python结合多线程爬取英雄联盟皮肤(原理分析)
1.什么是多线程?
多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率。线程是在同一时间需要完成多项任务的时候实现的。
为什么要使用多线程
线程在程序中是独立的、并发的执行流。与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存、文件句柄和其他进程应有的状态。
因为线程的划分尺度小于进程,使得多线程程序的并发性高。进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率。
线程比进程具有更高的性能,这是由于同一个进程中的线程都有共性多个线程共享同一个进程的虚拟空间。线程共享的环境包括进程代码段、进程的公有数据等,利用这些共享的数据,线程之间很容易实现通信。
操作系统在创建进程时,必须为该进程分配独立的内存空间,并分配大量的相关资源,但创建线程则简单得多。因此,使用多线程来实现并发比使用多进程的性能要高得多。
总结起来,使用多线程编程具有如下几个优点:
进程之间不能共享内存,但线程之间共享内存非常容易。
操作系统在创建进程时,需要为该进程重新分配系统资源,但创建线程的代价则小得多。因此,使用多线程来实现多任务并发执行比使用多进程的效率高。
Python 语言内置了多线程功能支持,而不是单纯地作为底层操作系统的调度方式,从而简化了 Python 的多线程编程。
2.原理
实现多线程是采用一种并发执行机制 。
并发执行机制原理:简单地说就是把一个处理器划分为若干个短的时间片,每个时间片依次轮流地执行处理各个应用程序,由于一个时间片很短,相对于一个应用程序来说,就好像是处理器在为自己单独服务一样,从而达到多个应用程序在同时进行的效果 。
多线程就是把操作系统中的这种并发执行机制原理运用在一个程序中,把一个程序划分为若干个子任务,多个子任务并发执行,每一个任务就是一个线程。这就是多线程程序 。

3.优点
1、使用线程可以把占据时间长的程序中的任务放到后台去处理 。
2、用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度。
3、程序的运行速度可能加快 。
4、在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下可以释放一些珍贵的资源如内存占用等 。
5、多线程技术在IOS软件开发中也有举足轻重的作用。
4.缺点
1、如果有大量的线程,会影响性能,因为操作系统需要在它们之间切换。
2、更多的线程需要更多的内存空间。
3、线程可能会给程序带来更多“bug”,因此要小心使用。
4、线程的中止需要考虑其对程序运行的影响。
5、通常块模型数据是在多个线程间共享的,需要防止线程死锁情况的发生。
好的废话不多说,我们直接来实战吧
1.进入英雄联盟官网点击游戏资料进入此画面

2.确定爬取的网页是同步加载还是异步加载
1.鼠标右键打开网页源代码
2.ctrl+f打开搜索框
3.在搜索框了输入英雄的名字

没有搜索结果则为异步加载 3.寻找英雄url地址
回到英雄页面鼠标右击打开检查。

在获取的包中找到hero_list.js这个包 英语翻译过来英雄列表.js文件

点击网页上英雄安妮拿回地址再点击其他英雄拿回地址做比较。
安妮:

狂战士:
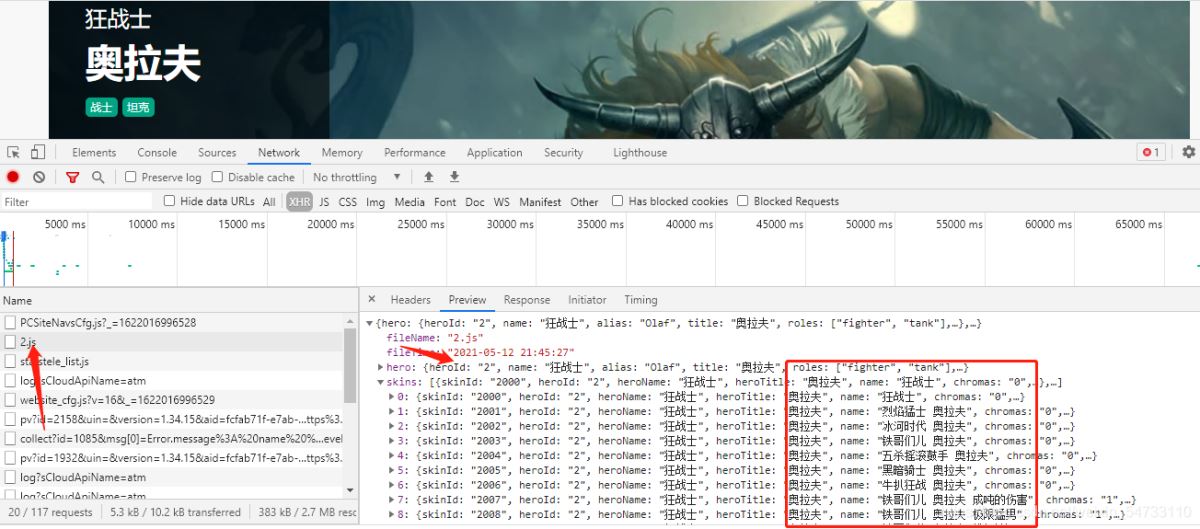
点击headers拿回resquests url
安妮:https://game.gtimg.cn/images/lol/act/img/js/hero/1.js
狂战士:https://game.gtimg.cn/images/lol/act/img/js/hero/2.js
可以发现变化在最后面 是英雄的id 这样我们有思路了
1.第一次发送请求,拿回所有英雄的id和名字
2.第二次请求,得到英雄皮肤名,英雄手机皮肤url, 英雄电脑皮肤url
3.请求得到 手机图片二进制数据, 电脑图片二进制数据
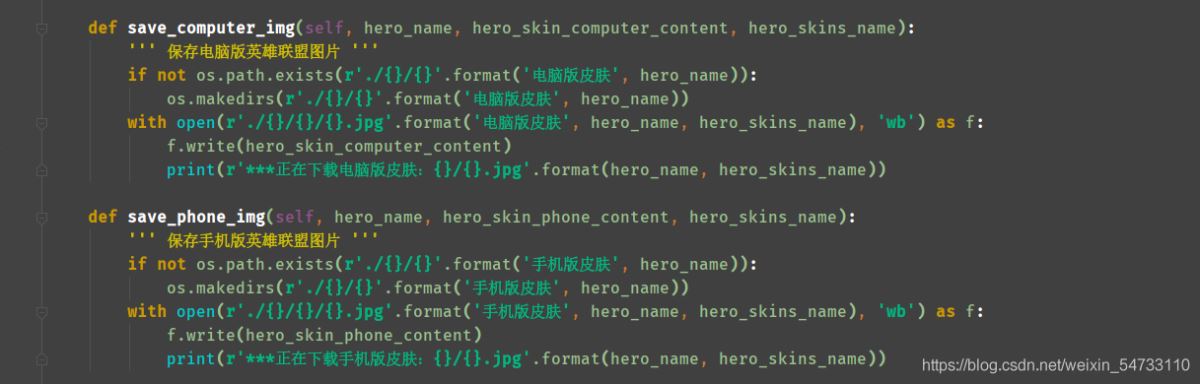
4.保存电脑版英雄联盟图片,保存手机版英雄联盟图片
5.多进程实现保存数据
是时候写一点代码了。。。嘿嘿
起始地址弄成全局变量

