python实现dbscan算法
DBSCAN 算法是一种基于密度的空间聚类算法。该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其它空间对象)的数目不小于某一给定阀值。DBSCAN 算法的显著优点是聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类。但是由于它直接对整个数据库进行操作且进行聚类时使用了一个全局性的表征密度的参数,因此也具有两个比较明显的弱点:
1. 当数据量增大时,要求较大的内存支持 I/0 消耗也很大;
2. 当空间聚类的密度不均匀、聚类间距离相差很大时,聚类质量较差。
DBSCAN算法的聚类过程
DBSCAN算法基于一个事实:一个聚类可以由其中的任何核心对象唯一确定。等价可以表述为: 任一满足核心对象条件的数据对象p,数据库D中所有从p密度可达的数据对象所组成的集合构成了一个完整的聚类C,且p属于C。
先上结果
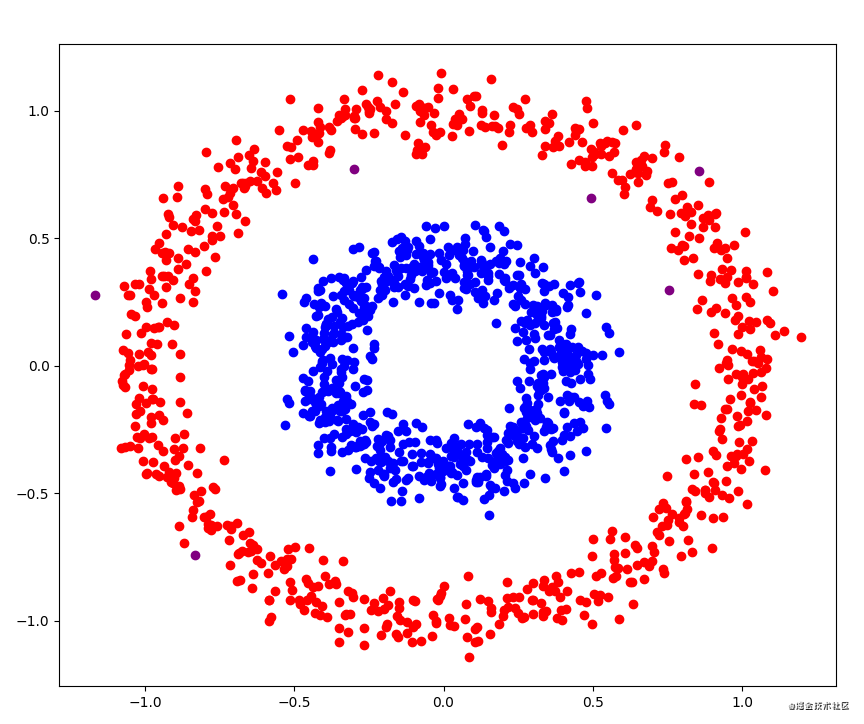
大致流程
先根据给定的半径 r 确定中心点,也就是这类点在半径r内包含的点数量 n 大于我们的要求(n>=minPionts)
然后遍历所有的中心点,将互相可通达的中心点与其包括的点分为一组
全部分完组之后,没有被纳入任何一组的点就是离群点啦!
