java读取html文件,并获取body中所有的标签及内容的案例
这里的获取的是html文件中body中的所有标签以及内容
package com.lmt.service.file;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStreamReader;
import java.io.Reader;
import org.springframework.stereotype.Component;
import com.lmt.config.UrlConstants;
@Component
public class ParseFile {
/**
* 解析html文件
* @param file
* @return
*/
public String readHtml(File file){
String body = "";
try {
FileInputStream iStream = new FileInputStream(file);
Reader reader = new InputStreamReader(iStream);
BufferedReader htmlReader = new BufferedReader(reader);
String line;
boolean found = false;
while (!found && (line = htmlReader.readLine()) != null) {
if (line.toLowerCase().indexOf("<body") != -1) { // 在<body>的前面可能存在空格
found = true;
}
}
found = false;
while (!found && (line = htmlReader.readLine()) != null) {
if (line.toLowerCase().indexOf("</body") != -1) {
found = true;
} else {
// 如果存在图片,则将相对路径转换为绝对路径
String lowerCaseLine = line.toLowerCase();
if (lowerCaseLine.contains("src")) {
//这里是定义图片的访问路径
String directory = "D:/test";
// 如果路径名不以反斜杠结尾,则手动添加反斜杠
/*if (!directory.endsWith("\\")) {
directory = directory + "\\";
}*/
// line = line.substring(0, lowerCaseLine.indexOf("src") + 5) + directory + line.substring(lowerCaseLine.indexOf("src") + 5);
/*String filename = extractFilename(line);
line = line.substring(0, lowerCaseLine.indexOf("src") + 5) + directory + filename + line.substring(line.indexOf(filename) + filename.length());
*/
// 如果该行存在多个<img>元素,则分行进行替代
String[] splitLines = line.split("<img\\s+"); // <img后带一个或多个空格
// 因为java中引用的问题不能使用for each
for (int i = 0; i < splitLines.length; i++) {
if (splitLines[i].toLowerCase().startsWith("src")) {
splitLines[i] = splitLines[i].substring(0, splitLines[i].toLowerCase().indexOf("src") + 5)
+ directory
+ splitLines[i].substring(splitLines[i].toLowerCase().indexOf("src") + 5);
}
}
// 最后进行拼接
line = "";
for (int i = 0; i < splitLines.length - 1; i++) { // 循环次数要-1,因为最后一个字符串后不需要添加<img
line = line + splitLines[i] + "<img ";
}
line = line + splitLines[splitLines.length - 1];
}
body = body + line + "\n";
}
}
htmlReader.close();
// System.out.println(body);
} catch (Exception e) {
e.printStackTrace();
}
return body;
}
/**
*
* @param htmlLine 一行html片段,包含<img>元素
* @return 文件名
*/
public static String extractFilename(String htmlLine) {
int srcIndex = htmlLine.toLowerCase().indexOf("src=");
if (srcIndex == -1) { // 图片不存在,返回空字符串
return "";
} else {
String htmlSrc = htmlLine.substring(srcIndex + 4);
char splitChar = '\"'; // 默认为双引号,但也有可能为单引号
if (htmlSrc.charAt(0) == '\'') {
splitChar = '\'';
}
String[] firstSplit = htmlSrc.split(String.valueOf(splitChar));
String path = firstSplit[1]; // 第0位为空字符串
String[] secondSplit = path.split("[/\\\\]"); // 匹配正斜杠或反斜杠
return secondSplit[secondSplit.length - 1];
}
}
}
补充知识:StandardEngine[Catalina].StandardHost[localhost].StandardContext[]
jar包没有正确导入
1、在 build path 中添加
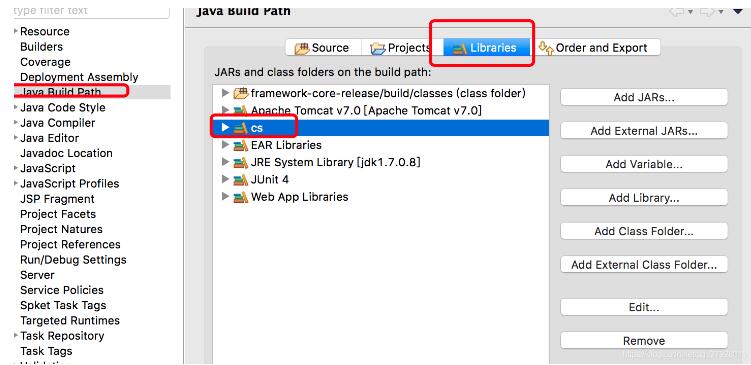
2、如果这里不添加在编译的时你的jar包将不会被导入
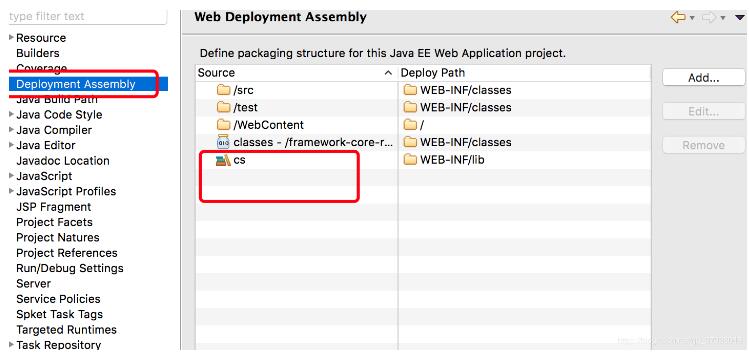
3、如果依然没有成功请删除user jar包重新导入
以上这篇java读取html文件,并获取body中所有的标签及内容的案例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Java Integer.valueOf()和Integer.parseInt()的区别说明
前言 大家都知道Integer类中有Integer.valueOf(String s)和Integer.parseInt(String s)两个静态方法,他们都能够将字符串转换为整型.说到这里你肯定会想同一个功能为什么要提供两个不同的方法,这不是浪费吗? 区别 Integer.parseInt(String s)将会返回int常量. Integer.valueOf(String s)将会返回Integer类型,如果存在缓存将会返回缓存中已有的对象. 使用不当将会产生的问题 由于Java的自动拆箱
-
Java HtmlParse提取标签中的值操作
☆代码示例: 代码块语法遵循标准markdown代码,例如: package cas; import org.htmlparser.Node; import org.htmlparser.NodeFilter; import org.htmlparser.Parser; import org.htmlparser.filters.StringFilter; import org.htmlparser.filters.TagNameFilter; import org.htmlparser.tag
-
java获取文件编码,jsoup获取html纯文本操作
maven引入获取编码的jar <dependency> <groupId>com.ibm.icu</groupId> <artifactId>icu4j</artifactId> <version>67.1</version> </dependency> 获取文件编码 package com.lovnx.note.util; import com.ibm.icu.text.CharsetDetector; i
-
Java内部类和匿名内部类的用法说明
一.内部类: (1)内部类的同名方法 内部类可以调用外部类的方法,如果内部类有同名方法必须使用"OuterClass.this.MethodName()"格式调用(其中OuterClass与MethodName换成实际外部类名及其方法:this为关键字,表示对外部类的引用):若内部类无同名方法可以直接调用外部类的方法. 但外围类无法直接调用内部类的private方法,外部类同样无法直接调用其它类的private方法.注意:内部类直接使用外部类的方法与该方法的权限与是否static无关,
-
java8新特性 stream流的方式遍历集合和数组操作
前言: 在没有接触java8的时候,我们遍历一个集合都是用循环的方式,从第一条数据遍历到最后一条数据,现在思考一个问题,为什么要使用循环,因为要进行遍历,但是遍历不是唯一的方式,遍历是指每一个元素逐一进行处理(目的),而并不是从第一个到最后一个顺次处理的循环,前者是目的,后者是方式. 所以为了让遍历的方式更加优雅,出现了流(stream)! 1.流的目的在于强掉做什么 假设一个案例:将集合A根据条件1过滤为子集B,然后根据条件2过滤为子集C 在没有引入流之前我们的做法可能为: public cl
-
java读取html文件,并获取body中所有的标签及内容的案例
这里的获取的是html文件中body中的所有标签以及内容 package com.lmt.service.file; import java.io.BufferedReader; import java.io.File; import java.io.FileInputStream; import java.io.InputStreamReader; import java.io.Reader; import org.springframework.stereotype.Component; i
-
详解Java读取本地文件并显示在JSP文件中
