MySql批量插入时如何不重复插入数据
目录
- 前言
- 一、insert ignore into
- 二、on duplicate key update
- 三、replace into
- 总结
前言
Mysql插入不重复的数据,当大数据量的数据需要插入值时,要判断插入是否重复,然后再插入,那么如何提高效率?解决的办法有很多种,不同的场景解决方案也不一样,数据量很小的情况下,怎么搞都行,但是数据量很大的时候,这就不是一个简单的问题了。
一、insert ignore into
会忽略数据库中已经存在 的数据,如果数据库没有数据,就插入新的数据,如果有数据的话就跳过当前插入的这条数据。这样就可以保留数据库中已经存在数据,达到在间隙中插入数据的目的。
控制器方法:
/**
* 插入员工数据
*/
@PostMapping("save")
@ResponseBody
public CommonResult<Employee> save(@RequestBody Employee employee){
return employeeService.saveEmp(employee);
}
INSERT INTO 插入数据
<!--插入员工数据-->
<insert id="saveEmp" parameterType="com.dt.springbootdemo.entity.Employee">
INSERT INTO t_employee(id, name, age, salary, department_id)
VALUES (#{id},#{name},#{age},#{salary},#{departmentId})
</insert>
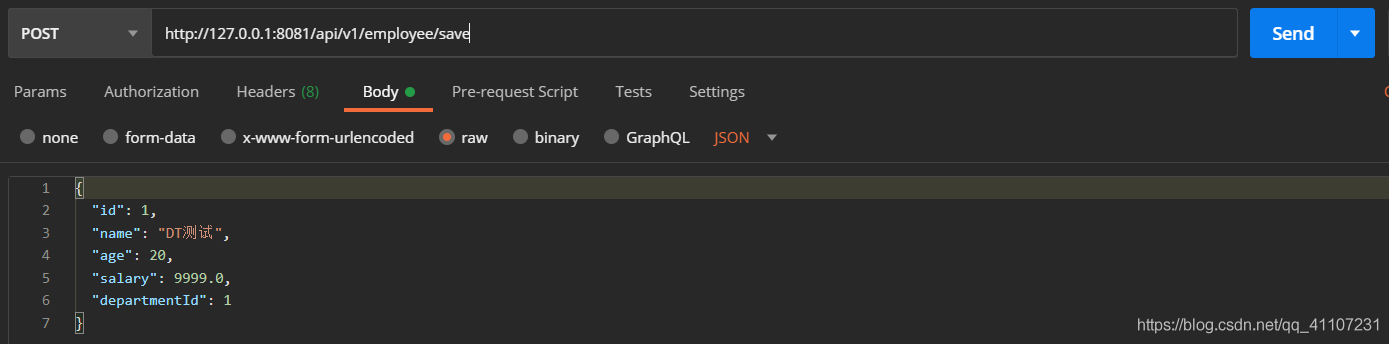
我们新增一条主键ID为1的员工记录。
