Python爬虫之批量下载喜马拉雅音频
一、解析网站
1.1 获取音频地址
在喜马拉雅网站上,随便点开一个音频,打开“开发者工具”,再点击播放按钮,可以看到出现了多个请求:
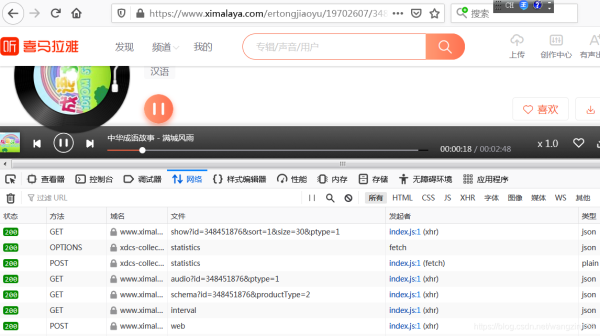
经过排查,发现可疑url:

查看它的响应信息,发现音频地址就在里面:
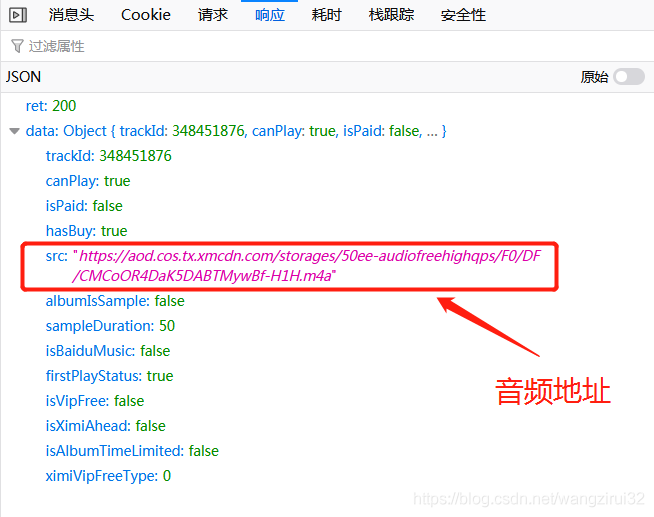
接下来,解析这个返回音频地址的url:
https://www.ximalaya.com/revision/play/v1/audio?id=348451879&ptype=1
发现url中的id参数就决定了返回的音频地址,而id参数是音频的id号。
1.2 解析专栏网页
我们已经知道了获取音频url的网址,接下来要获取一个专栏内的音频id和名称,打开一个专栏,发现:
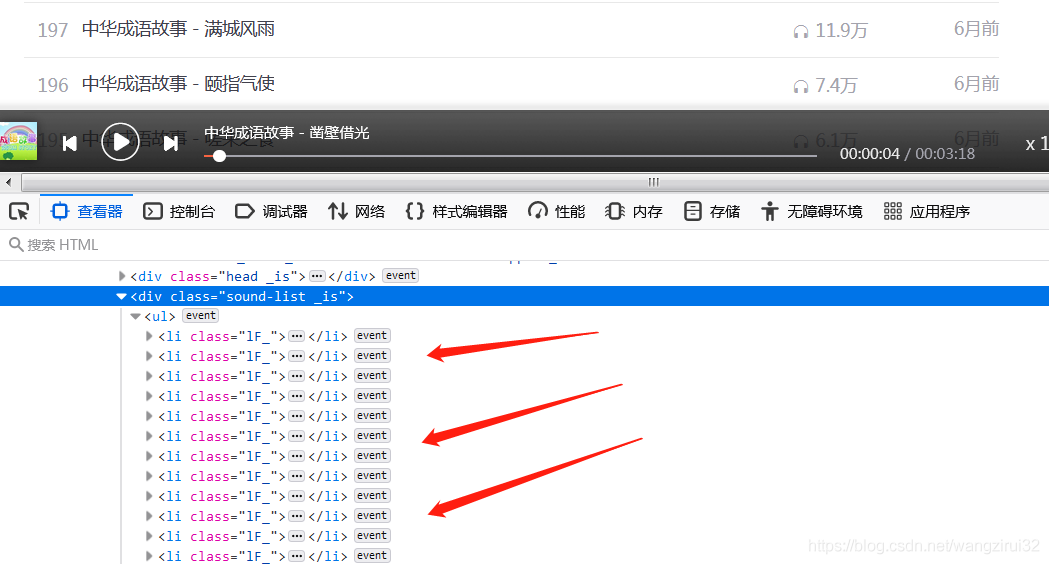
所有的音频存放在class为1F_的li标签中,再来解析li标签:
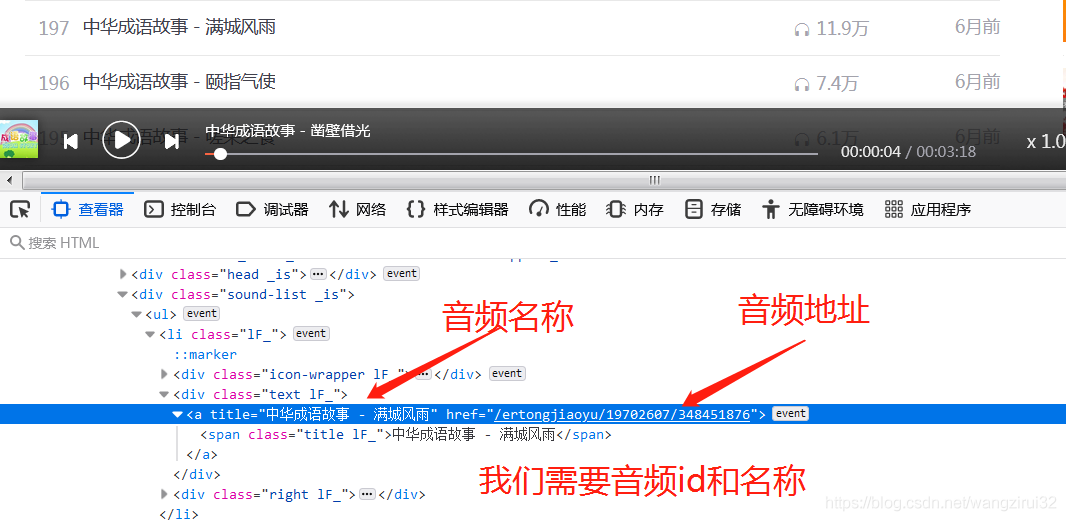
在li标签中的第一个a标签存储着我们所有需要的数据,妙~啊!
