基于KL散度、JS散度以及交叉熵的对比
在看论文《Detecting Regions of Maximal Divergence for Spatio-Temporal Anomaly Detection》时,文中提到了这三种方法来比较时间序列中不同区域概率分布的差异。
KL散度、JS散度和交叉熵
三者都是用来衡量两个概率分布之间的差异性的指标。不同之处在于它们的数学表达。
对于概率分布P(x)和Q(x)
1)KL散度(Kullback–Leibler divergence)
又称KL距离,相对熵。
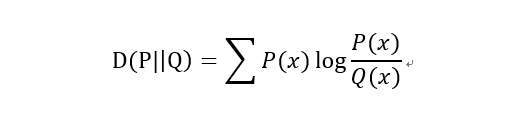
当P(x)和Q(x)的相似度越高,KL散度越小。
KL散度主要有两个性质:
(1)不对称性
尽管KL散度从直观上是个度量或距离函数,但它并不是一个真正的度量或者距离,因为它不具有对称性,即D(P||Q)!=D(Q||P)。
(2)非负性
相对熵的值是非负值,即D(P||Q)>0。
2)JS散度(Jensen-Shannon divergence)
JS散度也称JS距离,是KL散度的一种变形。
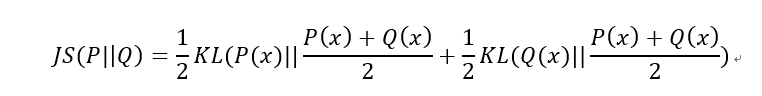
但是不同于KL主要又两方面:
(1)值域范围
JS散度的值域范围是[0,1],相同则是0,相反为1。相较于KL,对相似度的判别更确切了。
(2)对称性
即 JS(P||Q)=JS(Q||P),从数学表达式中就可以看出。
3)交叉熵(Cross Entropy)
在神经网络中,交叉熵可以作为损失函数,因为它可以衡量P和Q的相似性。
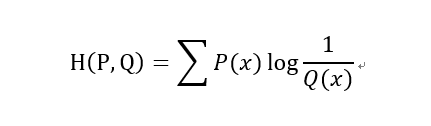
交叉熵和相对熵的关系:
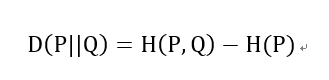
以上都是基于离散分布的概率,如果是连续的数据,则需要对数据进行Probability Density Estimate来确定数据的概率分布,就不是求和而是通过求积分的形式进行计算了。
补充:信息熵、交叉熵与KL散度
信息量
在信息论与编码中,信息量,也叫自信息(self-information),是指一个事件所能够带来信息的多少。一般地,这个事件发生的概率越小,其带来的信息量越大。
从编码的角度来看,这个事件发生的概率越大,其编码长度越小,这个事件发生的概率越小,其编码长度就越大。但是编码长度小也是代价的,比如字母'a'用数字‘0'来表示时,为了避免歧义,就不能有其他任何以‘0'开头的编码了。
因此,信息量定义如下:
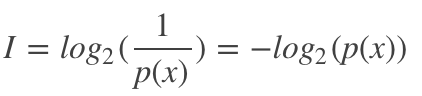
信息熵
信息熵是指一个概率分布p的平均信息量,代表着随机变量或系统的不确定性,熵越大,随机变量或系统的不确定性就越大。从编码的角度来看,信息熵是表示一个概率分布p需要的平均编码长度,其可表示为:
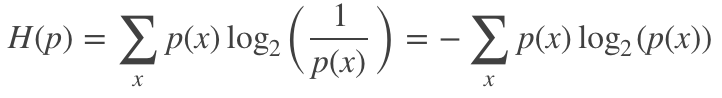
交叉熵
交叉熵是指在给定真实分布q情况下,采用一个猜测的分布p对其进行编码的平均编码长度(或用猜测的分布来编码真实分布得到的信息量)。
交叉熵可以用来衡量真实数据分布于当前分布的相似性,当前分布与真实分布相等时(q=p),交叉熵达到最小值。
其可定义为:
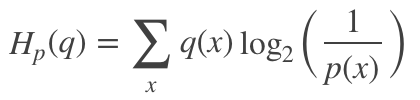
因此,在很多机器学习算法中都使用交叉熵作为损失函数,交叉熵越小,当前分布与真实分布越接近。此外,相比于均方误差,交叉熵具有以下两个优点:
在LR中,如果用均方误差损失函数,它是一个非凸函数,而使用交叉熵损失函数,它是一个凸函数;
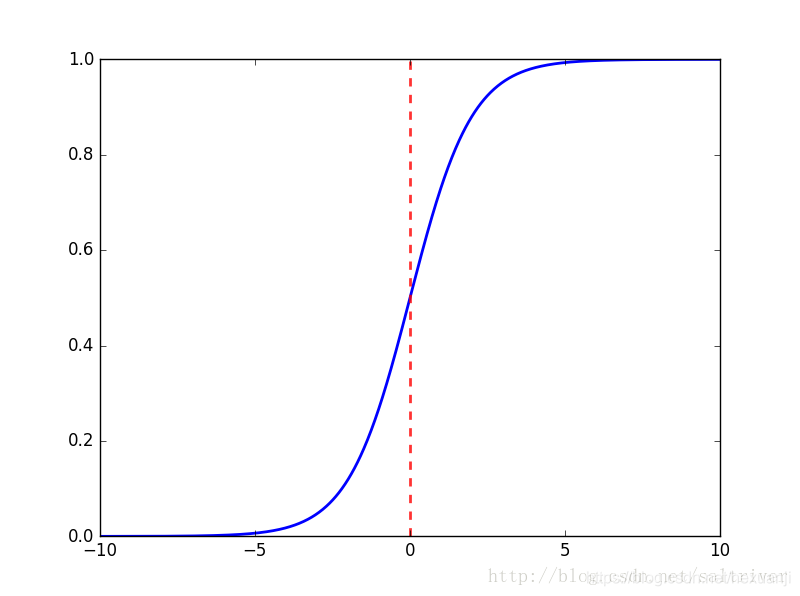
在LR中使用sigmoid激活函数,如果使用均方误差损失函数,在对其求残差时,其表达式与激活函数的导数有关,而sigmoid(如下图所示)的导数在输入值超出[-5,5]范围后将非常小,这会带来梯度消失问题,而使用交叉熵损失函数则能避免这个问题。
KL散度
KL散度又称相对熵,是衡量两个分布之间的差异性。从编码的角度来看,KL散度可表示为采用猜测分布p得到的平均编码长度与采用真实分布q得到的平均编码长度多出的bit数,其数学表达式可定义为:
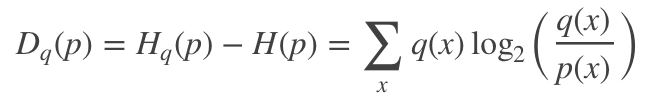
一般地,两个分布越接近,其KL散度越小,最小为0.它具有两个特性:
非负性,即KL散度最小值为0,其详细证明可见[1] ;
非对称性,即Dq(p)不等于Dp(q) ; KL散度与交叉熵之间的关系
在这里,再次盗用[1]的图来形象地表达这两者之间的关系:
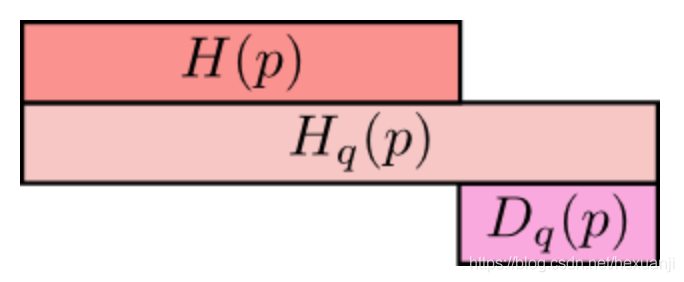
最上方cH(p)为信息熵,表示分布p的平均编码长度/信息量;