当我再发送一次请求的时候,会报SQL语句执行错误,因为主键唯一,并且ID=1的记录已经存在了。

加上ignore,再次添加一条ID=1的员工记录
INSERT IGNORE INTO

并没有报错,但是也没有添加成功,忽略了重复数据的添加。
二、on duplicate key update
当主键或者唯一键重复时,则执行update语句。
ON DUPLICATE KEY UPDATE id = id
我们任然插入ID=1的员工记录,并且修改一下其他字段(age=25):
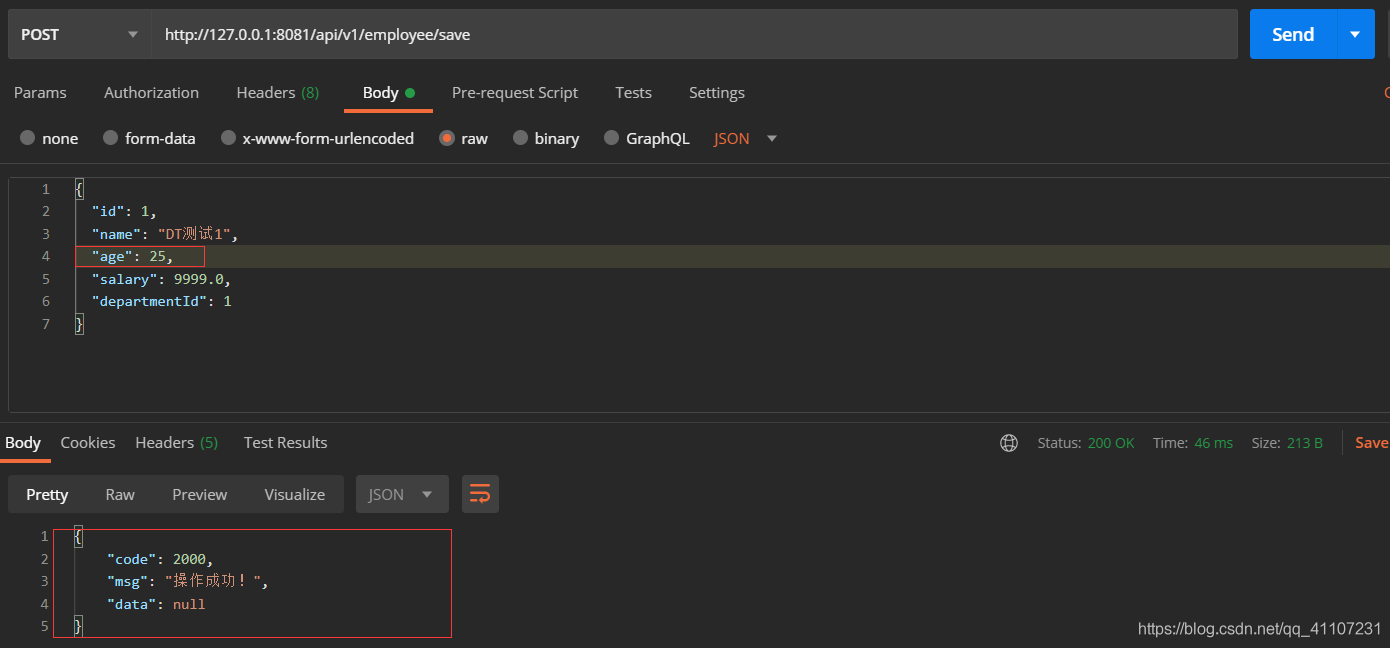
查看数据库记录:

可以看到并没有改变,数据也只有一条,并且返回了成功的提示。
这种方法有个前提条件,就是,需要插入的约束,需要是主键或者唯一约束(在你的业务中那个要作为唯一的判断就将那个字段设置为唯一约束也就是unique key)。
扩展:这种方式还有其他业务场景的需求->>>定时更新其他字段。
我们在员工表中,再加入一个时间字段:
private Date updateTime;

然后我们根据updateTime字段来插入数据:
<insert id="saveEmp" parameterType="com.dt.springbootdemo.entity.Employee">
INSERT INTO t_employee(id, name, age, salary, department_id,update_time)
VALUES (#{id},#{name},#{age},#{salary},#{departmentId},now())
ON DUPLICATE KEY UPDATE update_time = now()
</insert>
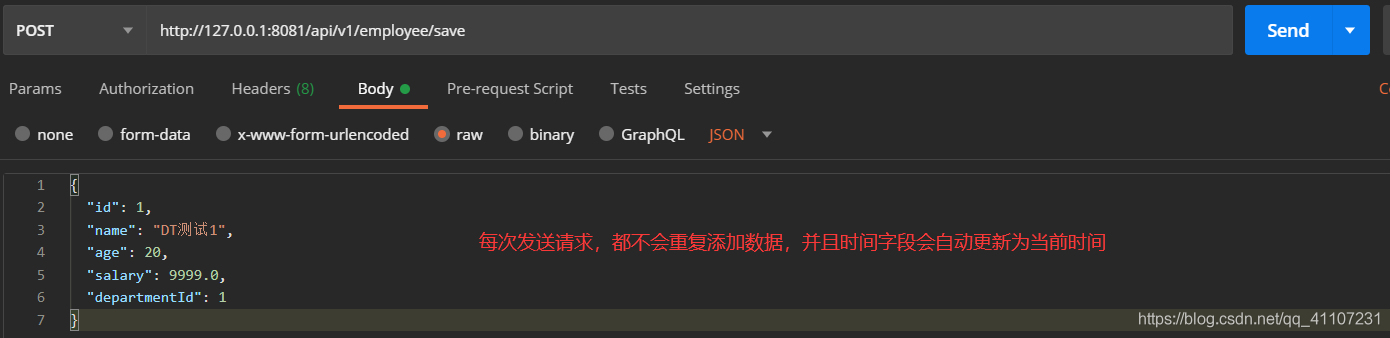


如果插入的时候需要更新其他字段(比如age),该怎么做呢?