1.3 整理亿下思路
思路:
1.获取专栏内的li标签
2.获取li标签里的第一个a标签
3.读取a标签的title和href属性
4.将href解析成音频id
5.将id带入url请求音频源地址
6.提取音频源地址
7.请求音频源地址
8.保存音频(文件名为a的title属性)
思路整理完了,开始编写代码。
二、编写爬取代码
代码奉上——
import requests
from fake_useragent import UserAgent as ua
from bs4 import BeautifulSoup as bs
# 专栏地址
music_list_url = 'https://www.ximalaya.com/ertongjiaoyu/19702607/'
# 获取音频地址的url
get_link_url = "https://www.ximalaya.com/revision/play/v1/audio"
# UA伪装
headers = {
"User-Agent": ua().random
}
# 参数
params = {
"id": None, # id先设为None
"ptype": "1",
}
# 获取专栏HTML源码
music_list_r = requests.get(music_list_url, headers=headers)
# 解析 获取所有li标签
soup = bs(music_list_r.text, "lxml")
li = soup.find_all("li", {"class": "lF_"})
# for循序遍历处理
for i in li:
a = i.find("a") # 找到a标签
# 获取href属性
# split("/")将字符串以"/"作为分隔符 从右往左数第一项是id号
music_id = a.get("href").split("/")[-1]
# 获取title属性 和“.m4a”拼接成文件名
music_name = a.get("title") + ".m4a"
# 修改请求参数id
params['id'] = music_id
# 获得音频源地址
r = requests.get(get_link_url, headers=headers, params=params)
link = r.json()['data']['src']
# 获取音频文件并保存
music_file = requests.get(link).content
with open(music_name, "wb") as f:
f.write(music_file)
print("下载完毕!")
运行代码,等待亿会(真的要等亿会),可以看到当前目录下已经出现了音频文件,如图:
到此这篇关于Python爬虫之批量下载喜马拉雅音频的文章就介绍到这了,更多相关Python下载喜马拉雅音频内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
用python爬虫批量下载pdf的实现
今天遇到一个任务,给一个excel文件,里面有500多个pdf文件的下载链接,需要把这些文件全部下载下来.我知道用python爬虫可以批量下载,不过之前没有接触过.今天下午找了下资料,终于成功搞定,免去了手动下载的烦恼. 由于我搭建的python版本是3.5,我学习了上面列举的参考文献2中的代码,这里的版本为2.7,有些语法已经不适用了.我修正了部分语法,如下: # coding = UTF-8 # 爬取李东风PDF文档,网址:http://www.math.pku.edu.cn/teacher
-
python爬虫智能翻页批量下载文件的实例详解
python爬虫遇到爬取文件内容时,需要一页页的翻页爬取,这样很是麻烦,其实可以获取每个列表信息下的文件名和文件链接,让文件名和文件链接处理为列表,保存后下载,实现智能翻页批量下载文件,本文以以京客隆为例,批量下载文件,如财务资料,他的每一份报告都是一份pdf格式的文档.以此页面为目标,下载他每个分类的文件python爬虫实战之智能翻页批量下载文件. 1.引入库 import requests import pandas as pd from lxml import etree import r
-

用python批量下载apk
案例故事: 之前我们做Android手机测试的时候, 市场部希望我们测试部进行Top 1000 app(排名前1000的app)的兼容性测试, 以确保我们的手机是可以安装并正常运行这么多好用的app, 且市场部提供了某应用市场上的top 1000 的apk下载地址. 如何实现快速批量地下载apk文件呢? 准备阶段 以上excel里的的url分明是需要进行二次重定向的,因为其不是一个.apk结尾的链接, 我们需要进行解析后再进行重定向.wget命令是不支持这url重定向解析的,所以不能采用. 所以
-
如何基于Python批量下载音乐
这篇文章主要介绍了如何基于Python批量下载音乐,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 音乐是生活的调剂品,目前很多的音乐只能播放不能下载.生为技术员的我们,怎么甘心呢? 知识点: requests 正则表达式 开发环境: 版 本:anaconda5.2.0(python3.6.5) 编辑器:pycharm 第三方库: requests parsel 网页分析 目标站点:http://music.taihe.com/search?ke
-
python 根据列表批量下载网易云音乐的免费音乐