观察网页

1第一次请求,我们要拿回这两个数据。可以看出preview里面是个json数据,导入jsonpath库进行提取数据。

2第二次请求,得到英雄皮肤名,英雄手机皮肤url, 英雄电脑皮肤url
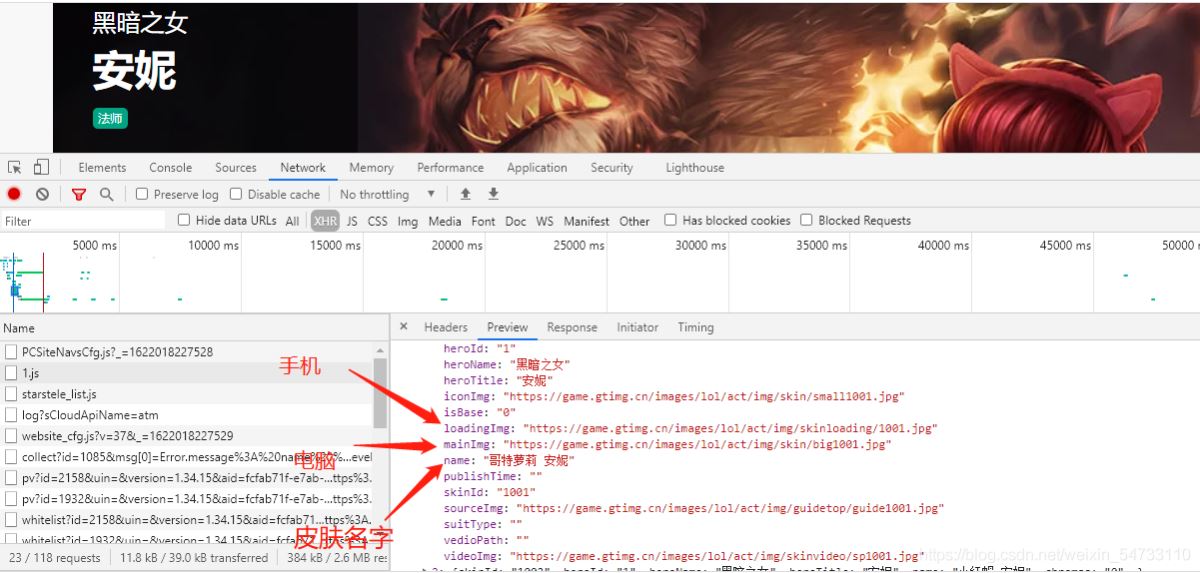

3 请求得到 手机图片二进制数据, 电脑图片二进制数据 利用try-except语句防止报错停止代码运行。

4.保存电脑版英雄联盟图片,保存手机版英雄联盟图片,利用try-except语句防止报错停止代码运行。
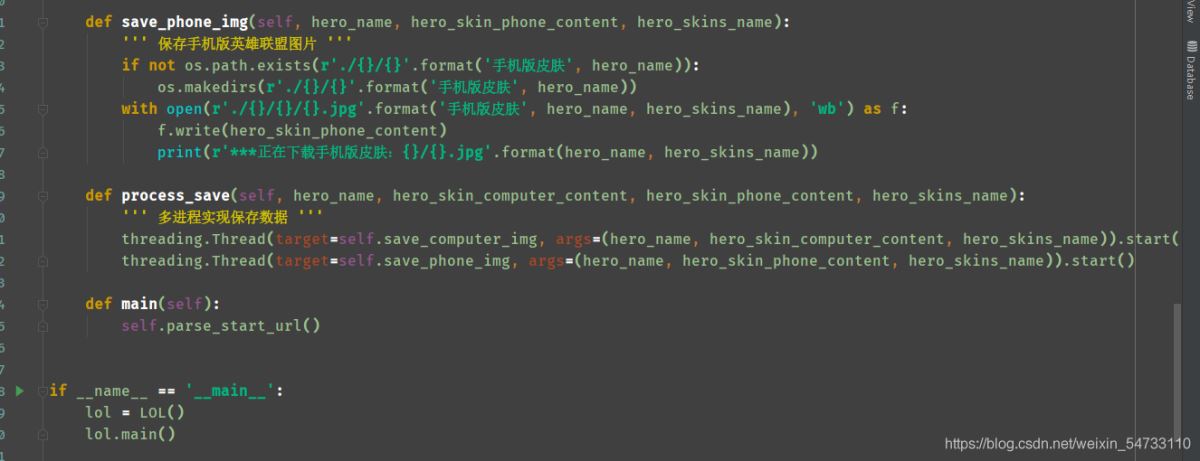
5.多进程实现保存数据 导包:import threading
threading.Thread(target=self.函数名, args=(用到的参数)) 写法