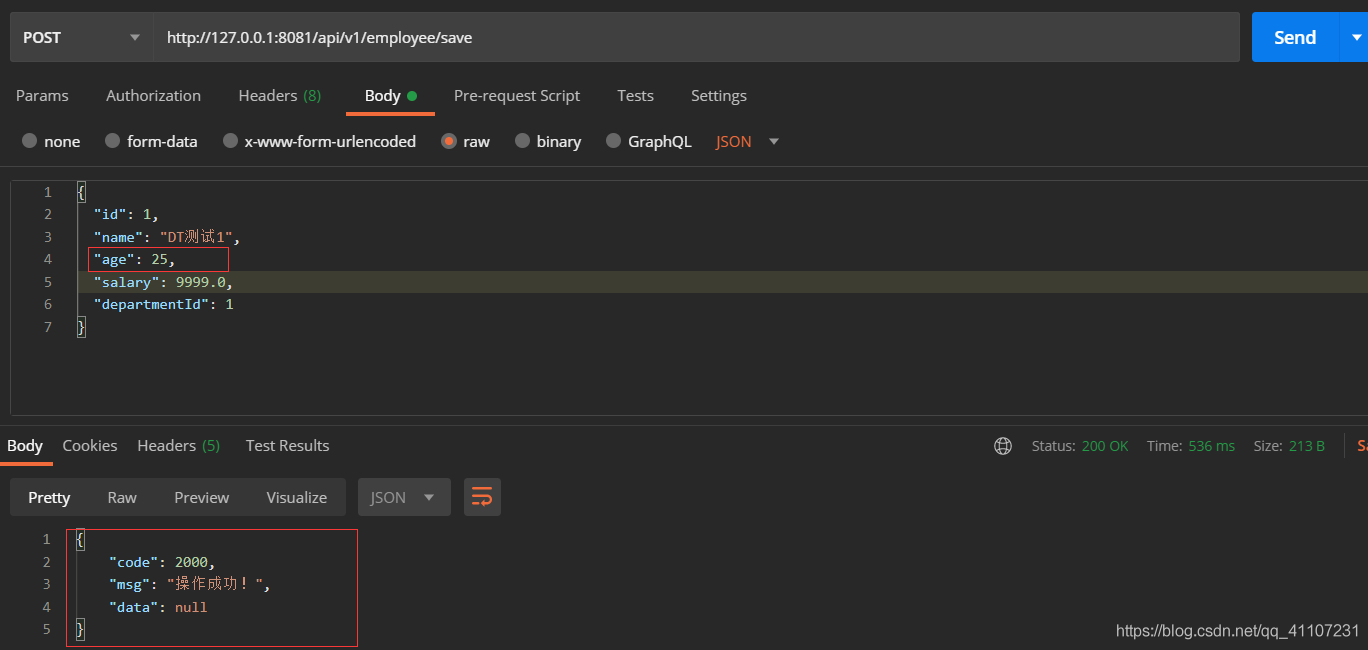

三、replace into
如果存在primary or unique相同的记录,则先删除掉。再插入新记录。
REPLACE INTO
<!--插入员工数据-->
<insert id="saveEmp" parameterType="com.dt.springbootdemo.entity.Employee">
REPLACE INTO t_employee(id, name, age, salary, department_id,update_time)
VALUES (#{id},#{name},#{age},#{salary},#{departmentId},now())
</insert>
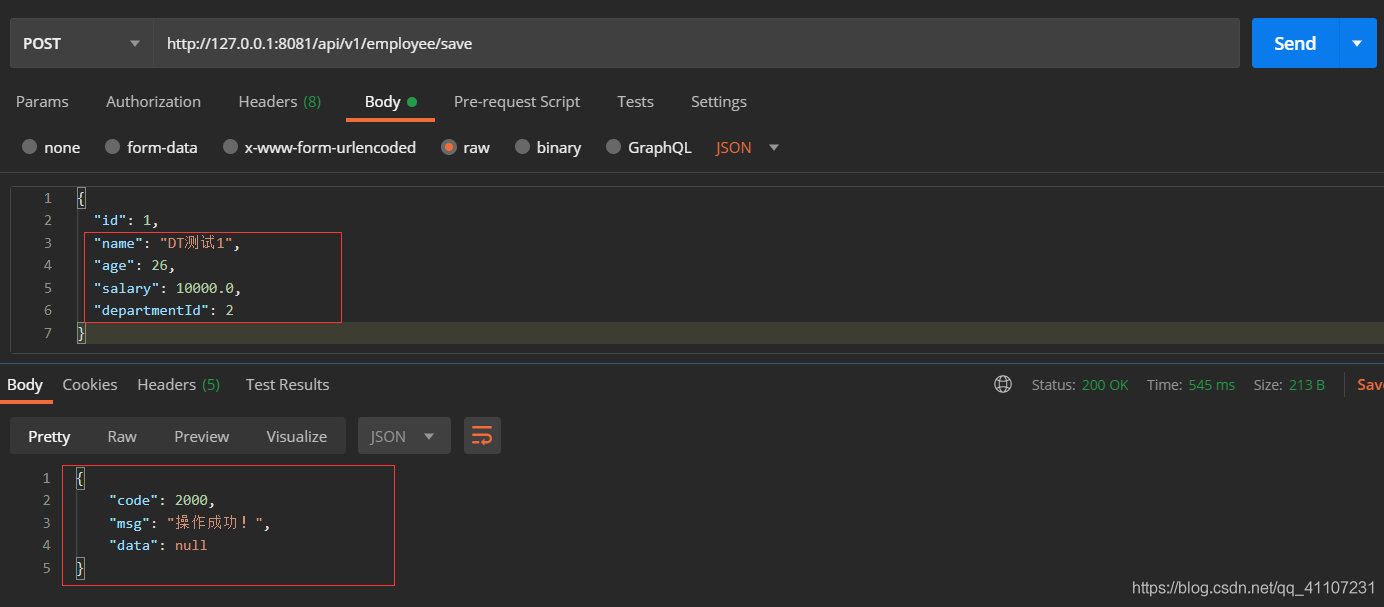

总结:实际开发中,用得最多的就是第二种方式,进行的批量加。
<!--插入员工数据-->
<insert id="saveEmp" parameterType="java.util.List">
INSERT INTO t_employee(id, name, age, salary, department_id,update_time)
VALUES
<foreach collection="list" item="item" index="index" separator=",">
(#{item.id},#{item.name},#{item.age},#{item.salary},#{item.departmentId},now())
</foreach>
ON DUPLICATE KEY UPDATE id = id
</insert>
控制器:
@PostMapping("save")
@ResponseBody
public CommonResult<Employee> save(@RequestBody List<Employee> employeeList){
return employeeService.saveEmp(employeeList);
}
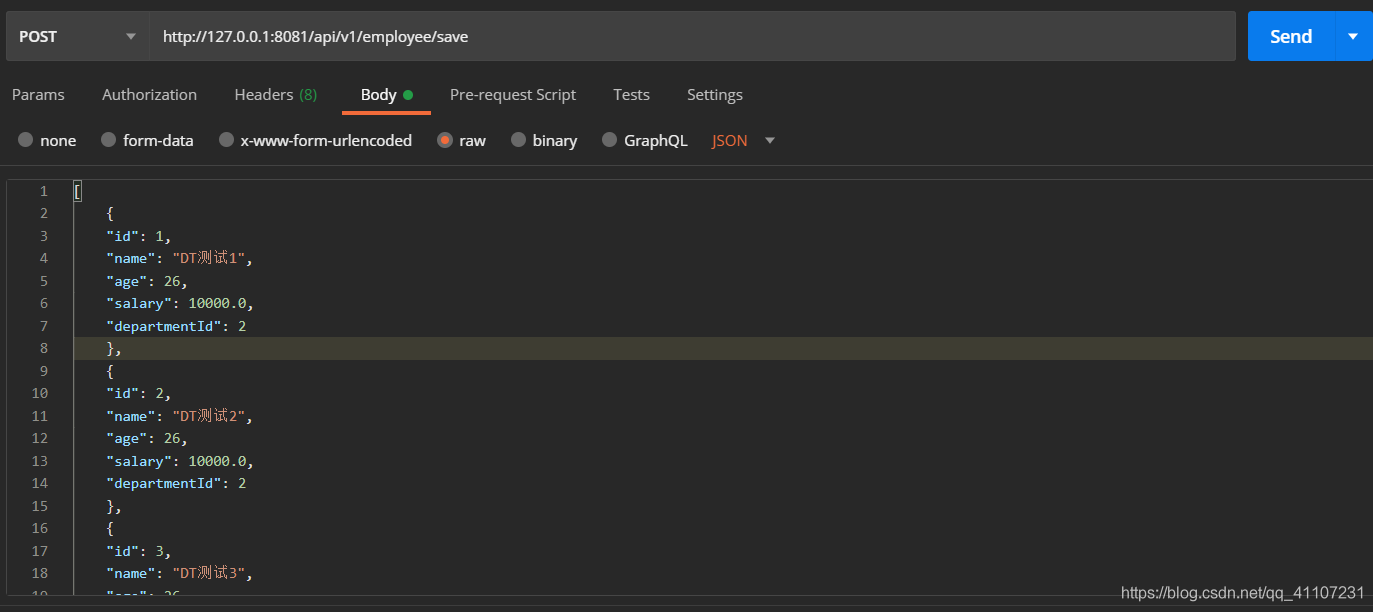
如果存在相同的ID,则不会重复添加。
总结
实际工作中,使用最多的是方法二,根据不同的场景选择不同的方式使用。
