pandas DataFrame 删除重复的行的实现方法
1. 建立一个DataFrame
C=pd.DataFrame({'a':['dog']*3+['fish']*3+['dog'],'b':[10,10,12,12,14,14,10]})

2. 判断是否有重复项
用duplicated( )函数判断
C.duplicated()
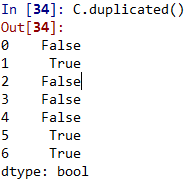
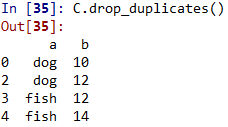
3. 有重复项,则可以用drop_duplicates()移除重复项
C.drop_duplicates()
4. Duplicated( )和drop_duplicates( )方法是以默认的方式判断全部的列(上面的例子中是看两个变量a和b是否都是重复出现)。
我们也可以对特定的列进行重复项判断。
C.duplicated(['a']) C.drop_duplicates(['a']) C.duplicated(['b']) C.drop_duplicates(['b'])

5. norepeat_df = df.drop_duplicates(subset=['A_ID', 'B_ID'], keep='first')
#上面的命令去掉UNIT_ID和KPI_ID列中重复的行,并保留重复出现的行中第一次出现的行
补充:
- 当keep=False时,就是去掉所有的重复行
- 当keep=‘first'时,就是保留第一次出现的重复行
- 当keep='last'时就是保留最后一次出现的重复行。
(注意,这里的参数是字符串,要加引号!!!)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
pandas 数据结构之Series的使用方法
1. Series Series 是一个类数组的数据结构,同时带有标签(lable)或者说索引(index). 1.1 下边生成一个最简单的Series对象,因为没有给Series指定索引,所以此时会使用默认索引(从0到N-1). # 引入Series和DataFrame In [16]: from pandas import Series,DataFrame In [17]: import pandas as pd In [18]: ser1 = Series([1,2,3,4]) In [1
-
pandas DataFrame 行列索引及值的获取的方法
pandas DataFrame是二维的,所以,它既有列索引,又有行索引 上一篇里只介绍了列索引: import pandas as pd df = pd.DataFrame({'A': [0, 1, 2], 'B': [3, 4, 5]}) print df # 结果: A B 0 0 3 1 1 4 2 2 5 行索引自动生成了 0,1,2 如果要自己指定行索引和列索引,可以使用 index 和 column 参数: 这个数据是5个车站10天内的客流数据: ridership_df = pd
-
Python Pandas数据结构简单介绍
Series Series 类似一维数组,由一组数据及一组相关数据标签组成.使用pandas的Series类即可创建. import pandas as pd s1 = pd.Series(['a', 'b', 'c,', 'd']) print(s1) #输出: 0 a # 1 b # 2 c # 3 d # dtype: object 上面是传入一个列表实现,上面的0,1,2,3就是数据的默认标签.另外可以通过index属性自定义标签. s2 = pd.Series(['1', '2', '
-
Python pandas.DataFrame调整列顺序及修改index名的方法
1. 从字典创建DataFrame >>> import pandas >>> dict_a = {'user_id':['webbang','webbang','webbang'],'book_id':['3713327','4074636','26873486'],'rating':['4','4','4'],'mark_date':['2017-03-07','2017-03-07','2017-03-07']} >>> df = pandas.
-
对pandas通过索引提取dataframe的行方法详解
一.假设有这样一个原始dataframe 二.提取索引 (已经做了一些操作将Age为NaN的行提取出来并合并为一个dataframe,这里提取的是该dataframe的索引,道理和操作是相似的,提取的代码没有贴上去是为了不显得太繁杂让读者看着繁琐) >>> index = unknown_age_Mr.index.tolist() #记得转换为list格式 三.提取索引对应的原始dataframe的行 使用iloc函数将数据块提取出 >>> age_df.iloc[in
-
浅析pandas 数据结构中的DataFrame
DataFrame 类型类似于数据库表结构的数据结构,其含有行索引和列索引,可以将DataFrame 想成是由相同索引的Series组成的Dict类型.在其底层是通过二维以及一维的数据块实现. 1. DataFrame 对象的构建 1.1 用包含等长的列表或者是NumPy数组的字典创建DataFrame对象 In [68]: import pandas as pd In [69]: from pandas import Series,DataFrame # 建立包含等长列表的字典类型 In [7
-
pandas DataFrame 删除重复的行的实现方法
1. 建立一个DataFrame C=pd.DataFrame({'a':['dog']*3+['fish']*3+['dog'],'b':[10,10,12,12,14,14,10]}) 2. 判断是否有重复项 用duplicated( )函数判断 C.duplicated() 3. 有重复项,则可以用drop_duplicates()移除重复项 C.drop_duplicates() 4. Duplicated( )和drop_duplicates( )方法是以默认的方式判断全部的列(上面
-
pandas.DataFrame删除/选取含有特定数值的行或列实例
1.删除/选取某列含有特殊数值的行 import pandas as pd import numpy as np a=np.array([[1,2,3],[4,5,6],[7,8,9]]) df1=pd.DataFrame(a,index=['row0','row1','row2'],columns=list('ABC')) print(df1) df2=df1.copy() #删除/选取某列含有特定数值的行 #df1=df1[df1['A'].isin([1])] #df1[df1['A'].
-
Pandas标记删除重复记录的方法
Pandas提供了duplicated.Index.duplicated.drop_duplicates函数来标记及删除重复记录 duplicated函数用于标记Series中的值.DataFrame中的记录行是否是重复,重复为True,不重复为False pandas.DataFrame.duplicated(self, subset=None, keep='first') pandas.Series.duplicated(self, keep='first') 其中参数解释如下: subse
-
Pandas.DataFrame删除指定行和列(drop)的实现
目录 DataFrame指定的行删除 按行名指定(行标签) 按行号指定 未设置行名的注意事项 DataFrame指定的列删除 按列名指定(列标签) 按列号指定 多行多列的删除 使用drop()方法删除pandas.DataFrame的行和列. 在0.21.0版之前,请使用参数labels和axis指定行和列.从0.21.0开始,可以使用index或columns. 在此,将对以下内容进行说明. DataFrame指定的行删除 按行名指定(行标签) 按行号指定 未设置行名的注意事项 DataFra
-
Pandas:Series和DataFrame删除指定轴上数据的方法
如下所示: import numpy as np import pandas as pd from pandas import Series,DataFrame 一.drop方法:产生新对象 1.Series o = Series([1,3,4,7],index=['d','c','b','a']) print(o.drop(['d','b'])) c 3 a 7 dtype: int64 2.DataFrame data = {'水果':['苹果','梨','草莓'], '数量':[3,2,5
-
Pandas.DataFrame重置列的行名实现(set_index)
目录 set_index()的使用方法 基本用法 将指定的列保留为数据:参数drop 分配多索引 将索引更改为另一列(重置) 更改原始对象:参数inplace 读取csv文件等时指定索引 使用索引(行名)提取(选择)行和元素 pandas.DataFrame中的现有列分配给索引index(行名,行标签).为索引指定唯一的名称很方便,因为使用loc,at选择(提取)元素时很容易理解. 将描述以下内容. set_index()的使用方法 基本用法 将指定的列保留为数据:参数drop 分配多索引 将索
-
Mysql一些复杂的sql语句(查询与删除重复的行)
1.查找重复的行 SELECT * FROM blog_user_relation a WHERE (a.account_instance_id,a.follow_account_instance_id) IN (SELECT account_instance_id,follow_account_instance_id FROM blog_user_relation GROUP BY account_instance_id, follow_account_instance_id HAVING C
-
使用python读取txt文件的内容,并删除重复的行数方法
注意,本文代码是使用在txt文档上,同时txt文档中的内容每一行代表的是图片的名字. #coding:utf-8 import shutil readDir = "原文件绝对路经" writeDir = "写入文件的绝对路径" #txtDir = "/home/fuxueping/Desktop/1" lines_seen = set() outfile=open(writeDir,"w") f = open(readDir,
-
pandas.DataFrame选取/排除特定行的方法
pandas.DataFrame选取特定行 使用Python进行数据分析时,经常要使用到的一个数据结构就是pandas的DataFrame,如果我们想要像Excel的筛选那样,只要其中的一行或某几行,可以使用isin()方法,将需要的行的值以列表方式传入,还可以传入字典,指定列进行筛选. >>> df = pd.DataFrame([['GD', 'GX', 'FJ'], ['SD', 'SX', 'BJ'], ['HN', 'HB', 'AH'], ['HEN', 'HEN', 'HL
-
Python中pandas dataframe删除一行或一列:drop函数详解
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 在这里默认:axis=0,指删除index,因此删除columns时要指定axis=1: inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe: inplace=True,则会直接在原数据上进行删除操作,删除后就回不来了. 例子: >>>df = pd.DataFrame(np.a
随机推荐
- AngularJS报错$apply already in progress的解决方法分析
- Angular.js中用ng-repeat-start实现自定义显示
- jQuery插件FusionCharts实现的MSBar2D图效果示例【附demo源码】
- jquery eval解析JSON中的注意点介绍
- ISAPI-REWRITE伪静态规则写法以及说明
- certutil - decode/encode BASE64/HEX strings.Print symbols by HEX code
- 详解ubuntu 16.04安装docker教程
- Oracle动态交叉表生成
- JavaScript分析、压缩工具JavaScript Analyser
- ASP.NET环境下为网站增加IP过滤功能第1/2页
- PHP curl实现抓取302跳转后页面的示例
- android开发之蜂鸣提示音和震动提示的实现原理与参考代码
- 利用XMLSerializer将对象串行化到XML
- Android 使用Vitamio打造自己的万能播放器(10)—— 本地播放 (缩略图、视频信息、视频扫描服务)
- 穷人和富人的经典差异分析 督促现在的自己
- jquery实现删除一个元素后面的所有元素功能
- Android自定义view实现圆形、圆角和椭圆图片(BitmapShader图形渲染)
- 浅谈addEventListener和attachEvent的区别
- apache配置php实现单一入口方法
- java类中生成jfreechart,返回图表的url地址 代码分享