代码全解:



最后在发一个守护线程防止报错的模板,大家好好参考。
from threading import Thread
from queue import Queue
class Love(object):
def init(self):
# 队列容量,队列创建 ,[], {}
self.q = Queue()
def parse_data(self):
"""功能:往队列添加数据"""
data = "第{}天----我爱你----"
for i in range(1, 100):
# 将数据放入队列,put的时候计数+1,get不会-1,get需要和task_done一起使用才会-1
self.q.put(data.format(i))
# 等待task_done()返回的信号量和put进去的数量一直才会往下执行
# join所完成的工作就是线程同步,即主线程任务结束之后,进入阻塞状态,一
# 直等待其他的子线程执行结束之后,主线程在终止,否则主线程会杀死子线程
# 主线程结束后子线程无论是否执行完毕都将结束,因此join的作用就显现出来了
self.q.join()
def func2(self):
"""功能:从队列中获取数据"""
while True:
# 循环从队列中获取, 取出数据,队列为空的时候会等待
result = self.q.get()
print(result)
# 使队列计数-1
self.q.task_done()
def run(self):
# 进程创建
"""进程:功能:往队列中添加数据"""
m1 = Thread(target=self.parse_data)
"""进程:功能:从队列里面获取数据"""
m2 = Thread(target=self.func2)
m1.start()
# 将m2设置成守护进程 因为m2一直是死循环,设置成守护进程之后当主程序代码运行完毕,m2就会结束,不会成为僵尸进程
# 即只在需要的时候才启动,完成任务后就自动结束
m2.daemon = True
m2.start()
# 队列中维持了一个计数,计数不为0时候让主线程阻塞等待,队列计数为0的时候才会继续往后执行
m1.join()
if name == ‘main':
love = Love()
love.run()
祝大家学习python顺利
以上就是python爬取英雄联盟皮肤结合多线程的方法的详细内容,更多关于python爬取英雄联盟皮肤的资料请关注我们其它相关文章!
相关推荐
-
python多线程实现同时执行两个while循环的操作
如果想同时执行两个while True循环,可以使用多线程threading来实现. 完整代码 #coding=gbk from time import sleep, ctime import threading def muisc(func): while True: print 'Start playing: %s! %s' %(func,ctime()) sleep(2) def move(func): while True: print 'Start playing: %s! %s' %
-

