Python数据分析与处理(一)--北京高考分数线统计分析
目录
- 1.1 数据爬取
- 1.2 最高分最低分统计
- 1.3 一本二本理科差值统计
- 1.4 2006—2019年近14年每科分数线的平均值统计
前言:
为了帮助广大考生和家长了解高考历年的录取情况,很多网站都汇总了各省市的录取控制分数线,为广大考生填报志愿提供参考。因受多种因素影响,每年的分数线或多或少会有一些变动。采集北京2006-2019年的信息。使用Python的Pandas库完成以下数据分析。
1.1 数据爬取
包含三部分内容:从哪里爬取,如何爬取,爬取的结果
代码:
import pandas as pd
import numpy as np
data=pd.read_excel("scores.xlsx",header=1)
print(data)
运行结果:
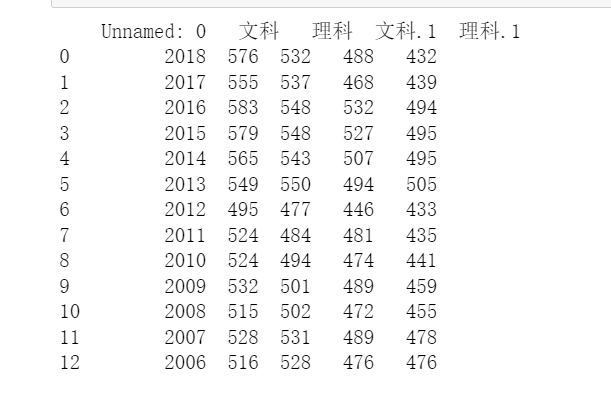
分析:我是读取的本地的数据文件进行的数据分析。
有兴趣的话可以从网站上面下载相关的数据或者是自己使用爬虫爬取相关的数据源。进行数据分析
这个数据的分析部分我主要是采用的是Pandas numpy做数据的预处理。
和matplotlib进行数据的可视化展示。
1.2 最高分最低分统计
mindata= data.groupby(['文科','理科'], as_index=False).min(axis=1) maxdata= data.groupby(['文科','理科'], as_index=False).max(axis=2) print(data.min()) print(data.max())
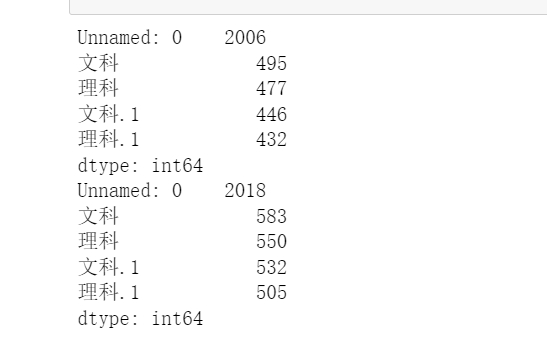
进行数据的处理,最高分最低分统计,因为有两个不同的年份的成绩,并且分了文科和理科所以就有2个文科2个理科
- 我们使用
groupby按照文理科进行分组 - 然后使用
max()和min()求最大值和最小值‘ - 经过分析处理可以看到打印出来的最大值和最小值
1.3 一本二本理科差值统计
代码:
s1math=data["一本分数线","理科"] print(s1math) print(s1math[0]-s1math[2]) s1c=data["一本分数线","文科"] print(s1c[0]-s1c[2]) s2math=data["二本分数线","理科"] print(s2math[0]-s2math[2]) s2c=data["二本分数线","文科"] print(s2math[0]-s2math[2])
运行结果:
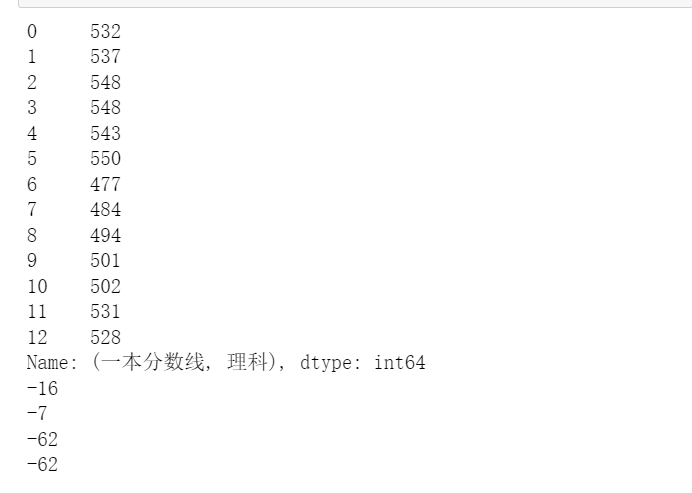
注意:
首先我们取出相应的文理科一本以及二本的成绩,然后再进行相关的极差的计算就是使用前一个数减去后面的一个数就OK。
print(s1math[0]-s1math[2])
1.4 2006—2019年近14年每科分数线的平均值统计
代码:
# 2006—2019年近14年每科分数线的平均值统计 data1=data[data['Unnamed: 0'].between(2006, 2014, inclusive=True)].groupby(['Unnamed: 0']).mean() print(data1)
运行结果:
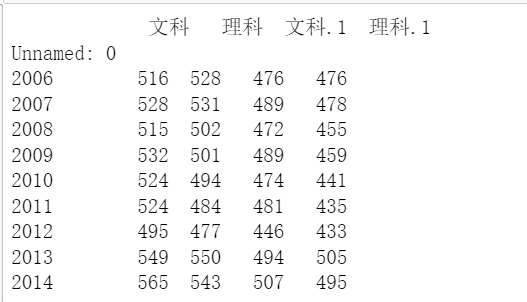
首先是进行数据的提取,然后进行平均值的求取。在这里我算的麻烦了,因为本来就是一个年份对应的是一个成绩。不是一对多的关系,所以下面的方法要更好一些。
也可以使用mean方法进行相关的平均值求取。
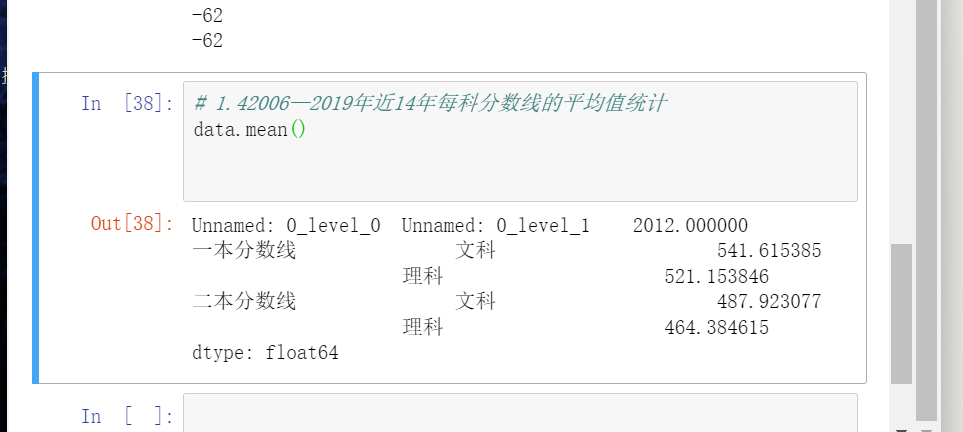
是一个成绩。不是一对多的关系,所以下面的方法要更好一些。
也可以使用mean方法进行相关的平均值求取。
到此这篇关于Python数据分析与处理北京高考分数线统计分析的文章就介绍到这了,更多相关Python数据分析与处理内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python数据分析的八种处理缺失值方法详解
目录 1. 删除有缺失值的行或列 2. 删除只有缺失值的行或列 3. 根据阈值删除行或列 4. 基于特定的列子集删除 5. 填充一个常数值 6. 填充聚合值 7. 替换为上一个或下一个值 8. 使用另一个数据框填充 总结 技术交流 在本文中,我们将介绍 8 种不同的方法来解决缺失值问题,哪种方法最适合特定情况取决于数据和任务.欢迎收藏学习,喜欢点赞支持,技术交流可以文末加群,尽情畅聊. 让我们首先创建一个示例数据框并向其中添加一些缺失值. 我们有一个 10 行 6 列的数据框. 下一步是添加缺失
-
python使用dabl几行代码实现数据处理分析及ML自动化
目录 dabl 1.数据预处理 2.探索性数据分析 3.建模 结论 数据科学模型开发涉及各种组件,包括数据收集.数据处理.探索性数据分析.建模和部署.在训练机器学习或深度学习模型之前,必须清洗数据集并使其适合训练.通常这些过程是重复的,且占用了大部时间. 为了克服这个问题,今天我分享一个名为 dabl 的开源 Python 工具包,它可以自动化机器学习模型开发,包括数据预处理.特征可视化和分析.建模.欢迎收藏学习,喜欢点赞支持. dabl dabl 是一个数据分析基线库,可以让机器学习建模更容易
-
Python数据分析之缺失值检测与处理详解
目录 检测缺失值 缺失值处理 删除缺失值 填补缺失值 检测缺失值 我们先创建一个带有缺失值的数据框(DataFrame). import pandas as pd df = pd.DataFrame( {'A': [None, 2, None, 4], 'B': [10, None, None, 40], 'C': [100, 200, None, 400], 'D': [None, 2000, 3000, None]}) df 数值类缺失值在 Pandas 中被显示为 NaN (Not A N
-
利用python数据分析处理进行炒股实战行情
作为一个新手,你需要以下3个步骤: 1.用户注册 > 2.获取token > 3.调取数据 数据内容: 包含股票.基金.期货.债券.外汇.行业大数据, 同时包括了数字货币行情等区块链数据的全数据品类的金融大数据平台, 为各类金融投资和研究人员提供适用的数据和工具. 1.数据采集 我们进行本地化计算,首先要做的,就是将所需的基础数据采集到本地数据库里 本篇的示例源码采用的数据库是MySQL5.5,数据源是xxx pro接口. 我们现在要取一批特定股票的日线行情 部分代码如下: # 设置xxxxx
-
30 个 Python 函数,加速数据分析处理速度