导入相关依赖
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets
求点跟点之间距离(欧氏距离)
def cuircl(pointA,pointB):
distance = np.sqrt(np.sum(np.power(pointA - pointB,2)))
return distance
求临时簇,即确定所有的中心点,非中心点
def firstCluster(dataSets,r,include):
cluster = []
m = np.shape(dataSets)[0]
ungrouped = np.array([i for i in range (m)])
for i in range (m):
tempCluster = []
#第一位存储中心点簇
tempCluster.append(i)
for j in range (m):
if (cuircl(dataSets[i,:],dataSets[j,:]) < r and i != j ):
tempCluster.append(j)
tempCluster = np.mat(np.array(tempCluster))
if (np.size(tempCluster)) >= include:
cluster.append(np.array(tempCluster).flatten())
#返回的是List
center=[]
n = np.shape(cluster)[0]
for k in range (n):
center.append(cluster[k][0])
#其他的就是非中心点啦
ungrouped = np.delete(ungrouped,center)
#ungrouped为非中心点
return cluster,center,ungrouped
将所有中心点遍历并进行聚集
def clusterGrouped(tempcluster,centers):
m = np.shape(tempcluster)[0]
group = []
#对应点是否遍历过
position = np.ones(m)
unvisited = []
#未遍历点
unvisited.extend(centers)
#所有点均遍历完毕
for i in range (len(position)):
coreNeihbor = []
result = []
#删除第一个
#刨去自己的邻居结点,这一段就类似于深度遍历
if position[i]:
#将邻结点填入
coreNeihbor.extend(list(tempcluster[i][:]))
position[i] = 0
temp = coreNeihbor
#按照深度遍历遍历完所有可达点
#遍历完所有的邻居结点
while len(coreNeihbor) > 0 :
#选择当前点
present = coreNeihbor[0]
for j in range(len(position)):
#如果没有访问过
if position[j] == 1:
same = []
#求所有的可达点
if (present in tempcluster[j]):
cluster = tempcluster[j].tolist()
diff = []
for x in cluster:
if x not in temp:
#确保没有重复点
diff.append(x)
temp.extend(diff)
position[j] = 0
# 删掉当前点
del coreNeihbor[0]
result.extend(temp)
group.append(list(set(result)))
i +=1
return group
核心算法完毕!
生成同心圆类型的随机数据进行测试
#生成非凸数据 factor表示内外圈距离比
X,Y1 = datasets.make_circles(n_samples = 1500, factor = .4, noise = .07)
#参数选择,0.1为圆半径,6为判定中心点所要求的点个数,生成分类结果
tempcluster,center,ungrouped = firstCluster(X,0.1,6)
group = clusterGrouped(tempcluster,center)
#以下是分类后对数据进行进一步处理
num = len(group)
voice = list(ungrouped)
Y = []
for i in range (num):
Y.append(X[group[i]])
flat = []
for i in range(num):
flat.extend(group[i])
diff = [x for x in voice if x not in flat]
Y.append(X[diff])
Y = np.mat(np.array(Y))
绘图~
color = ['red','blue','green','black','pink','orange']
for i in range(num):
plt.scatter(Y[0,i][:,0],Y[0,i][:,1],c=color[i])
plt.scatter(Y[0,-1][:,0],Y[0,-1][:,1],c = 'purple')
plt.show()
结果
紫色点就是离散点

到此这篇关于python实现dbscan算法的文章就介绍到这了,更多相关python dbscan算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python基于聚类算法实现密度聚类(DBSCAN)计算【测试可用】
本文实例讲述了Python基于聚类算法实现密度聚类(DBSCAN)计算.分享给大家供大家参考,具体如下: 算法思想 基于密度的聚类算法从样本密度的角度考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇得到最终结果. 几个必要概念: ε-邻域:对于样本集中的xj, 它的ε-邻域为样本集中与它距离小于ε的样本所构成的集合. 核心对象:若xj的ε-邻域中至少包含MinPts个样本,则xj为一个核心对象. 密度直达:若xj位于xi的ε-邻域中,且xi为核心对象,则xj由xi密度直达. 密度可达:若样