运行效果 代码 # -*- coding:utf-8 -*- import requests, hashlib, sys, click, re, base64, binascii, json, os from Crypto.Cipher import AES from http import cookiejar """ Website:http://cuijiahua.com Author:Jack Cui Refer:https://github.com/darknesso
-
python实现壁纸批量下载代码实例
项目地址:https://github.com/jrainlau/wallpaper-downloader 前言 好久没有写文章了,因为最近都在适应新的岗位,以及利用闲暇时间学习python.这篇文章是最近的一个python学习阶段性总结,开发了一个爬虫批量下载某壁纸网站的高清壁纸. 注意:本文所属项目仅用于python学习,严禁作为其他用途使用! 初始化项目 项目使用了virtualenv来创建一个虚拟环境,避免污染全局.使用pip3直接下载即可: pip3 install virtualen
-
python实现抖音视频批量下载
本文实例为大家分享了python实现抖音视频批量下载的具体代码,供大家参考,具体内容如下 这里就拿最近很火的抖音视频为例,利用API来实现用户抖音视频的批量下载 主要用到的模块有 1.requests模块: 2.bs4模块: import requests import bs4 import os import json import re import sys import time from contextlib import closing requests.packages.urllib
-
使用python3批量下载rbsp数据的示例代码
1. 原始网站 https://www.rbsp-ect.lanl.gov/data_pub/rbspa/ 2. 算法说明 进入需要下载的数据所在的目录,获取并解析该目录下的信息,解析出cdf文件名后,将cdf文件下载到内存中,随后保存到硬盘中.程序使用python3实现. 3. 程序代码 #!/bin/python3 # get the rbsp data # writen by Liangjin Song on 20191219 import sys import requests from
-
python+POP3实现批量下载邮件附件
最近新开学,接到了给老板的本科课程当助教的工作,百十来号人一学期下来得有四五次作业发进邮箱里,需要我来统计打分,想想挨个点进去下载附件的过程就头大,于是萌生了写个脚本来统计作业的想法. 其实python里收发邮件都有很方便的包,合理使用就好,可以解决绝大多数的邮件收发任务.但是这个脚本写下来还是花了不少时间,其中最大的一部分时间是花在了python的编码问题上,python2和python3的编码预设有些许的不一样,在python3中又取消了unicode这个方法,这就导致很多在python2中
-
python爬虫 批量下载zabbix文档代码实例
这篇文章主要介绍了python爬虫 批量下载zabbix文档代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 # -*- coding: UTF-8 -*- import requests,re,time url = 'https://www.zabbix.com/documentation/3.4/zh/manual' base_url = 'https://www.zabbix.com/documentation/3.4/' seco
-
Python实现Youku视频批量下载功能
前段时间由于收集视频数据的需要,自己捣鼓了一个YouKu视频批量下载的程序.东西虽然简单,但还挺实用的,拿出来分享给大家. 版本:Python2.7+BeautifulSoup3.2.1 import urllib,urllib2,sys,os from BeautifulSoup import BeautifulSoup import itertools,re url_i =1 pic_num = 1 #自己定义的引号格式转换函数 def _en_to_cn(str): obj = itert
-
Python爬虫实战案例之爬取喜马拉雅音频数据详解
前言 喜马拉雅是专业的音频分享平台,汇集了有声小说,有声读物,有声书,FM电台,儿童睡前故事,相声小品,鬼故事等数亿条音频,我最喜欢听民间故事和德云社相声集,你呢? 今天带大家爬取喜马拉雅音频数据,一起期待吧!! 这个案例的视频地址在这里 https://v.douyu.com/show/a2JEMJj3e3mMNxml 项目目标 爬取喜马拉雅音频数据 受害者地址 https://www.ximalaya.com/ 本文知识点: 1.系统分析网页性质 2.多层数据解析 3.海量音频数据保存 环境
-
python FTP批量下载/删除/上传实例
最近几天,学习python3的对FTP操作,做下总结!!!! 1.FTP链接 这样写的好处就是如果报错,很快就能找到错在哪里,方便找到问题. 2.FTP文件批量下载 有点要注意的: 如果for循环中不加while..try..except..,当然也可以下载,但经常会出现500网络连接错误类似这种错误!! 3.FTP文件批量删除 4.FTP文件上传 5.FTP关闭连接 目前就先分享到这里,新手上路多多关照!!!! 以上这篇python FTP批量下载/删除/上传实例就是小编分享给大家的全部内容了