目录 1.删除列 2.选择特定列 3.nrows 4.样品 5.检查缺失值 6.使用 loc 和 iloc 添加缺失值 7.填充缺失值 8.删除缺失值 9.根据条件选择行 10.用查询描述条件 11.用 isin 描述条件 12.Groupby 函数 13.Groupby与聚合函数结合 14.对不同的群体应用不同的聚合函数 15.重置索引 16.重置并删除原索引 17.将特定列设置为索引 18.插入新列 19.where 函数 20.等级函数 21.列中的唯一值数 22.内存使用情况 23.数据
-
Python数据分析与处理(一)--北京高考分数线统计分析
目录 1.1 数据爬取 1.2 最高分最低分统计 1.3 一本二本理科差值统计 1.4 2006-2019年近14年每科分数线的平均值统计 前言: 为了帮助广大考生和家长了解高考历年的录取情况,很多网站都汇总了各省市的录取控制分数线,为广大考生填报志愿提供参考.因受多种因素影响,每年的分数线或多或少会有一些变动.采集北京2006-2019年的信息.使用Python的Pandas库完成以下数据分析. 1.1 数据爬取 包含三部分内容:从哪里爬取,如何爬取,爬取的结果 代码: import pand
-
数据分析2020年全国各省高考成绩分布情况
开始 突发奇想, 想看下高考成绩的分布, 如果把每个省市的成绩划线成0-100 分会怎么样,简单的来说, 认为最高分的考了100分,最低分考了0分, 计算一下各个分数段的人数就好了, 顺便可以用这个数据看每个省市的一本线划分比率,还有其他相关的数据, 看起来还是比较简单的, 动手试试 数据收集 网上找了一下, 每年的高考人数, 现在已经超过千万人高考了,河南更是超过了100万, 数据来源:新浪教育 https://edu.sina.cn/zt_d/gkbm 省/市 2020年 2019年 201
-
Python和Perl绘制中国北京跑步地图的方法
当你在一个城市,穿越大街小巷,跑步跑了几千公里之后,一个显而易见的想法是,我到底和之前比快了多少,跑量有何变化,如果能把在这个城市的所有路线全部画出来,会是怎样的景象呢? 1.数据来源:益动GPS 文章代码比较多,为了不吊人胃口,先看看最终效果: [/code] 首先需要有原始数据信息,手机上众多跑步软件提供了详细的记录,但它们共同的问题是不允许自由导入导出(可能是为了用户粘性吧).因此有一块智能运动手表应该是不二之选.我的是Garmin Fenix3,推荐一下: 益动GPS算是业界良心了,能够
-
Python数据分析之Python和Selenium爬取BOSS直聘岗位
一.数据爬取的代码 #encoding='utf-8' from selenium import webdriver import time import re import pandas as pd import os def close_windows(): #如果有登录弹窗,就关闭 try: time.sleep(0.5) if dr.find_element_by_class_name("jconfirm").find_element_by_class_name("c
-
Python数据分析与处理(二)——处理中国地区信息
目录 2.1数据的爬取 2.2检查重复数据 2.3检查缺失值 2.4 检查异常值 2.1数据的爬取 代码: import pandas as pd data=pd.read_csv("example_data.csv",header=1) print(data) data1=pd.read_csv("北京地区信息.csv",header=1,encoding='gbk') data2=pd.read_csv("天津地区信息.csv",encodi
