pyCaret效率倍增开源低代码的python机器学习工具
目录
- PyCaret 时间序列模块
- 加载数据
- 初始化设置
- 统计测试
- 探索性数据分析
- 模型训练和选择
- 保存模型
PyCaret 是一个开源、低代码的 Python 机器学习库,可自动执行机器学习工作流。它是一种端到端的机器学习和模型管理工具,可以以指数方式加快实验周期并提高您的工作效率。欢迎收藏学习,喜欢点赞支持,文末提供技术交流群。
与其他开源机器学习库相比,PyCaret 是一个替代的低代码库,可用于仅用几行代码替换数百行代码。 这使得实验速度和效率呈指数级增长。 PyCaret 本质上是围绕多个机器学习库和框架(例如 scikit-learn、XGBoost、LightGBM、CatBoost、spaCy、Optuna、Hyperopt、Ray 等)的 Python 包装器。
PyCaret 的设计和简单性受到数据科学家这一新兴角色的启发,可以执行以前需要更多技术专长的简单和中等复杂的分析任务。
PyCaret 时间序列模块
PyCaret 的新时间序列模块现已提供测试版。 秉承 PyCaret 的简单性,它与现有的 API 保持一致,并带有很多功能。 统计测试、模型训练和选择(30 多种算法)、模型分析、自动超参数调优、实验记录、云部署等, 所有这一切只需要几行代码(就像 pycaret 的其他模块一样)。 如果您想尝试一下,请查看官方的快速入门笔记本。
您可以使用 pip 安装此库。 如果你在同一个环境中安装了 PyCaret,由于依赖冲突,你必须为 pycaret-ts-alpha 创建一个单独的环境。
pip install pycaret-ts-alpha
接下来安排如下
PyCaret 的时间序列模块中的工作流程非常简单。 它从设置功能开始,您可以在其中定义预测范围 fh 和折叠次数。 您还可以将 fold_strategy 定义为扩展或滑动。
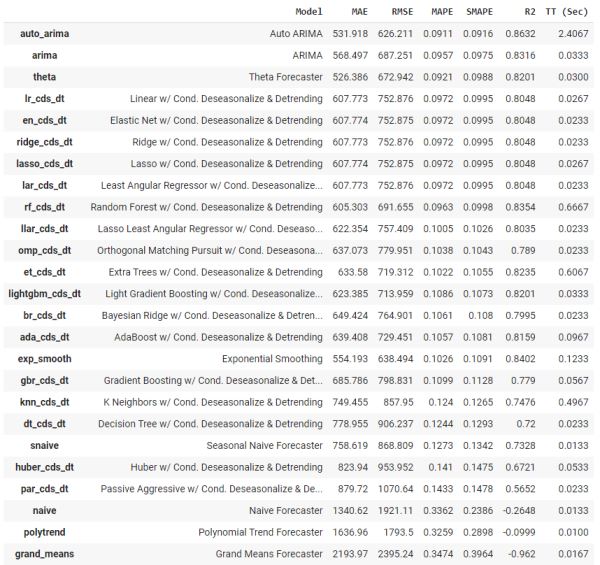
设置后,著名的 compare_models 函数训练和评估从 ARIMA 到 XGboost(TBATS、FBProphet、ETS 等)的 30 多种算法。
plot_model 函数可以在训练之前或之后使用。 在训练前使用时,它使用 plotly 界面收集了大量时间序列 EDA 图。 与模型一起使用时,plot_model 处理模型残差,并可用于访问模型拟合。
最后,predict_model 用于生成预测。
加载数据
import pandas as pd
from pycaret.datasets import get_data
data = get_data('pycaret_downloads')
data['Date'] = pd.to_datetime(data['Date'])
data = data.groupby('Date').sum()
data = data.asfreq('D')
data.head()
# plot the data data.plot()
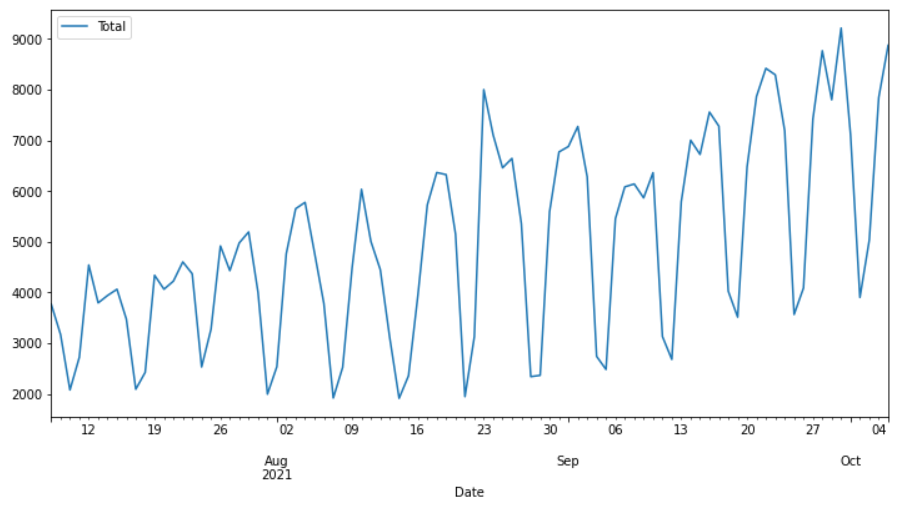
这个时间序列是从 pip 每天下载 PyCaret 库的次数。
初始化设置
# with functional API from pycaret.time_series import * setup(data, fh = 7, fold = 3, session_id = 123) # with new object-oriented API from pycaret.internal.pycaret_experiment import TimeSeriesExperiment exp = TimeSeriesExperiment() exp.setup(data, fh = 7, fold = 3, session_id = 123)

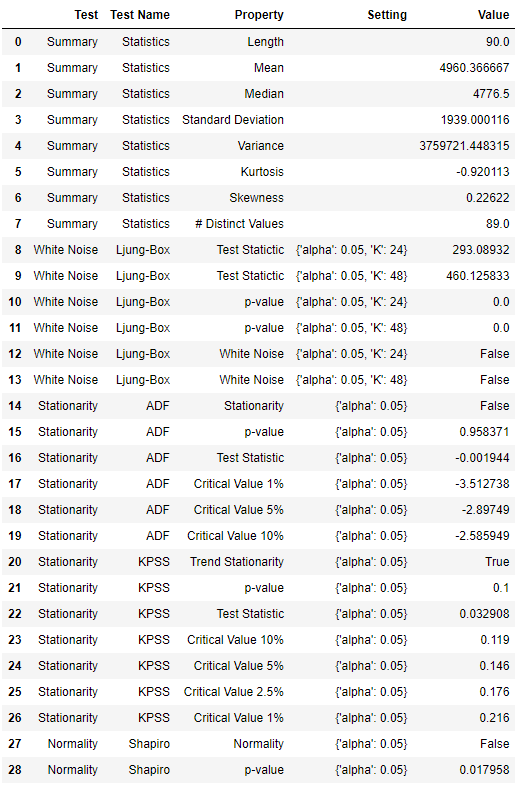
统计测试
check_stats()
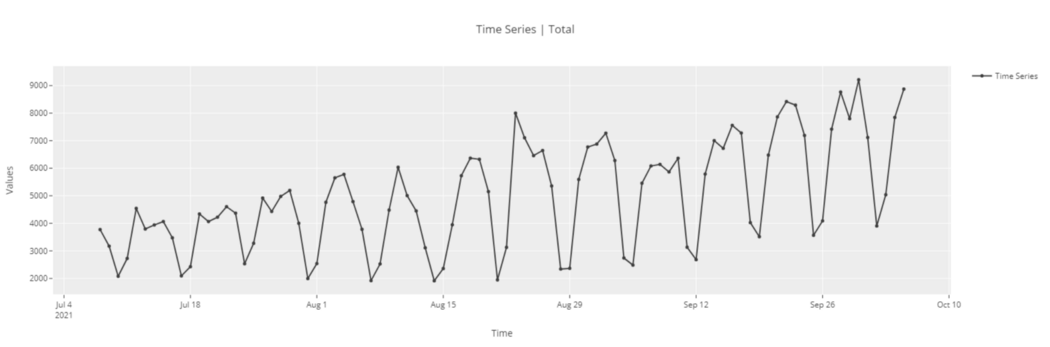
探索性数据分析
# functional API plot_model(plot = 'ts') # object-oriented API exp.plot_model(plot = 'ts')
# cross-validation plot plot_model(plot = 'cv')
# ACF plot plot_model(plot = 'acf')
# Diagnostics plot plot_model(plot = 'diagnostics')
# Decomposition plot plot_model(plot = 'decomp_stl')
模型训练和选择
# functional API best = compare_models() # object-oriented API best = exp.compare_models()
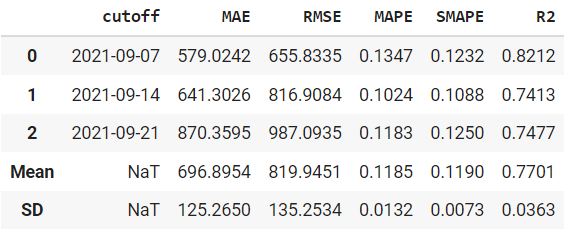
时间序列模块中的 create_model 就像在其他模块中一样。
# create fbprophet model
prophet = create_model('prophet')
print(prophet)

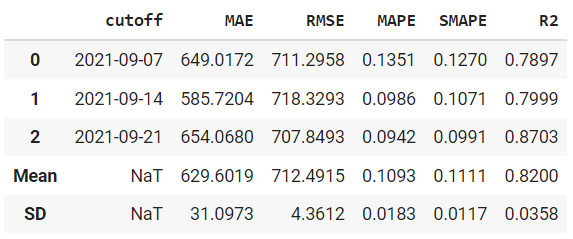
tune_model 也没有太大不同。
tuned_prophet = tune_model(prophet) print(tuned_prophet)
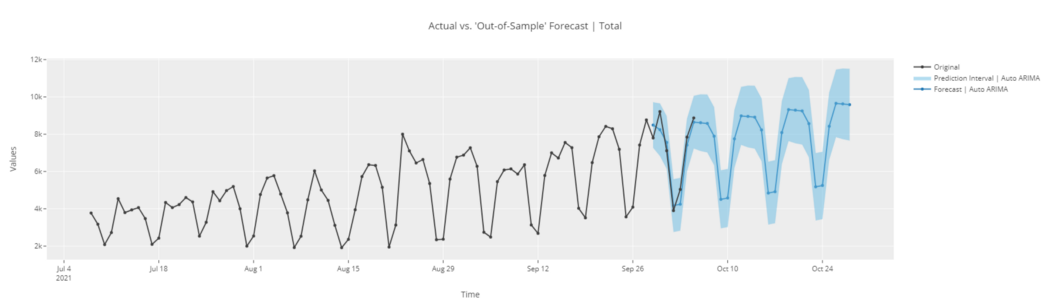
plot_model(best, plot = 'forecast')
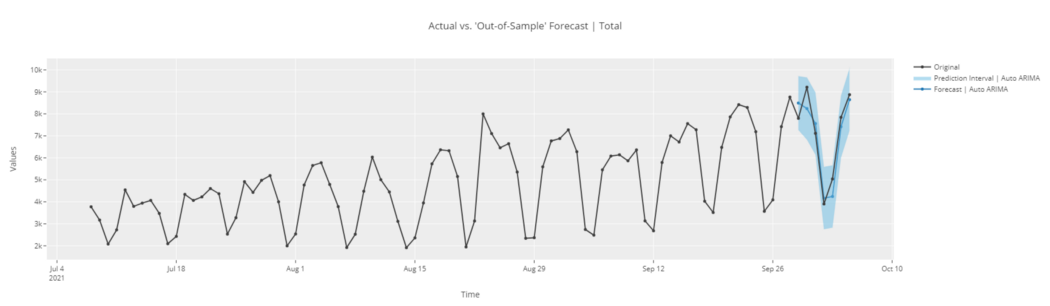
# forecast in unknown future
plot_model(best, plot = 'forecast', data_kwargs = {'fh' : 30})
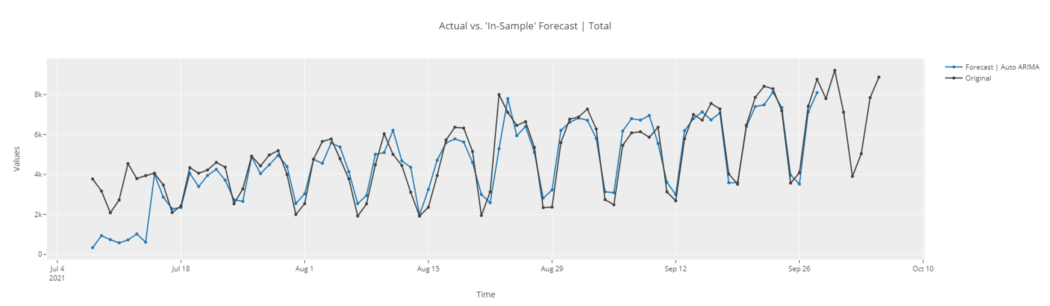
# in-sample plot plot_model(best, plot = 'insample')
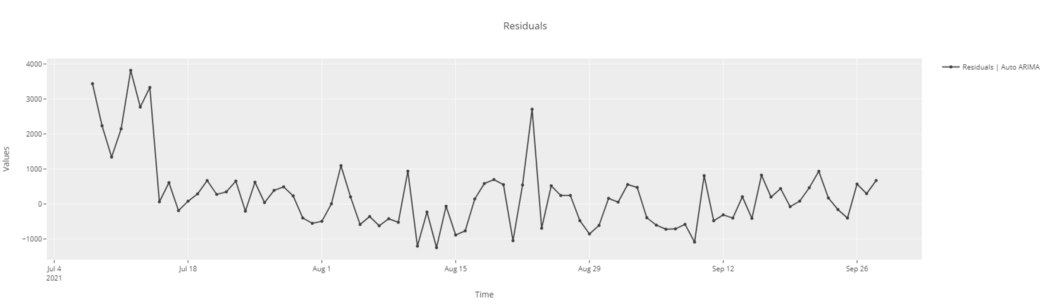
# residuals plot plot_model(best, plot = 'residuals')
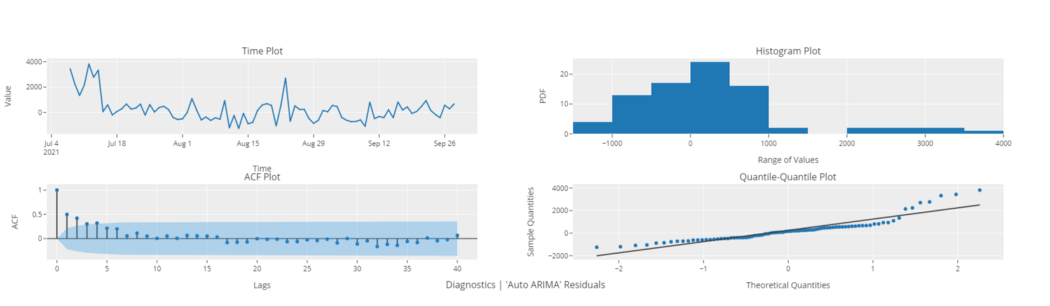
# diagnostics plot plot_model(best, plot = 'diagnostics')
保存模型
# finalize model final_best = finalize_model(best) # generate predictions predict_model(final_best, fh = 90)
# save the model save_model(final_best, 'my_best_model')

以上就是pyCaret效率倍增开源低代码的python机器学习工具的详细内容,更多关于python机器学习工具Pycaret的资料请关注我们其它相关文章!
相关推荐
-

python算法深入理解风控中的KS原理
目录 一.业务背景 二.直观理解区分度的概念 三.KS统计量的定义 四.KS计算过程及业务分析 KS常用的计算方法: 上标指标计算逻辑: 五.风控中选择KS的原因 例1:模糊性 例2:连续性 一.业务背景 在金融风控领域,常常使用KS指标来衡量评估模型的区分度(discrimination),这也是风控模型最为追求的指标之一.下面将从区分度概念.KS计算方法.业务指导意义.几何解析.数学思想等角度,对KS进行深入剖析. 二.直观理解区分度的概念 在数据探索中,若想大致判断自变量x对因变量y有没有
-
python机器学习使数据更鲜活的可视化工具Pandas_Alive
目录 安装方法 使用说明 支持示例展示 水平条形图 垂直条形图比赛 条形图 饼图 多边形地理空间图 多个图表 总结 数据动画可视化制作在日常工作中是非常实用的一项技能.目前支持动画可视化的库主要以Matplotlib-Animation为主,其特点为:配置复杂,保存动图容易报错. 安装方法 pip install pandas_alive # 或者 conda install pandas_alive -c conda-forge 使用说明 pandas_alive 的设计灵感来自 bar_ch
-
python数据可视化JupyterLab实用扩展程序Mito
目录 遇见 Mito 如何启动 Mito 数据透视表 Mito 令人印象深刻的功能 可视化数据 自动代码生成 Mito 安装 JupyterLab 是 Jupyter 主打的最新数据科学生产工具,某种意义上,它的出现是为了取代Jupyter Notebook. 它作为一种基于 web 的集成开发环境,你可以使用它编写notebook.操作终端.编辑markdown文本.打开交互模式.查看csv文件及图片等功能. JupyterLab 最棒的体验就是有丰富的扩展插件,我记得过去我们不得不依赖 nu
-
推荐一款高效的python数据框处理工具Sidetable
目录 安装 用法 1.freq() 2.Counts 3.missing() 4.subtotal() 结论 我们知道 Pandas 是数据科学社区中流行的 Python 包,它包含许多函数和方法来分析数据.尽管它的功能对于数据分析来说足够有效,但定制的库可以为 Pandas 增加更多的价值. Sidetable 就是一个开源 Python 库,它是一种可用于数据分析和探索的工具,作为 value_counts 和 crosstab 的功能组合使用的.在本文中,我们将更多地讨论和探索其功能.欢迎
-
pyCaret效率倍增开源低代码的python机器学习工具
目录 PyCaret 时间序列模块 加载数据 初始化设置 统计测试 探索性数据分析 模型训练和选择 保存模型 PyCaret 是一个开源.低代码的 Python 机器学习库,可自动执行机器学习工作流.它是一种端到端的机器学习和模型管理工具,可以以指数方式加快实验周期并提高您的工作效率.欢迎收藏学习,喜欢点赞支持,文末提供技术交流群. 与其他开源机器学习库相比,PyCaret 是一个替代的低代码库,可用于仅用几行代码替换数百行代码. 这使得实验速度和效率呈指数级增长. PyCaret 本质上是围绕
-
阿里开源低代码引擎和生态建设实战及思考
目录 前言 第一部分 - 低代码体系的架构设计思考 第二部分 - 求同:阿里低代码引擎&UIPaaS 第三部分 - 存异:百花齐放的低代码平台 彩蛋 - 协议对外开放 & 低代码引擎开源 前言 大家好,今天很开心有机会跟大家分享最近几年阿里在低代码领域的思考和实战. 我是力皓,目前已经在前端和后端岗位工作了十多年了,近 3 年专注在低代码领域,是阿里低代码引擎项目负责人. 我的部门是企业智能事业部,我们部门有大量中后台场景,所以我们在 6 年前就开始低代码领域的探索了,并且一直在持续投入,
-
springboot框架阿里开源低代码工具LowCodeEngine
目录 前言 LowCodeEngine简介 搭建低代码平台 使用低代码平台 目标效果 总结 前言 解放双手!推荐一款阿里开源的低代码工具,YYDS! 之前分享过一些低代码相关的文章,发现大家还是比较感兴趣的.之前在我印象中低代码就是通过图形化界面来生成代码而已,其实真正的低代码不仅要负责生成代码,还要负责代码的维护,把它当做一站式开发平台也不为过!最近体验了一把阿里开源的低代码工具LowCodeEngine,确实是一款面向企业级的低代码解决方案,推荐给大家! SpringBoot实战电商项目ma
-
Python机器学习工具scikit-learn的使用笔记
scikit-learn 是基于 Python 语言的机器学习工具 简单高效的数据挖掘和数据分析工具 可供大家在各种环境中重复使用 建立在 NumPy ,SciPy 和 matplotlib 上 开源,可商业使用 - BSD许可证 sklearn 中文文档:http://www.scikitlearn.com.cn/ 官方文档:http://scikit-learn.org/stable/ sklearn官方文档的类容和结构如下: sklearn是基于numpy和scipy的一个机器学习算法库,
-
JS前端可扩展的低代码UI框架Sunmao使用详解
目录 引言 设计原则 1. 明确不同角色的职责 2. 发挥代码的威力,而不是限制 3. 各个层面的可扩展性 4. 专注而不是发散 Sunmao 的工作原理 响应最新的状态 组件间交互 布局与样式 类型安全 在组件间复用代码 可扩展的可视化编辑器 保持开放 引言 尽管现在越来越多的人开始对低代码开发感兴趣,但已有低代码方案的一些局限性仍然让大家有所保留.其中最常见的担忧莫过于低代码缺乏灵活性以及容易被厂商锁定. 显然这样的担忧是合理的,因为大家都不希望在实现特定功能的时候才发现低代码平台无法支持,
-
不到20行代码用Python做一个智能聊天机器人
伴随着自然语言技术和机器学习技术的发展,越来越多的有意思的自然语言小项目呈现在大家的眼前,聊天机器人就是其中最典型的应用,今天小编就带领大家用不到20行代码,运用两种方式搭建属于自己的聊天机器人. 1.神器wxpy库 首先,小编先向大家介绍一下本次运用到的python库,本次项目主要运用到的库有wxpy和chatterbot. wxpy是在 itchat库 的基础上,通过大量接口优化,让模块变得简单易用,并进行了功能上的扩展.什么是接口优化呢,简单来说就是用户直接调用函数,并输入几个参数,就可以
-
一行代码让 Python 的运行速度提高100倍
python一直被病垢运行速度太慢,但是实际上python的执行效率并不慢,慢的是python用的解释器Cpython运行效率太差. "一行代码让python的运行速度提高100倍"这绝不是哗众取宠的论调. 我们来看一下这个最简单的例子,从1一直累加到1亿. 最原始的代码: import time def foo(x,y): tt = time.time() s = 0 for i in range(x,y): s += i print('Time used: {} sec'.form
-
实例代码讲解Python 线程池
大家都知道当任务过多,任务量过大时如果想提高效率的一个最简单的方法就是用多线程去处理,比如爬取上万个网页中的特定数据,以及将爬取数据和清洗数据的工作交给不同的线程去处理,也就是生产者消费者模式,都是典型的多线程使用场景. 那是不是意味着线程数量越多,程序的执行效率就越快呢. 显然不是.线程也是一个对象,是需要占用资源的,线程数量过多的话肯定会消耗过多的资源,同时线程间的上下文切换也是一笔不小的开销,所以有时候开辟过多的线程不但不会提高程序的执行效率,反而会适得其反使程序变慢,得不偿失. 所以,如
-
一行代码实现Python动态加载依赖
目录 快速开始 通过 pip 安装运行 注入代码运行 前几天在一个开源项目里遇到好多用户反馈,不会安装依赖,或者执行 pip install -r requirements.txt 没有反应. 可能造成的原因有很多种,一一排查起来也很麻烦. 想一劳永逸解决这个问题,一般大家都是到 site-packages 里面把所需要的包导出来,放到项目根目录. 但这样终究太过粗糙,不符合Python优雅的个性. 所以我就想,能不能动态引入包,如果没有的话,再调用 pip 下载.最后也差不多实现了我的设想.
-
Go语言驱动低代码应用引擎工具Yao开发管理系统
目录 前言 Yao简介 安裝 使用 基本使用 创建数据模型 编写接口 编写界面 总结 前言 之前写过一篇关于阿里的低代码工具LowCodeEngine的文章,发现大家还是挺感兴趣的.最近又发现了一款很有意思的低代码工具Yao,支持使用JSON的形式开发管理系统,不仅可以用来开发后端API,还能用来开发前端界面,简洁而且高效,推荐给大家! SpringBoot实战电商项目mall(50k+star)地址:https://github.com/macrozheng/mall Yao简介 Yao是一款