到此这篇关于MySql批量插入时如何不重复插入数据的文章就介绍到这了,更多相关MySql不重复插入内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL使用UNIQUE实现数据不重复插入
SQL UNIQUE 约束 UNIQUE 约束唯一标识数据库表中的每条记录. UNIQUE 和 PRIMARY KEY 约束均为列或列集合提供了唯一性的保证. PRIMARY KEY 拥有自动定义的 UNIQUE 约束. 请注意,每个表可以有多个 UNIQUE 约束,但是每个表只能有一个 PRIMARY KEY 约束. 下面的 SQL 在 "Persons" 表创建时在 "Id_P" 列创建 UNIQUE 约束: CREATE TABLE Persons ( Id_
-

MySql批量插入时如何不重复插入数据
目录 前言 一.insert ignore into 二.on duplicate key update 三.replace into 总结 前言 Mysql插入不重复的数据,当大数据量的数据需要插入值时,要判断插入是否重复,然后再插入,那么如何提高效率?解决的办法有很多种,不同的场景解决方案也不一样,数据量很小的情况下,怎么搞都行,但是数据量很大的时候,这就不是一个简单的问题了. 一.insert ignore into 会忽略数据库中已经存在 的数据,如果数据库没有数据,就插入新的数据,如果
-
关于MySQL 大批量插入时如何过滤掉重复数据
目录 一.发现问题 二.删除全部重复数据,一条不留 三.删除表中删除重复数据,仅保留一条 四.开始删除重复数据,仅留一条 前言: 加班原因是上线,解决线上数据库存在重复数据的问题,发现了程序的bug,很好解决,有点问题的是,修正线上的重复数据. 线上库有6个表存在重复数据,其中2个表比较大,一个96万+.一个30万+,因为之前处理过相同的问题,就直接拿来了上次的Python去重脚本,脚本很简单,就是连接数据库,查出来重复数据,循环删除. emmmm,但是这个效率嘛,实在是太低了,1秒一条,重复数
-
mysql ON DUPLICATE KEY UPDATE重复插入时更新方式
