕过 ;%00 ' or 1=1 # ' /*!or */