中间的Hq(p)表示用分布q表编码分布p所含的信息量或编码长度,简称为交叉熵,其中Hq(p)>=H(p)
;最小方的Dq(p)表示的是q对p的KL距离,衡量了分布q和分布p之间的差异性,其中Dq(p)>=0;
从上图可知,Hq(p) = H(p) + Dq(p)。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

pandas读取excel,txt,csv,pkl文件等命令的操作
pandas读取txt文件 读取txt文件需要确定txt文件是否符合基本的格式,也就是是否存在\t,,,等特殊的分隔符 一般txt文件长成这个样子 txt文件举例 下面的文件为空格间隔 1 2019-03-22 00:06:24.4463094 中文测试 2 2019-03-22 00:06:32.4565680 需要编辑encoding 3 2019-03-22 00:06:32.6835965 ashshsh 4 2017-03-22 00:06:32.8041945 eggg 读取命令采用
-
Python 机器学习工具包SKlearn的安装与使用
1.SKlearn 是什么 Sklearn(全称 SciKit-Learn),是基于 Python 语言的机器学习工具包. Sklearn 主要用Python编写,建立在 Numpy.Scipy.Pandas 和 Matplotlib 的基础上,也用 Cython编写了一些核心算法来提高性能. Sklearn 包括六大功能模块: 分类(Classification):识别样本属于哪个类别,常用算法有 SVM(支持向量机).nearest neighbors(最近邻).random forest(
-
pytorch 实现计算 kl散度 F.kl_div()
先附上官方文档说明:https://pytorch.org/docs/stable/nn.functional.html torch.nn.functional.kl_div(input, target, size_average=None, reduce=None, reduction='mean') Parameters input – Tensor of arbitrary shape target – Tensor of the same shape as input size_aver
-
python数据分析之用sklearn预测糖尿病
一.数据集描述 本数据集内含十个属性列 Pergnancies: 怀孕次数 Glucose:血糖浓度 BloodPressure:舒张压(毫米汞柱) SkinThickness:肱三头肌皮肤褶皱厚度(毫米) Insulin:两个小时血清胰岛素(μU/毫升) BMI:身体质量指数,体重除以身高的平方 Diabets Pedigree Function: 疾病血统指数 是否和遗传相关,Height:身高(厘米) Age:年龄 Outcome:0表示不患病,1表示患病. 任务:建立机器学习模型以准确预
-
python爬取之json、pickle与shelve库的深入讲解
前言 在使用Python进行网络编程或者爬取一些自己感兴趣的东西时,总避免不了进行一些数据传输.存取等问题,Python的文件对象以及其他扩展库,已经解决了很多关于文本和二进制数据存取的问题,比如网页内容.图片&音视频等多媒体内容,但这些数据基本是最终的数据形态存储,有没有办法可以存储Python本身的一些对象数据,后续在使用的时候,再直接加载为Python对象即可,本文便讲解下常用的Python对象数据存取.传输解决方案,即pickle.shelve.json. 内容比较基础,也比较简单,但也
-
基于KL散度、JS散度以及交叉熵的对比
在看论文<Detecting Regions of Maximal Divergence for Spatio-Temporal Anomaly Detection>时,文中提到了这三种方法来比较时间序列中不同区域概率分布的差异. KL散度.JS散度和交叉熵 三者都是用来衡量两个概率分布之间的差异性的指标.不同之处在于它们的数学表达. 对于概率分布P(x)和Q(x) 1)KL散度(Kullback–Leibler divergence) 又称KL距离,相对熵. 当P(x)和Q(x)的相似度越高
-
基于BootStrap multiselect.js实现的下拉框联动效果
背景:当option特别多时,一般的下拉框选择起来就有点力不从心了,所以使用multiselect是个很好的选择,可以通过输入文字来选择选项很方便,但是有一个需要下拉框联动,网上找了半天才找到解决方法,在此分享一下 1.先引入 <script src="~/Assets/js/bootstrap-multiselect.min.js"></script> <link href="~/Assets/css/bootstrap-multiselect
-
基于jQuery.Hz2Py.js插件实现的汉字转拼音特效
可以实现基于jQuery实现汉字转换成拼音代码.这是一款基于jQuery.Hz2Py.js插件实现的汉字转拼音特效.插件自行下载.使用方法如下(注意修改jq的引入路径). <html><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>基于jQuery实现汉字转换成拼音代码</title> <
-
基于HTML+CSS+JS实现增加删除修改tab导航特效代码
先给大家展示下效果图,如果大家感觉还不错,请参考实现代码哦! HTML: <div class="container iden_top"> <ul> <li> <p class='iden_add_name'>应用标识1</p> <span class="iden_top_button"></span> <div class="iden_top_dete"&
-
基于webpack.config.js 参数详解
webpack.config.js文件通常放在项目的根目录中,它本身也是一个标准的Commonjs规范的模块. var webpack = require('webpack'); module.exports = { entry: [ 'webpack/hot/only-dev-server', './js/app.js' ], output: { path: './build', filename: 'bundle.js' }, module: { loaders: [ { test: /\.
-
如何基于java或js获取URL返回状态码
这篇文章主要介绍了如何基于java或js获取URL返回状态码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 描述:使用java或者js访问某个网站,返回状态码 1.java实现 // 用getResponseCode可以获取URL返回状态码 String surl = ""; try { surl="你的url"; URL url = new URL(surl); URLConnection rulConnecti
-
pytorch中交叉熵损失(nn.CrossEntropyLoss())的计算过程详解
公式 首先需要了解CrossEntropyLoss的计算过程,交叉熵的函数是这样的: 其中,其中yi表示真实的分类结果.这里只给出公式,关于CrossEntropyLoss的其他详细细节请参照其他博文. 测试代码(一维) import torch import torch.nn as nn import math criterion = nn.CrossEntropyLoss() output = torch.randn(1, 5, requires_grad=True) label = tor
-
PyTorch的SoftMax交叉熵损失和梯度用法
在PyTorch中可以方便的验证SoftMax交叉熵损失和对输入梯度的计算 关于softmax_cross_entropy求导的过程,可以参考HERE 示例: # -*- coding: utf-8 -*- import torch import torch.autograd as autograd from torch.autograd import Variable import torch.nn.functional as F import torch.nn as nn import nu
-
基于jquery.page.js实现分页效果
基于jquery.page.js的一款简单的分页效果,供大家参考,具体内容如下 <!DOCTYPE html> <html> <head> <meta charset="utf-8" /> <title>简单的jQuery分页插件</title> <style> *{ margin:0; padding:0; list-style:none;} a{ text-decoration:none;} a:h
-
解决pytorch 交叉熵损失输出为负数的问题
网络训练中,loss曲线非常奇怪 交叉熵怎么会有负数. 经过排查,交叉熵不是有个负对数吗,当网络输出的概率是0-1时,正数.可当网络输出大于1的数,就有可能变成负数. 所以加上一行就行了 out1 = F.softmax(out1, dim=1) 补充知识:在pytorch框架下,训练model过程中,loss=nan问题时该怎么解决? 当我在UCF-101数据集训练alexnet时,epoch设为100,跑到三十多个epoch时,出现了loss=nan问题,当时是一脸懵逼,在查阅资料后,我通过