python 爬取英雄联盟皮肤图片
一开始都是先去<英雄联盟>官网找到英雄及皮肤图片的网址: URL = r'https://lol.qq.com/data/info-heros.shtml' 从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号(如下图). 但是只有英雄的名字(英文)以及对应的编号并不能找到
-
浅谈Python3多线程之间的执行顺序问题
一个多线程的题:定义三个线程ID分别为ABC,每个线程打印10遍自己的线程ID,按ABCABC--的顺序进行打印输出. 我的解法: from threading import Thread, Lock # 由_acquire解锁执行后释放_release锁 def _print(_id: str, _acquire: Lock, _release: Lock) -> None: for i in range(10): _acquire.acquire() print(f"id:{_id}&
-
解决python多线程报错:AttributeError: Can't pickle local object问题
报错信息: Traceback (most recent call last): File "D:/flaskProject/test.py", line 35, in test pool.apply(self.out, args=(i,)) File "Python37-32\lib\multiprocessing\pool.py", line 261, in apply return self.apply_async(func, args, kwds).get(
-
python 爬取英雄联盟皮肤并下载的示例
爬取结果: 爬取代码 import os import json import requests from tqdm import tqdm def lol_spider(): # 存放英雄信息 heros = [] # 存放英雄皮肤 hero_skins = [] # 获取所有英雄信息 url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js' hero_text = requests.get(url).t
-
python结合多线程爬取英雄联盟皮肤(原理分析)
1.什么是多线程? 多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率.线程是在同一时间需要完成多项任务的时候实现的. 为什么要使用多线程 线程在程序中是独立的.并发的执行流.与分隔的进程相比,进程中线程之间的隔离程度要小,它们共享内存.文件句柄和其他进程应有的状态. 因为线程的划分尺度小于进程,使得多线程程序的并发性高.进程在执行过程中拥有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率. 线程比进程具有更高的性能,这是由于同一个进程
-
教你用Python爬取英雄联盟皮肤原画
一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: http://lol.qq.com/data/info-heros.shtml 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中.这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.js的选项,点击可以看到一个字典--里面就包含了所有英雄的名字(英文)以及对应的编号. 3.但是只有英雄的名字(英文)以及对应的编号并不能找到图片地址,于是
-
用Python爬取英雄联盟的皮肤详细示例
目录 一.推理原理 二.推理代码 第一步:获取js字典 第二步:从 js字典中提取到key值生成url列表 第三步:从 js字典中提取到value值生成name列表 第四步:下载并保存数据 第五步:执行主程序 一.推理原理 1.先去<英雄联盟>官网找到英雄及皮肤图片的网址: lol.qq.com 2.从上面网址可以看到所有英雄都在,按下F12查看源代码,发现英雄及皮肤图片并没有直接给出,而是隐藏在JS文件中. 这时候需要点开Network,找到js窗口,刷新网页,就看到一个champion.j
-
Python3爬取英雄联盟英雄皮肤大图实例代码
爬虫思路 初步尝试 我先查看了network,并没有发现有可用的API:然后又用bs4去分析英雄列表页,但是请求到html里面,并没有英雄列表,在英雄列表的节点上,只有"正在加载中"这样的字样:同样的方法,分析英雄详情也是这种情况,所以我猜测,这些数据应该是Javascript负责加载的. 继续尝试 然后我就查看了 英雄列表的源代码 ,查看外部引入的js文件,以及行内的js脚本,大概在368行,发现了有处理英雄列表的js注释,然后继续往下读这些代码,发现了第一个彩蛋,也就是他引入了一个
-
Python爬取英雄联盟MSI直播间弹幕并生成词云图
一.环境准备 安装相关第三方库 pip install jieba pip install wordcloud 二.数据准备 爬取对象:2021年5月23号,RNG夺冠直播间的弹幕信息 爬取对象路径: 方式1.根据开发者工具(F12),获取请求url.请求头.cookie等信息: 方式2:根据直播地址url,前+字符i 我们这里演示的是,采用方式2. 三.代码如下 import requests, re import jieba, wordcloud """ # 以下是练习代
-
Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文实例讲述了Python3爬虫爬取英雄联盟高清桌面壁纸功能.分享给大家供大家参考,具体如下: 使用Scrapy爬虫抓取英雄联盟高清桌面壁纸 源码地址:https://github.com/snowyme/loldesk 开始项目前需要安装python3和Scrapy,不会的自行百度,这里就不具体介绍了 首先,创建项目 scrapy startproject loldesk 生成项目的目录结构 首先需要定义抓取元素,在item.py中,我们这个项目用到了图片名和链接 import scrapy
-
Python进阶多线程爬取网页项目实战
目录 一.网页分析 二.代码实现 一.网页分析 这次我们选择爬取的网站是水木社区的Python页面 网页:https://www.mysmth.net/nForum/#!board/Python?p=1 根据惯例,我们第一步还是分析一下页面结构和翻页时的请求. 通过前三页的链接分析后得知,每一页链接中最后的参数是页数,我们修改它即可得到其他页面的数据. 再来分析一下,我们需要获取帖子的链接就在id 为 body 的 section下,然后一层一层找到里面的 table,我们就能遍历这些链接的标题
-
高考要来啦!用Python爬取历年高考数据并分析
开发工具 **Python版本:**3.6.4 相关模块: pyecharts模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. pyecharts模块的安装可参考: Python简单分析微信好友 "一本正经的分析" 首先让我们来看看从恢复高考(1977年)开始高考报名.最终录取的总人数走势吧: T_T看来学生党确实是越来越多了. 不过这样似乎并不能很直观地看出每年的录取比例?Ok,让我们直观地看看吧: 看来上大学越来越