-
Python数据分析之 Pandas Dataframe修改和删除及查询操作
目录 一.查询操作 元素的查询 二.修改操作 行列索引的修改 元素值的修改 三.行和列的删除操作 一.查询操作 可以使用Dataframe的index属性和columns属性获取行.列索引. import pandas as pd data = {"name": ["Alice", "Bob", "Cindy", "David"], "age": [25, 23, 28, 24], &q
-
R vs. Python 数据分析中谁与争锋?
当我们想要选择一种编程语言进行数据分析时,相信大多数人都会想到R和Python--但是从这两个非常强大.灵活的数据分析语言中二选一是非常困难的. 我承认我还没能从这两个数据科学家喜爱的语言中选出更好的那一个.因此,为了使事情变得有趣,本文将介绍一些关于这两种语言的详细信息,并将决策权留给读者.值得一提的是,有多种途径可以了解这两种语言各自的优缺点.然而在我看来,这两种语言之间其实有很强的关联. Stack Overflow趋势对比 上图显示了自从2008年(Stack Overflow 成立)以
-
Python数据分析中Groupby用法之通过字典或Series进行分组的实例
在数据分析中有时候需要自己定义分组规则 这里简单介绍一下用一个字典实现分组 people=DataFrame( np.random.randn(5,5), columns=['a','b','c','d','e'], index=['Joe','Steve','Wes','Jim','Travis'] ) mapping={'a':'red','b':'red','c':'blue','d':'blue','e':'red','f':'orange'} by_column=people.grou
-
Python数据分析之双色球统计两个红和蓝球哪组合比例高的方法
本文实例讲述了Python数据分析之双色球统计两个红和蓝球哪组合比例高的方法.分享给大家供大家参考,具体如下: 统计两个红球和蓝球,哪个组合最多,显示前19组数据 #!/usr/bin/python # -*- coding:UTF-8 -*- import pandas as pd import numpy as np import matplotlib.pyplot as plt import operator #导入数据 df = pd.read_table('newdata.txt',h
-
Python数据分析之双色球统计单个红和蓝球哪个比例高的方法
本文实例讲述了Python数据分析之双色球统计单个红和蓝球哪个比例高的方法.分享给大家供大家参考,具体如下: 统计单个红球和蓝球,哪个组合最多,显示前19组数据 #!/usr/bin/python # -*- coding:UTF-8 -*- import pandas as pd import numpy as np import matplotlib.pyplot as plt import operator df = pd.read_table('newdata.txt',header=N