详解Java读取本地文件并显示在JSP文件中 当我们初学IMG标签时,我们知道通过设置img标签的src属性,能够在页面中显示想要展示的图片.其中src的值,可以是磁盘目录上的绝对,也可以是项目下的相对路径,还可以是网络上的图片路径.在存取少量图片的情况下,采用相对路径存储图片的情况下最方便,也最实用.但是当图片数量过多时,这种方式就显的有些掣肘了. 当系统的图片数量过多时,如果仍把这些图片当做项目的一部分去发布,势必会大大延长项目的发布时间及更新时间.对于某些对于时限性要求特别高的系统来说,采
-
Java读取txt文件中的数据赋给String变量方法
实例如下所示: public class MainActivity { private static final String fileName = "D:/Tao/MyEclipseWorkspace/resources/weather.txt"; public static void main(String[] args) { //读取文件 BufferedReader br = null; StringBuffer sb = null; try { br = new Buffer
-

java读取wav文件(波形文件)并绘制波形图的方法
本文实例讲述了java读取wav文件(波形文件)并绘制波形图的方法.分享给大家供大家参考.具体如下: 因为最近有不少网友询问我波形文件读写方面的问题,出于让大家更方便以及让代码能够得到更好的改进,我将这部分(波形文件的读写)代码开源在GitHub上面. 地址为https://github.com/sintrb/WaveAccess/,最新的代码.例子.文档都在那上面,我会在我时间精力允许的前提下对该项目进行维护,同时也希望对这方面有兴趣的网友能够加入到该开源项目上. 以下内容基本都过期了,你可以
-
java 读取本地文件实例详解
java 读取本地文件实例详解 用javax.xml.w3c解析 实例代码: package cn.com.xinli.monitor.utils; import org.w3c.dom.Document; import org.w3c.dom.Element; import javax.xml.parsers.DocumentBuilder; import javax.xml.parsers.DocumentBuilderFactory; import java.io.File; /** *
-
java 读取excel文件转换成json格式的实例代码
需要读取excel数据转换成json数据,写了个测试功能,转换正常: JSON转换:org.json.jar 测试类: importFile.java: package com.siemens.util; import java.util.ArrayList; import java.util.List; import org.json.JSONException; import org.json.JSONObject; import org.apache.poi.ss.usermodel.R
-
java读取cvs文件并导入数据库
本文实例为大家分享了java读取cvs文件并导入数据库的具体代码,供大家参考,具体内容如下 首先获取文件夹下面的所有类型相同的excel,可以用模糊匹配contains("匹配字段") public static List getDictory(String path) { File f = new File(path); List<String> dictories = new ArrayList<String>(); if (!f.exists()) { S
-
java读取txt文件并输出结果
这篇文章主要介绍了java读取txt文件并输出结果,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 描述: 1.java读取指定txt文件并解析 文件格式: 代码: package com.thinkgem.wlw.modules.midea; import java.io.*; import java.util.ArrayList; import java.util.List; /** * @Author: zhouhe * @Date: 20
-
Java读取Properties文件的七种方法的总结
Java读取Properties文件的方法总结 读取.properties配置文件在实际的开发中使用的很多,总结了一下,有以下几种方法: 其实很多都是大同小异,概括起来就2种: 先构造出一个InputStream来,然后调用Properties#load() 利用ResourceBundle,这个主要在做国际化的时候用的比较多. 例如:它能根据系统语言环境自动读取下面三个properties文件中的一个: resource_en_US.properties resource_zh_CN.prop
-
java读取properties文件的方法实例分析
本文实例讲述了java读取properties文件的方法.分享给大家供大家参考.具体分析如下: 1.不在项目中读取: Properties properties = new Properties(); BufferedReader read = new BufferedReader(new InputStreamReader(new FileInputStream("文件的路径"),"utf-8")); properties.load(read); properti