目录 mysql当插入重复时更新的方法 第一种方法 第二种方法 第三种方法 Mysql on duplicate key update 解决插入重复数据时更新值的问题以及其存在的问题 一.使用 二.存在问题 mysql当插入重复时更新的方法 第一种方法 示例一:插入多条记录 假设有一个主键为 client_id 的 clients 表,可以使用下面的语句: INSERT INTO clients (client_id,client_name,client_type) SELECT supplie
-
防止mysql重复插入记录的方法
防止mysql重复插入记录的方法有很多种,常用的是ignore,Replace,ON DUPLICATE KEY UPDATE,当然我们也可以在php中加以判断了. 方案一:使用ignore关键字 如果是用主键primary或者唯一索引unique区分了记录的唯一性,避免重复插入记录可以使用: 代码如下: 复制代码 代码如下: INSERT IGNORE INTO `table_name` (`email`, `phone`, `user_id`) VALUES ('test9@163.com'
-
MySql避免重复插入记录的几种方法
方案一:使用ignore关键字 如果是用主键primary或者唯一索引unique区分了记录的唯一性,避免重复插入记录可以使用: 复制代码 代码如下: INSERT IGNORE INTO `table_name` (`email`, `phone`, `user_id`) VALUES ('test9@163.com', '99999', '9999'); 这样当有重复记录就会忽略,执行后返回数字0 还有个应用就是复制表,避免重复记录: 复制代码 代码如下: INSERT IGNORE INT
-
MySQL批量插入和唯一索引问题的解决方法
MySQL批量插入问题 在开发项目时,因为有一些旧系统的基础数据需要提前导入,所以我在导入时做了批量导入操作 ,但是因为MySQL中的一次可接受的SQL语句大小受限制所以我每次批量虽然只有500条,但依然无法插入,这个时候代码报错如下: nested exception is com.mysql.jdbc.PacketTooBigException: Packet for query is too large (5677854 > 1048576). You can change this va
-
防止MySQL重复插入数据的三种方法
新建表格 CREATE TABLE `person` ( `id` int NOT NULL COMMENT '主键', `name` varchar(64) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '姓名', `age` int NULL DEFAULT NULL COMMENT '年龄', `address` varchar(512) CHARACTER SET utf8 COLLATE utf8_bin N
-
Mysql避免重复插入数据的4种方式
最常见的方式就是为字段设置主键或唯一索引,当插入重复数据时,抛出错误,程序终止,但这会给后续处理带来麻烦,因此需要对插入语句做特殊处理,尽量避开或忽略异常,下面我简单介绍一下,感兴趣的朋友可以尝试一下: 这里为了方便演示,我新建了一个user测试表,主要有id,username,sex,address这4个字段,其中主键为id(自增),同时对username字段设置了唯一索引: 01 insert ignore into 即插入数据时,如果数据存在,则忽略此次插入,前提条件是插入的数据字段设置了
-
详解MySQL主键唯一键重复插入解决方法
目录 解决方案: 1. IGNORE 2. REPLACE 3. ON DUPLICATE KEY UPDATE 我们插入数据的时候,有可能碰到重复数据插入的问题,但是这些数据又是不被允许有重复值: CREATE TABLE stuInfo ( id INT NOT NULL COMMENT '序号', name VARCHAR(20) NOT NULL DEFAULT '' COMMENT '姓名', age INT NOT NULL DEFAULT 0 COMMENT '年龄', PRIMA
-
MySql批量插入优化Sql执行效率实例详解
MySql批量插入优化Sql执行效率实例详解 itemcontractprice数量1万左右,每条itemcontractprice 插入5条日志. updateInsertSql.AppendFormat("UPDATE itemcontractprice AS p INNER JOIN foreigncurrency AS f ON p.ForeignCurrencyId = f.ContractPriceId SET p.RemainPrice = f.RemainPrice * {0},