Python爬虫基础之爬虫的分类知识总结
一、通用爬虫
通用网络爬虫是搜索引擎抓取系统(Baidu、Google、Sogou等)的一个重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。为搜索引擎提供搜索支持。
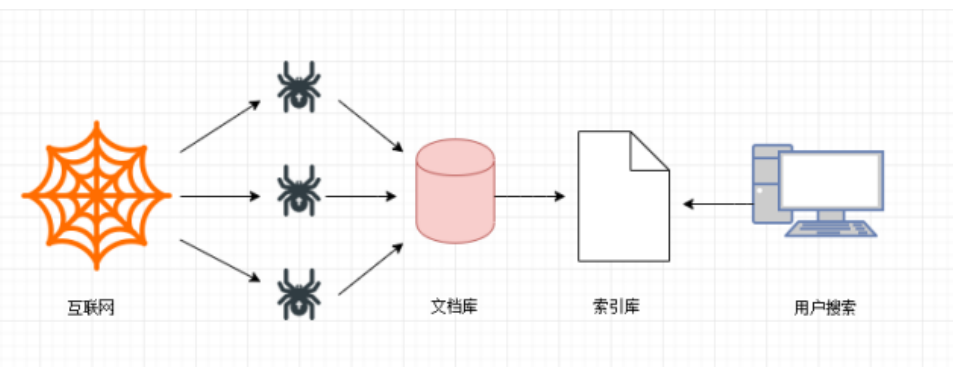
第一步
搜索引擎去成千上万个网站抓取数据。
第二步
搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库(也就是文档库)。其中的页面数据与用户浏览器得到的HTML是完全—样的。
第三步
搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理:中文分词,消除噪音,索引处理。。。
搜索引擎在对信息进行组织和处理后,为用户提供关键字检索服务,将用户检索相关的信息展示给用户。展示的时候会进行排名。
二、搜索引擎的局限性
- 搜索引擎抓取的是整个网页,不是具体详细的信息。
- 搜索引擎无法提供针对具体某个客户需求的搜索结果。
聚焦爬虫
针对通用爬虫的这些情况,聚焦爬虫技术得以广泛使用。聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页数据。
三、Robots协议
robots是网站跟爬虫间的协议,用简单直接的txt格式文本方式告诉对应的爬虫被允许的权限,也就是说robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。——百度百科
Robots协议也叫爬虫协议、机器人协议等,全称是“网络爬虫排除标准”(Robots ExclusionProtocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,例如:
淘宝: https://www.taobao.com/robots.txt
百度: https://www.baidu.com/robots.txt
四、请求与相应
网络通信由两部分组成:客户端请求消息与服务器响应消息

浏览器发送HTTP请求的过程:

1.当我们在浏览器输入URL https://www.baidu.com的时候,浏览器发送一个Request请求去
获取 https://www.baidu.com 的html文件,服务器把Response文件对象发送回给浏览器。
2.浏览器分析Response中的HTML,发现其中引用了很多其他文件,比如Images文件,CSS文件,JS文件。浏览器会自动再次发送Request去获取图片,CSS文件,或者JS文件。
3.当所有的文件都下载成功后,网页会根据HTML语法结构,完整的显示出来了。
实际上我们通过学习爬虫技术爬取数据,也是向服务器请求数据,获取服务器响应数据的过程。
到此这篇关于Python爬虫基础之爬虫的分类知识总结的文章就介绍到这了,更多相关Python爬虫的分类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python爬虫数据的分类及json数据使用小结
数据的结构化分类 一般来讲对我们而言,需要抓取的是某个网站或者某个应用的内容,提取有用的价值.内容一般分为三部分,结构化的数据.半结构化的数据和非机构化数据. 1.结构化数据: 可以用统一的结构加以表示的数据.可以使用关系型数据库表示和存储,表现为二维形式的数据,一般特点是:数据以行为单位,一行数据表示一个实体的信息,每一行的数据的属性是相同的. 2.半结构化数据: 结构化数据的一种形式,并不符合关系型数据库或其他数据表的形式关联起来的数据模型结构,但包含相关标记,用
-

用Python爬虫破解滑动验证码的案例解析
做爬虫总会遇到各种各样的反爬限制,反爬的第一道防线往往在登录就出现了,为了限制爬虫自动登录,各家使出了浑身解数,所谓道高一尺魔高一丈. 今天分享个如何简单处理滑动图片的验证码的案例. 类似这种拖动滑块移动到图片中缺口位置与之重合的登录验证在很多网站或者APP都比较常见,因为它对真实用户体验友好,容易识别.同时也能拦截掉大部分初级爬虫. 作为一只python爬虫,如何正确地自动完成这个验证过程呢? 先来分析下,核心问题其实是要怎么样找到目标缺口的位置,一旦知道了位置,我们就可以借用selenium
-
Python爬虫之线程池的使用
一.前言 学到现在,我们可以说已经学习了爬虫的基础知识,如果没有那些奇奇怪怪的反爬虫机制,基本上只要有时间分析,一般的数据都是可以爬取的,那么到了这个时候我们需要考虑的就是爬取的效率了,关于提高爬虫效率,也就是实现异步爬虫,我们可以考虑以下两种方式:一是线程池的使用(也就是实现单进程下的多线程),一是协程的使用(如果没有记错,我所使用的协程模块是从python3.4以后引入的,我写博客时使用的python版本是3.9). 今天我们先来讲讲线程池. 二.同步代码演示 我们先用普通的同步的形式写一段
-
python基础之爬虫入门
前言 python基础爬虫主要针对一些反爬机制较为简单的网站,是对爬虫整个过程的了解与爬虫策略的熟练过程. 爬虫分为四个步骤:请求,解析数据,提取数据,存储数据.本文也会从这四个角度介绍基础爬虫的案例. 一.简单静态网页的爬取 我们要爬取的是一个壁纸网站的所有壁纸 http://www.netbian.com/dongman/ 1.1 选取爬虫策略--缩略图 首先打开开发者模式,观察网页结构,找到每一张图对应的的图片标签,可以发现我们只要获取到标黄的img标签并向它发送请求就可以得到壁纸的预览图
-
Python爬虫之爬取最新更新的小说网站
一.引言 这个五一假期自驾回老家乡下,家里没装宽带,用手机热点方式访问网络.这次回去感觉4G信号没有以前好,通过百度查找小说最新更新并打开小说网站很慢,有时要打开好多个网页才能找到可以正常打开的最新更新.为了躲懒,老猿决定利用Python爬虫知识,写个简单应用自己查找小说最新更新并访问最快的网站,花了点时间研究了一下相关报文,经过近一天时间研究和编写,终于搞定,下面就来介绍一下整个过程. 二.关于相关访问请求及应答报文 2.1.百度搜索请求 我们通过百度网页的搜索框进行搜索时,提交的url请求是
-
Python爬虫实现的根据分类爬取豆瓣电影信息功能示例
本文实例讲述了Python爬虫实现的根据分类爬取豆瓣电影信息功能.分享给大家供大家参考,具体如下: 代码的入口: if __name__ == '__main__': main() #! /usr/bin/python3 # -*- coding:utf-8 -*- # author:Sirius.Zhao import json from urllib.parse import quote from urllib.request import urlopen from urllib.reque
-
python爬虫scrapy图书分类实例讲解
我们去图书馆的时候,会直接去自己喜欢的分类栏目找寻书籍.如果其中的分类不是很细致的话,想找某一本书还是有一些困难的.同样的如果我们获取了一些图书的数据,原始的文件里各种数据混杂在一起,非常不利于我们的查找和使用.所以今天小编教大家如何用python爬虫中scrapy给图书分类,大家一起学习下: spider抓取程序: 在贴上代码之前,先对抓取的页面和链接做一个分析: 网址:http://category.dangdang.com/pg4-cp01.25.17.00.00.00.html 这个是当
-
python爬虫请求库httpx和parsel解析库的使用测评
Python网络爬虫领域两个最新的比较火的工具莫过于httpx和parsel了.httpx号称下一代的新一代的网络请求库,不仅支持requests库的所有操作,还能发送异步请求,为编写异步爬虫提供了便利.parsel最初集成在著名Python爬虫框架Scrapy中,后独立出来成立一个单独的模块,支持XPath选择器, CSS选择器和正则表达式等多种解析提取方式, 据说相比于BeautifulSoup,parsel的解析效率更高. 今天我们就以爬取链家网上的二手房在售房产信息为例,来测评下http
-
Python异步爬虫实现原理与知识总结
一.背景 默认情况下,用get请求时,会出现阻塞,需要很多时间来等待,对于有很多请求url时,速度就很慢.因为需要一个url请求的完成,才能让下一个url继续访问.一种很自然的想法就是用异步机制来提高爬虫速度.通过构建线程池或者进程池完成异步爬虫,即使用多线程或者多进程来处理多个请求(在别的进程或者线程阻塞时). import time #串形 def getPage(url): print("开始爬取网站",url) time.sleep(2)#阻塞 print("爬取完成
-
Python爬虫基础之爬虫的分类知识总结
一.通用爬虫 通用网络爬虫是搜索引擎抓取系统(Baidu.Google.Sogou等)的一个重要组成部分.主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份.为搜索引擎提供搜索支持. 第一步 搜索引擎去成千上万个网站抓取数据. 第二步 搜索引擎通过爬虫爬取到的网页,将数据存入原始页面数据库(也就是文档库).其中的页面数据与用户浏览器得到的HTML是完全-样的. 第三步 搜索引擎将爬虫抓取回来的页面,进行各种步骤的预处理:中文分词,消除噪音,索引处理... 搜索引擎在对信息进行组织
-
python构建基础的爬虫教学
爬虫具有域名切换.信息收集以及信息存储功能. 这里讲述如何构建基础的爬虫架构. 1. urllib库:包含从网络请求数据.处理cookie.改变请求头和用户处理元数据的函数.是python标准库.urlopen用于打开读取一个从网络获取的远程对象.能轻松读取HTML文件.图像文件及其他文件流. 2. beautifulsoup库:通过定位HTML标签格式化和组织复杂的网络信息,用python对象展现XML结构信息.不是标准库,可用pip安装.常用的对象是BeautifulSoup对象. 1.基础
-
python爬虫基础知识点整理
首先爬虫是什么? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 根据我的经验,要学习Python爬虫,我们要学习的共有以下几点: Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy Python爬虫更高级的功能 1.Python基础学习 首先,我们要用Python写爬虫,肯定要了解Python的基础吧,万丈高楼平地起,
-
python爬虫基础教程:requests库(二)代码实例
get请求 简单使用 import requests ''' 想要学习Python?Python学习交流群:973783996满足你的需求,资料都已经上传群文件,可以自行下载! ''' response = requests.get("https://www.baidu.com/") #text返回的是unicode的字符串,可能会出现乱码情况 # print(response.text) #content返回的是字节,需要解码 print(response.content.decod
-
python爬虫基础之urllib的使用
一.urllib 和 urllib2的关系 在python2中,主要使用urllib和urllib2,而python3对urllib和urllib2进行了重构,拆分成了urllib.request, urllib.parse, urllib.error,urllib.robotparser等几个子模块,这样的架构从逻辑和结构上说更加合理.urllib库无需安装,python3自带.python 3.x中将urllib库和urilib2库合并成了urllib库. urllib2.urlopen()
-
python爬虫beautifulsoup库使用操作教程全解(python爬虫基础入门)
[python爬虫基础入门]系列是对python爬虫的一个入门练习实践,旨在用最浅显易懂的语言,总结最明了,最适合自己的方法,本人一直坚信,总结才会使人提高 1. BeautifulSoup库简介 BeautifulSoup库在python中被美其名为"靓汤",它和和 lxml 一样也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据.BeautifulSoup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,若在没用安装此库的情况下
-
Python爬虫基础之requestes模块
一.爬虫的流程 开始学习爬虫,我们必须了解爬虫的流程框架.在我看来爬虫的流程大概就是三步,即不论我们爬取的是什么数据,总是可以把爬虫的流程归纳总结为这三步: 1.指定 url,可以简单的理解为指定要爬取的网址 2.发送请求.requests 模块的请求一般为 get 和 post 3.将爬取的数据存储 二.requests模块的导入 因为 requests 模块属于外部库,所以需要我们自己导入库 导入的步骤: 1.右键Windows图标 2.点击"运行" 3.输入"cmd&q
-
python爬虫基础之简易网页搜集器
简易网页搜集器 前面我们已经学会了简单爬取浏览器页面的爬虫.但事实上我们的需求当然不是爬取搜狗首页或是B站首页这么简单,再不济,我们都希望可以爬取某个特定的有信息的页面. 不知道在学会了爬取之后,你有没有跟我一样试着去爬取一些搜索页面,比如说百度.像这样的页面 注意我红笔划的部分,这是我打开的网页.现在我希望能爬取这一页的数据,按我们前面学的代码,应该是这样写的: import requests if __name__ == "__main__": # 指定URL url = &quo
-
Python爬虫基础讲解之请求
一.请求目标(URL) URL又叫作统一资源定位符,是用于完整地描述Internet上网页和其他资源的地址的一种方法.类似于windows的文件路径. 二.网址的组成: 1.http://:这个是协议,也就是HTTP超文本传输协议,也就是网页在网上传输的协议. 2.mail:这个是服务器名,代表着是一个邮箱服务器,所以是mail. 3.163.com:这个是域名,是用来定位网站的独一无二的名字. 4.mail.163.com:这个是网站名,由服务器名+域名组成. 5./:这个是根目录,也就是说,