-
python实现鸢尾花三种聚类算法(K-means,AGNES,DBScan)
一.分散性聚类(kmeans) 算法流程: 1.选择聚类的个数k. 2.任意产生k个聚类,然后确定聚类中心,或者直接生成k个中心. 3.对每个点确定其聚类中心点. 4.再计算其聚类新中心. 5.重复以上步骤直到满足收敛要求.(通常就是确定的中心点不再改变. 优点: 1.是解决聚类问题的一种经典算法,简单.快速 2.对处理大数据集,该算法保持可伸缩性和高效率 3.当结果簇是密集的,它的效果较好 缺点 1.在簇的平均值可被定义的情况下才能使用,可能不适用于某些应用 2.必须事先给出k(要生成的簇的数
-
python实现dbscan算法
DBSCAN 算法是一种基于密度的空间聚类算法.该算法利用基于密度的聚类的概念,即要求聚类空间中的一定区域内所包含对象(点或其它空间对象)的数目不小于某一给定阀值.DBSCAN 算法的显著优点是聚类速度快且能够有效处理噪声点和发现任意形状的空间聚类.但是由于它直接对整个数据库进行操作且进行聚类时使用了一个全局性的表征密度的参数,因此也具有两个比较明显的弱点: 1. 当数据量增大时,要求较大的内存支持 I/0 消耗也很大; 2. 当空间聚类的密度不均匀.聚类间距离相差很大时,聚类质量较差. DBS
-
Python实现DBSCAN聚类算法并样例测试
什么是聚类算法?聚类是一种机器学习技术,它涉及到数据点的分组.给定一组数据点,我们可以使用聚类算法将每个数据点划分为一个特定的组.理论上,同一组中的数据点应该具有相似的属性和/或特征,而不同组中的数据点应该具有高度不同的属性和/或特征.聚类是一种无监督学习的方法,是许多领域中常用的统计数据分析技术. 常用的算法包括K-MEANS.高斯混合模型(Gaussian Mixed Model,GMM).自组织映射神经网络(Self-Organizing Map,SOM) 重点给大家介绍Python实现D
-
python快速查找算法应用实例
本文实例讲述了Python快速查找算法的应用,分享给大家供大家参考. 具体实现方法如下: import random def partition(list_object,start,end): random_choice = start #random.choice(range(start,end+1)) #把这里的start改成random()效率会更高些 x = list_object[random_choice] i = start j = end while True: while li
-
Python数据结构与算法之图结构(Graph)实例分析
本文实例讲述了Python数据结构与算法之图结构(Graph).分享给大家供大家参考,具体如下: 图结构(Graph)--算法学中最强大的框架之一.树结构只是图的一种特殊情况. 如果我们可将自己的工作诠释成一个图问题的话,那么该问题至少已经接近解决方案了.而我们我们的问题实例可以用树结构(tree)来诠释,那么我们基本上已经拥有了一个真正有效的解决方案了. 邻接表及加权邻接字典 对于图结构的实现来说,最直观的方式之一就是使用邻接列表.基本上就是针对每个节点设置一个邻接列表.下面我们来实现一个最简
-
Python基于分水岭算法解决走迷宫游戏示例
本文实例讲述了Python基于分水岭算法解决走迷宫游戏.分享给大家供大家参考,具体如下: #Solving maze with morphological transformation """ usage:Solving maze with morphological transformation needed module:cv2/numpy/sys ref: 1.http://www.mazegenerator.net/ 2.http://blog.leanote.com
-
python二分查找算法的递归实现方法
本文实例讲述了python二分查找算法的递归实现方法.分享给大家供大家参考,具体如下: 这里先提供一段二分查找的代码: def binarySearch(alist, item): first = 0 last = len(alist)-1 found = False while first<=last and not found: midpoint = (first + last)//2 if alist[midpoint] == item: found = True else: if ite
-
python通过BF算法实现关键词匹配的方法
本文实例讲述了python通过BF算法实现关键词匹配的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: #!/usr/bin/python # -*- coding: UTF-8 # filename BF import time """ t="this is a big apple,this is a big apple,this is a big apple,this is a big apple." p="apple&q
-
python选择排序算法实例总结
本文实例总结了python选择排序算法.分享给大家供大家参考.具体如下: 代码1: def ssort(V): #V is the list to be sorted j = 0 #j is the "current" ordered position, starting with the first one in the list while j != len(V): #this is the replacing that ends when it reaches the end o
-
python 换位密码算法的实例详解
python 换位密码算法的实例详解 一前言: 换位密码基本原理:先把明文按照固定长度进行分组,然后对每一组的字符进行换位操作,从而实现加密.例如,字符串"Error should never pass silently",使用秘钥1432进行加密时,首先将字符串分成若干长度为4的分组,然后对每个分组的字符进行换位,第1个和第3个字符位置不变,把第2个字符和第4个字符交换位置,得到"Eorrrs shluoden v repssa liseltny" 二 代码: