R语言刷题检验数据缺失类型过程详解
目录
- 题目
- 解答
- 下面考虑三种情况:
- 1. a = 0, b = 0
- 2. a = 2, b = 0
- 3. a = 0, b = 2
题目


解答
由于题目要求需要重复三次类似的操作,故首先载入所需要的包,构造生成数据的函数以及绘图的函数:
library(tidyr) # 绘图所需
library(ggplot2) # 绘图所需
# 生成数据
GenerateData <- function(a = 0, b = 0, seed = 2018) {
set.seed(seed)
z1 <- rnorm(100)
z2 <- rnorm(100)
z3 <- rnorm(100)
y1 <- 1 + z1
y2 <- 5 + 2 * z1 + z2
u <- a * (y1 - 1) + b * (y2 - 5) + z3
m2 <- 1 * (u < 0)
y2_na <- y2
y2_na[u < 0] <- NA
# y2_na[as.logical(m2)] <- NA
dat_comp <- data.frame(y1 = y1, y2 = y2)
dat_incomp <- data.frame(y1 = y1, y2 = y2_na)
dat_incomp <- na.omit(dat_incomp)
return(list(dat_comp = dat_comp, dat_incomp = dat_incomp))
}
# 展现缺失出具与未缺失数据的分布情况
PlotTwoDistribution <- function(dat) {
p1 <- dat_comp %>%
gather(y1, y2, key = "var", value = "value") %>%
ggplot(aes(x = value)) +
geom_histogram(aes(fill = factor(var), y = ..density..),
alpha = 0.3, colour = 'black') +
stat_density(geom = 'line', position = 'identity', size = 1.5,
aes(colour = factor(var))) +
facet_wrap(~ var, ncol = 2) +
labs(y = '直方图与密度曲线', x = '值',
title = '完整无缺失数据', fill = '变量') +
theme(plot.title = element_text(hjust = 0.5)) +
guides(color = FALSE)
p2 <- dat_incomp %>%
gather(y1, y2, key = "var", value = "value") %>%
ggplot(aes(x = value)) +
geom_histogram(aes(fill = factor(var), y = ..density..),
alpha = 0.3, colour = 'black') +
stat_density(geom = 'line', position = 'identity', size = 1.5,
aes(colour = factor(var))) +
facet_wrap(~ var, ncol = 2) +
labs(y = '直方图与密度曲线', x = '值',
title = '有缺失数据', fill = '变量') +
theme(plot.title = element_text(hjust = 0.5)) +
guides(color = FALSE)
return(list(p_comp = p1, p_incomp = p2))
}
下面考虑三种情况:
1. a = 0, b = 0
a) 生成数据并绘图展示
# 生成数据并查看数据样式 dat <- GenerateData(a = 0, b = 0) dat_comp <- dat$dat_comp dat_incomp <- dat$dat_incomp head(dat_comp) head(dat_incomp)
# 绘图展示 p <- PlotTwoDistribution(dat) p$p_comp p$p_incomp
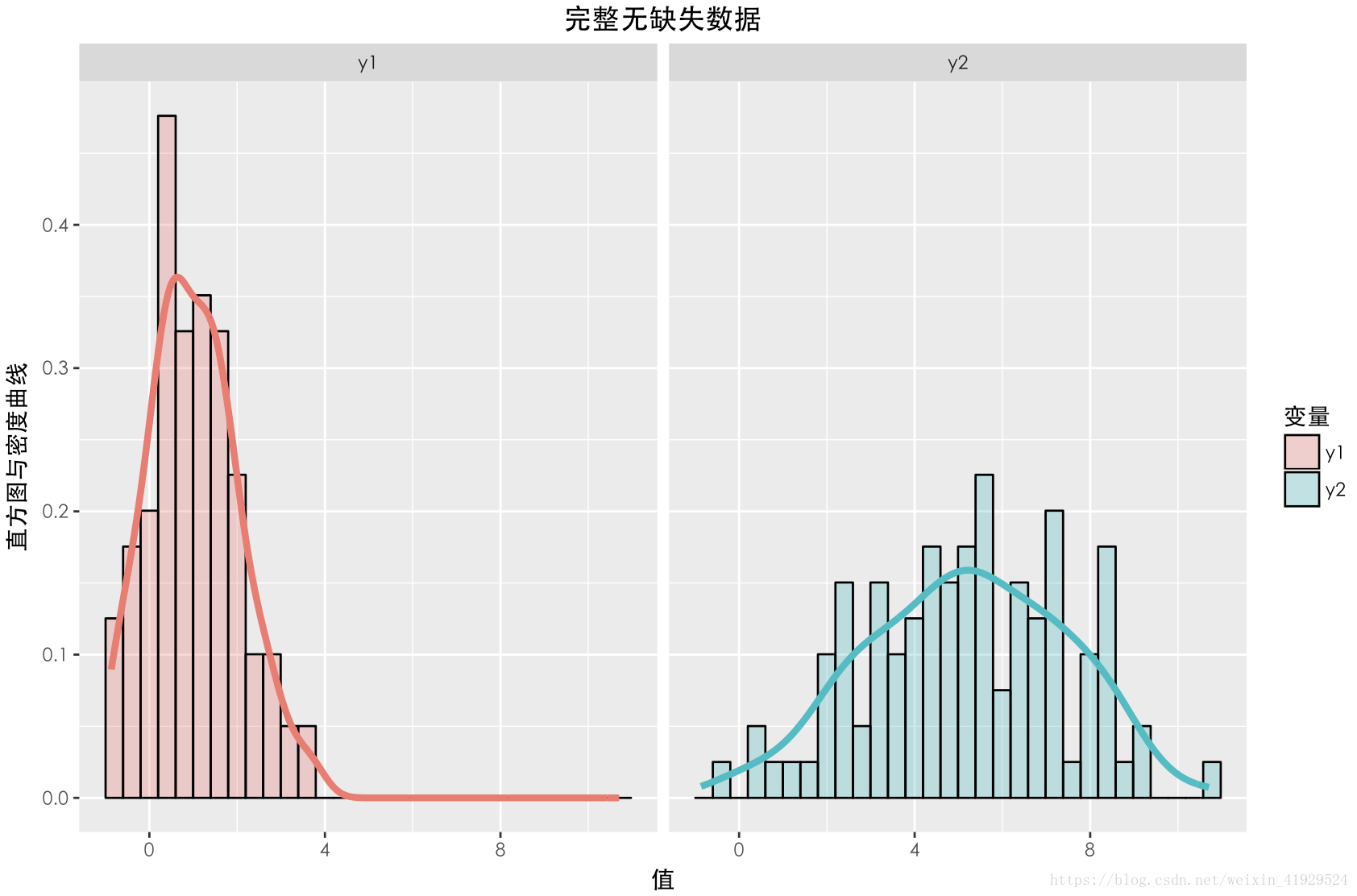
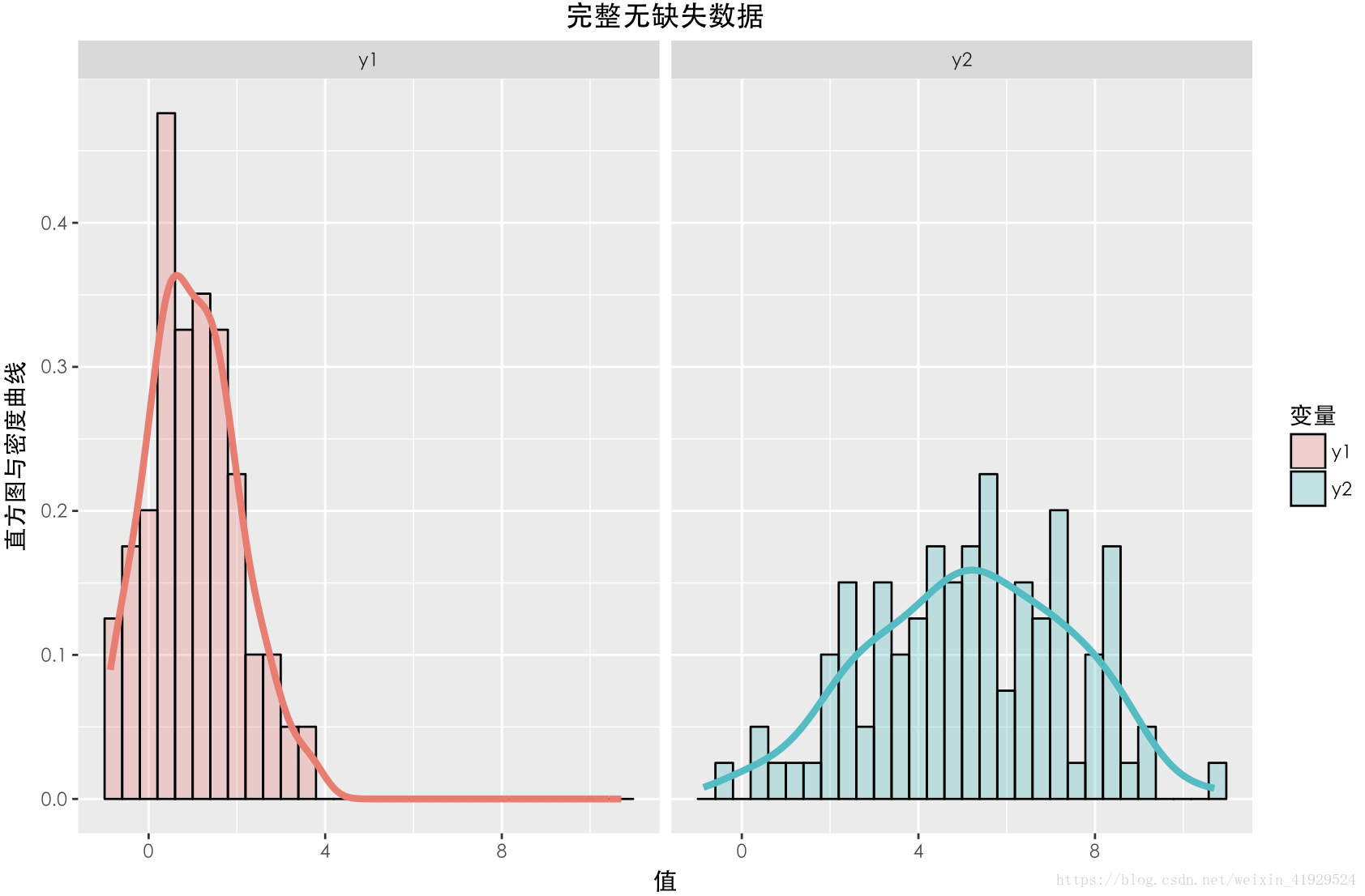
缺失数据与未缺失数据的分布如上图所示。可以发现,对于完整数据与缺失数据之间的 Y1的分布与 Y2的分布与期望相差不大。并且在采用 a=0,b=0这种构造时,从构造的公式可以看出, Y2中样本的缺失情况与 Y1,Y2两者都无关(因为 Z 3 与 Y 1 , Y 2 均独立),所以这种缺失机制是:MCAR。
b) 进行t检验
题设条件中说的是 Y 1 Y_1 Y1的均值,所以考虑完整数据与缺失数据(这里的缺失指的是若 Y 2 Y_2 Y2有缺失, Y 1 Y_1 Y1也会进行相应地缺失处理)
t.test(dat_comp$y1, dat_incomp$y1)
这里进行t检验(其实不是非常严谨,因为不一定满足正态假设),比较缺失与否 Y 1 Y_1 Y1的均值,这里p-value = 0.8334。在显著性水平为0.05的前提下,并不能断言有缺失与无缺失两个 Y 1 Y_1 Y1之间的均值有差异,也就是说其实MCAR, MAR, NMAR三种情况都有可能,并不能断言哪种不可能发生。
2. a = 2, b = 0
a) 生成数据并绘图展示
# 生成数据并查看数据样式 dat <- GenerateData(a = 2, b = 0) dat_comp <- dat$dat_comp dat_incomp <- dat$dat_incomp head(dat_comp) head(dat_incomp)
# 绘图展示 p <- PlotTwoDistribution(dat) p$p_comp p$p_incomp

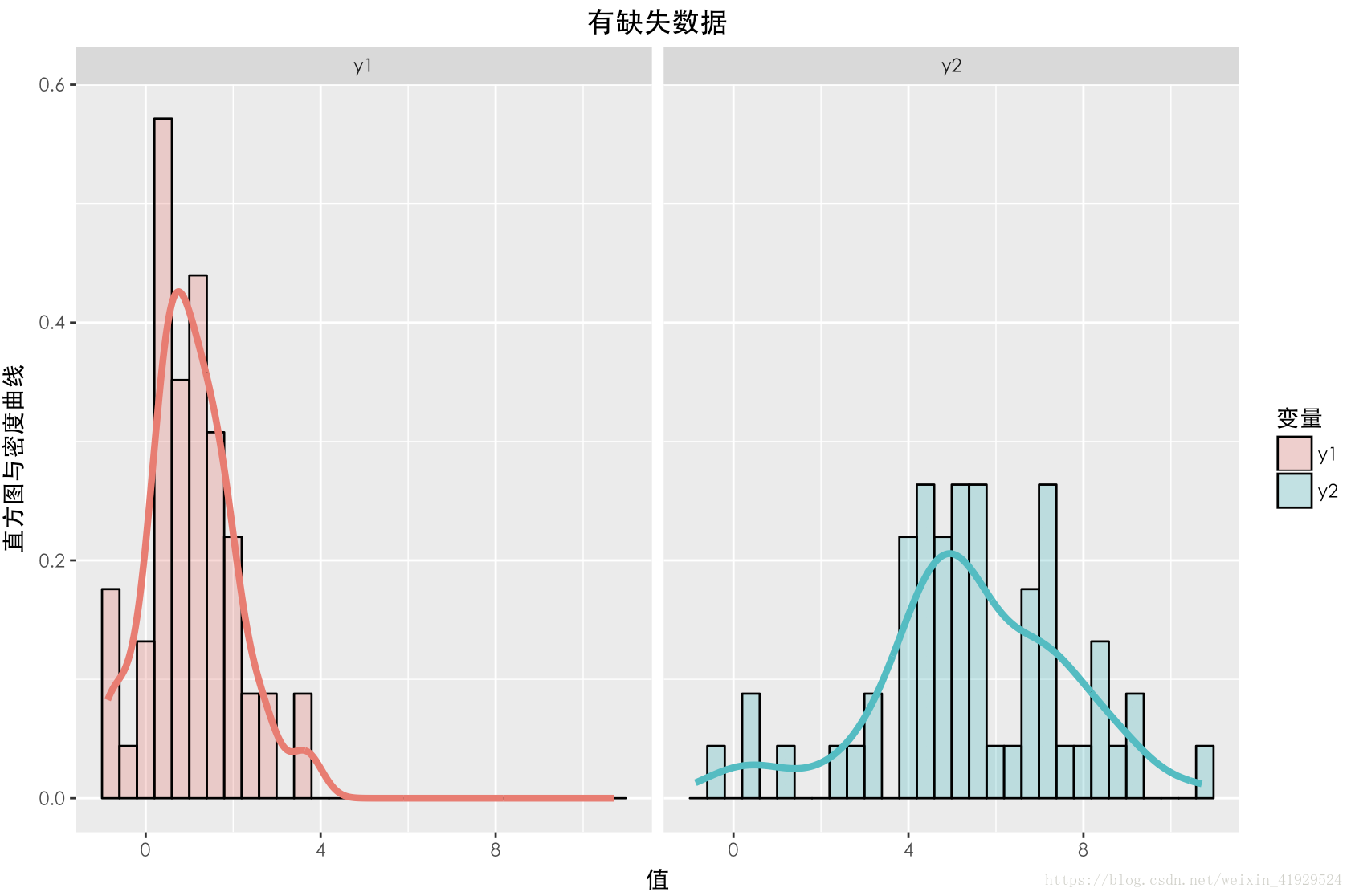
缺失数据与未缺失数据的分布如上图所示。可以发现,两个数据的期望以及分布(无论 Y 1 Y_1 Y1还是 Y 2 Y_2 Y2),整体都有一定差异。在采用 a = 2 , b = 0 a = 2, b = 0 a=2,b=0这种构造时,从构造的公式可以看出, Y 2 Y_2 Y2中样本的缺失情况与 Y 1 Y_1 Y1有关,所以这种缺失机制是:MAR。
b) 进行t检验
t.test(dat_comp$y1, dat_incomp$y1)

3. a = 0, b = 2
a) 生成数据并绘图展示
# 生成数据并查看数据样式 dat <- GenerateData(a = 0, b = 2) dat_comp <- dat$dat_comp dat_incomp <- dat$dat_incomp head(dat_comp) head(dat_incomp)
# 绘图展示 p <- PlotTwoDistribution(dat) p$p_comp p$p_incomp
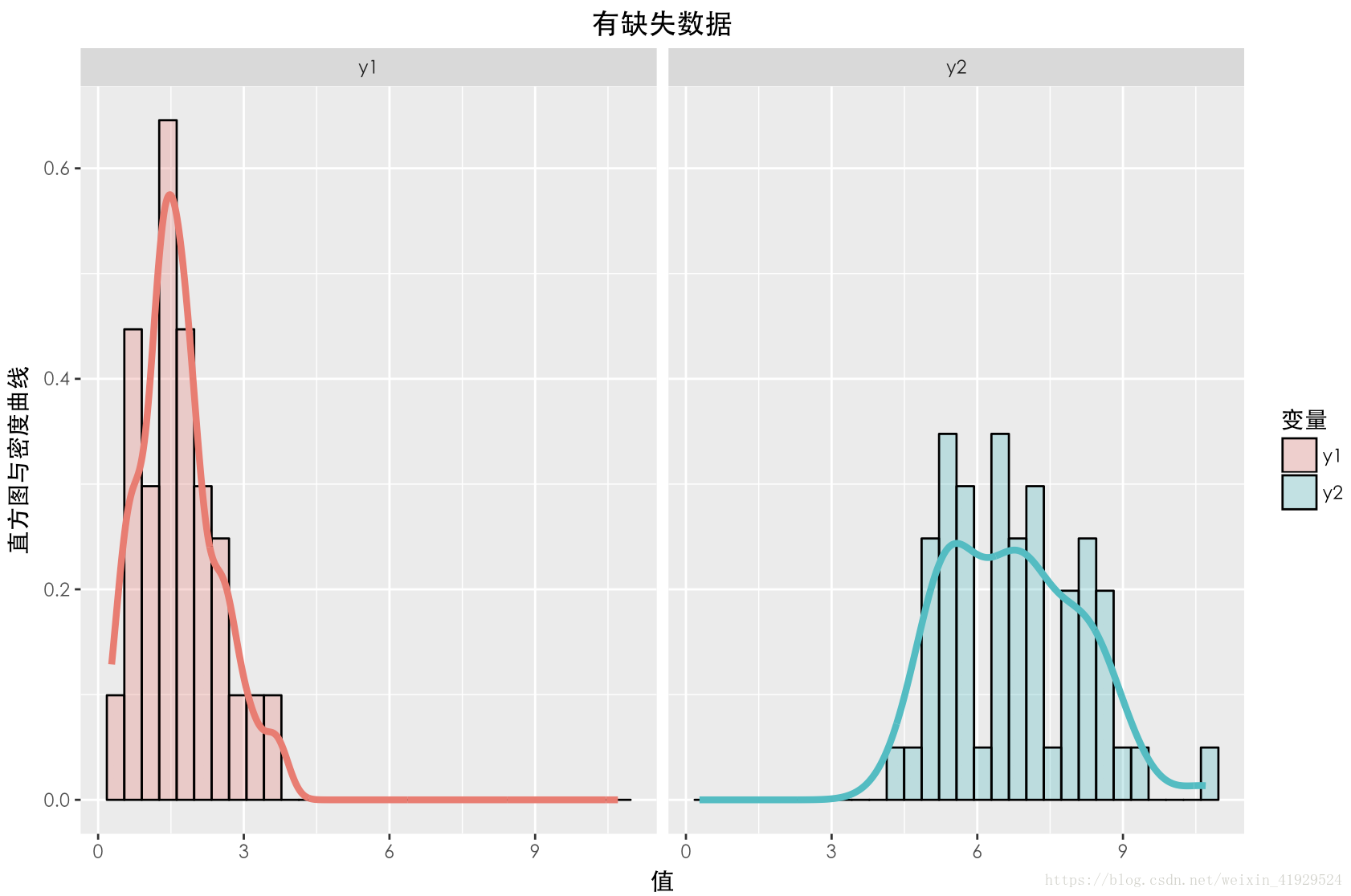
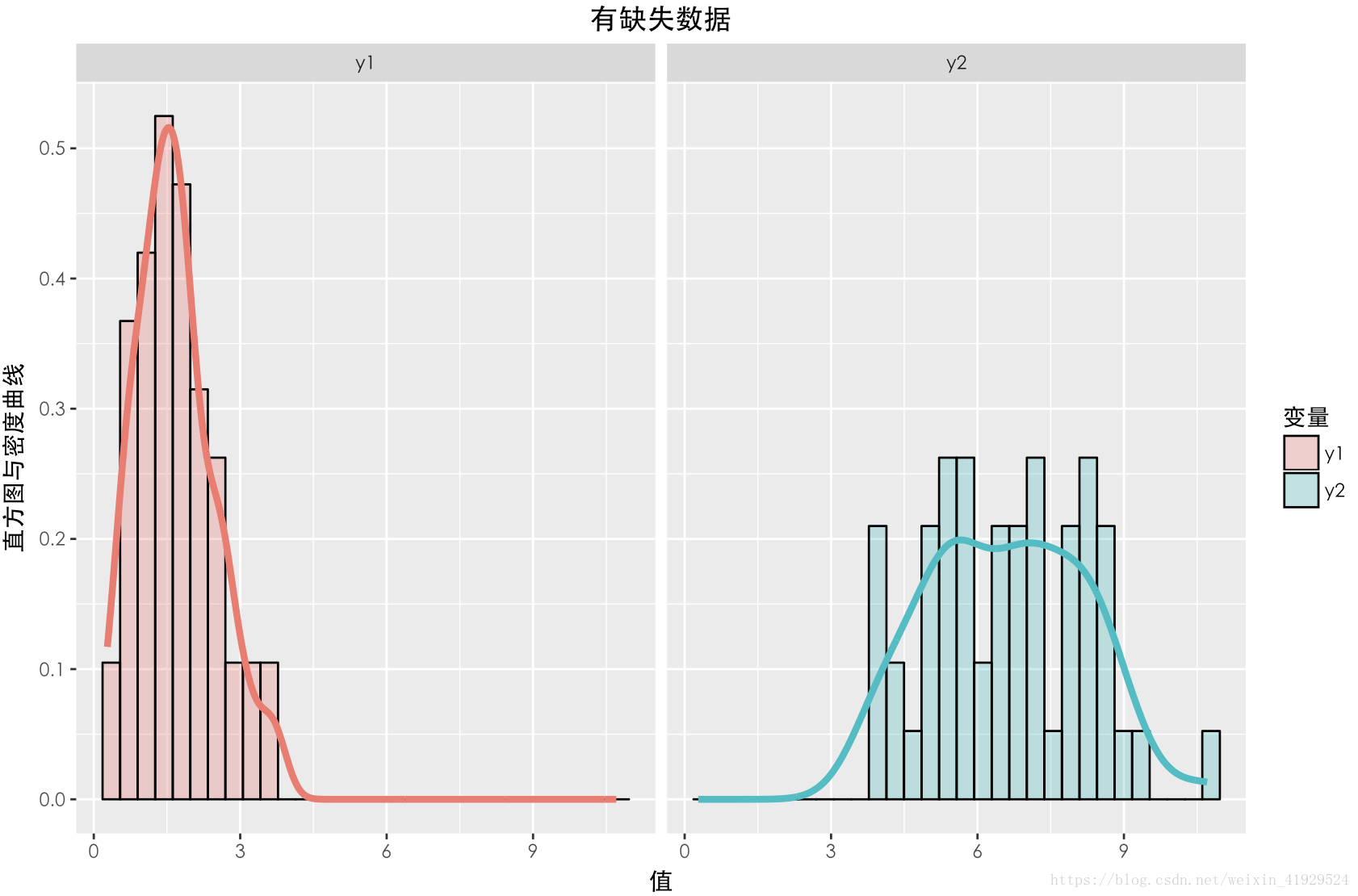
缺失数据与未缺失数据的分布如上图所示。可以发现与上一种情况一样,两个数据的期望以及分布(无论 Y1还是 Y2),整体都有一定差异。在采用 a = 0 , b = 2 这种构造时,从构造的公式可以看出,Y2中样本的缺失情况与 Y2本身有关,所以这种缺失机制是:NMAR。
b) 进行t检验
t.test(dat_comp$y1, dat_incomp$y1)

以上就是R语言刷题检验数据缺失类型过程详解的详细内容,更多关于R语言检验数据缺失类型的资料请关注我们其它相关文章!
相关推荐
-
R语言常见面试题整理
尊敬的读者,这些R语言面试题是专门设计的,以便您应对在R语言相关面试中可能会被问到的问题. 根据我的经验,良好的面试官几乎不打算在你的面试中问任何特定的问题,通常都是以如下的问题为开端进一步展开后继的问题. 什么是R语言编程? R语言是一种用于统计分析和为此目的创建图形的编程语言.不是数据类型,它具有用于计算的数据对象.它用于数据挖掘,回归分析,概率估计等领域,使用其中可用的许多软件包. R语言中的不同数据对象是什么? 它们是R语言中的6个数据对象.它们是向量,列表,数组,矩阵,数据框和表. 什
-

R语言 出现矩阵/缺失值的解决方案
缺失值处理一般包括三步: 1. 识别缺失数据: 2. 检查导致数据缺失的原因: 3. 删除包含缺失值的实例或用合理的数值代替(插补)缺失值. 1.判断缺失值 函数is.na().is.nan()和is.infinite()可分别用来识别缺失值.不可能值和无穷值.每个返回结果都是 TRUE或FALSE na表示缺失值 nan表示NOT A NUMBER infinite表示+-Inf 一定要亲手试x = 0/0,以及x = 1/0 >x <- NA > is.na(x) [1] TRUE
-
R语言中的五种常用统计分析方法
1.分组分析aggregation 根据分组字段,将分析对象划分为不同的部分,以进行对比分析各组之间差异性的一种分析方法. 常用统计指标: 计数 length 求和 sum 平均值 mean 标准差 var 方差 sd 分组统计函数 aggregate(分组表达式,data=需要分组的数据框,function=统计函数) 参数说明 formula:分组表达式,格式:统计列~分组列1+分组列2+... data=需要分组的数据框 function:统计函数 aggregate(name ~ cla
-
R语言数据类型深入详解
R语言用来存储数据的对象包括: 向量, 因子, 数组, 矩阵, 数据框, 时间序列(ts)以及列表 意义介绍 1. 向量(一维数据): 只能存放同一类型的数据 语法: c(data1, data2, ...),访问的时候下标从1开始(和Matlab相同);向量里面只能存放相同类型的数据. > x <- c(1,5,8,9,1,2,5) > x [1] 1 5 8 9 1 2 5 > y <- c(1,"zhao") # 这里面有integer和字符串, 整
-
R语言刷题检验数据缺失类型过程详解
目录 题目 解答 下面考虑三种情况: 1. a = 0, b = 0 2. a = 2, b = 0 3. a = 0, b = 2 题目 解答 由于题目要求需要重复三次类似的操作,故首先载入所需要的包,构造生成数据的函数以及绘图的函数: library(tidyr) # 绘图所需 library(ggplot2) # 绘图所需 # 生成数据 GenerateData <- function(a = 0, b = 0, seed = 2018) { set.seed(seed) z1 <- r
-
R语言行筛选的方法之filter函数详解
目录 1. 数据 2. 生成ID列和类型 3. 提取effect大于0.1的行 4. 提取加性效应,且effect小于0的行 5. 根据部分行名删选 6. 固定字符特征进行行筛选 总结 下面介绍一下R语言中行筛选的方法,主要介绍filter函数 1. 数据 这里,使用asreml分析中的BLUP值为例,相关的模型为: m1 = asreml(Phen ~ G , random = ~ vm(Progeny,ainv) + vm(Dam,ainv) + vm(Progeny,dinv), work
-
R语言常用两种并行方法之parallel详解
目录 并行计算 在模拟时什么地方可以用到并行? 怎么在R中看我们可以使用并行? parallel(简单) 由于最近在进行一些论文的模拟,所以尝试了两种并行的方法:parallel与snowfall,这两种方法各有优缺,但还是推荐snowfall,整体较为稳定,不容易因为内存不足或者并行线程过多等原因而报错. 并行计算 并行计算: 简单来讲,就是同时使用多个计算资源来解决一个计算问题,是提高计算机系统计算速度和处理能力的一种有效手段.(参考:并行计算简介) 一个问题被分解成为一系列可以并发执行的离
-
R语言常用两种并行方法之snowfall详解
上一篇博客(R中两种常用并行方法之parallel)中已经介绍了R中常见的一种并行包:parallel,其有着简单便捷等优势,其实缺点也是非常明显,就是很不稳定.很多时候我们将大量的计算任务挂到服务器上进行运行时,更看重的是其稳定性. 这时就要介绍R中的另一个并行利器--snowfall,这也是在平时做模拟时用的最多的一种方法. 针对上篇中的简单例子 首先是一个最简单的并行的例子,这个例子不需要载入任何依赖库.函数.对象等.相对也比较简单: library(snowfall) # 载入snowf
-
C语言三子棋的实现思路到过程详解
目录 一.三子棋小游戏的简单介绍 二.三子棋的思路及代码实现 1.打印游戏菜单 2.选择是否开始游戏 3.创建并且初始化棋盘 3.1.创建棋盘 3.2.初始化棋盘 4.打印格式化棋盘 5.玩家下棋 6.电脑下棋 7.判断是否玩家或者电脑赢 三.整合三子棋游戏代码 game.h game.c test.c 一.三子棋小游戏的简单介绍 要说大家都很熟悉的一个小游戏,三子棋算是其中一个了.相信大家都玩过三子棋小游戏,在这里我还是给大家介绍简单的游戏规则: 一次只能下一个棋子: 玩家下完棋子后,电脑下棋
-
springmvc数据的封装过程详解
spring封装是进行orm封装,可以进行定义数据类型,数据名与接收名相同,进行接收,或者定义类,类的属性名与接收名相同 单个数据类型如图下: 对象类型封装: 其他:乱码处理 在中文字符乱码,需要规定请求响应的编码,可以自己进行过滤器进行过滤设置,但是jar包中给我们提供了此过滤器,我们只需要进行web.xml配置即可 init-param规定的是编译的类型 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们.
-
Node在Controller层进行数据校验的过程详解
前言 幽默风趣的后端程序员一般自嘲为 CURD Boy.CURD, 也就是对某一存储资源的增删改查,这完全是面向数据编程啊. 真好呀,面向数据编程,往往会对业务理解地更加透彻,从而写出更高质量的代码,造出更少的 BUG.既然是面向数据编程那更需要避免脏数据的出现,加强数据校验.否则,难道要相信前端的数据校验吗,毕竟前端数据校验直达用户,是为了 UI 层更友好的用户反馈. 数据校验层 后端由于重业务逻辑以及待处理各种数据,以致于分成各种各样的层级,以我经历过的后端项目就有分为 Controller
-
利用Spring MVC+Mybatis实现Mysql分页数据查询的过程详解
前言 因为最近没什么事,所以想着写一个分页的例子出来给大家分享一下.这个案例分前端和后台两部分,前端使用面向对象的方式写的,里面用到了一些回调函数和事件代理,有兴趣的朋友可以研究一下.后台的实现技术是将分页Pager作为一个实体对象放到domain层,当前页.单页数据量.当前页开始数.当前页结束数.总数据条数.总页数都作为成员属性放到实体类里面. 以前项目数据库用的是oracle,sql语句的写法会从当前页开始数到当前页结束数查询数据.刚刚在这纠结了很长时间,查询到的数据显示数量总是有偏差,后来
-
使用python将excel数据导入数据库过程详解
因为需要对数据处理,将excel数据导入到数据库,记录一下过程. 使用到的库:xlrd 和 pymysql (如果需要写到excel可以使用xlwt) 直接丢代码,使用python3,注释比较清楚. import xlrd import pymysql # import importlib # importlib.reload(sys) #出现呢reload错误使用 def open_excel(): try: book = xlrd.open_workbook("XX.xlsx")
-
微信小程序 动态修改页面数据及参数传递过程详解
在小程序中我们经常要动态渲染数据,对于新手而言我们常常遇到修改的数据在控制台显示和页面显示不一致,因为我们用"="修改数据的,这种是可以修改,但无法改变页面的状态的,还会造成数据不一致,代码如下: data: { array: [{ text: '数组' }] } onLoad:function(){ this.data.array[0].text=1; console.log(this.data.array[0].text); } 修改代码: onLoad:function(){ /