详解Python数据分析--Pandas知识点
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘
1. 重复值的处理
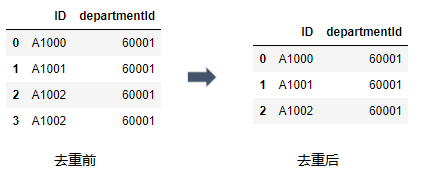
利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID.
import pandas as pd
df = pd.DataFrame({"ID": ["A1000","A1001","A1002", "A1002"],
"departmentId": [60001,60001, 60001, 60001]})
df.drop_duplicates()
2. 缺失值的处理
缺失值是数据中因缺少信息而造成的数据聚类, 分组, 截断等
2.1 缺失值产生的原因
主要原因可以分为两种: 人为原因和机械原因.
1) 人为原因: 由于人的主观失误造成数据的缺失, 比如数据录入人员的疏漏;
2) 机械原因: 由于机械故障导致的数据收集或者数据保存失败从而造成数据的缺失.
2.2 缺失值的处理方式
缺失值的处理方式通常有三种: 补齐缺失值, 删除缺失值, 删除缺失值, 保留缺失值.
1) 补齐缺失值: 使用计算出来的值去填充缺失值, 例如样本平均值.
使用fillna()函数对缺失值进行填充, 使用mean()函数计算样本平均值.
import pandas as pd
import numpy as np
df = pd.DataFrame({'ID':['A10001', 'A10002', 'A10003', 'A10004'],
"Salary":[11560, np.NaN, 12988,12080]})
#用Salary字段的样本均值填充缺失值
df["Salary"] = df["Salary"].fillna(df["Salary"].mean())
df

2) 删除缺失值: 当数据量大时且缺失值占比较小可选用删除缺失值的记录.
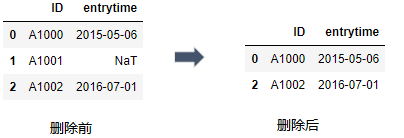
示例: 删除entrytime中缺失的值,采用dropna函数对缺失值进行删除:
import pandas as pd
df = pd.DataFrame({"ID": ["A1000","A1001","A1002"],
"entrytime": ["2015-05-06",pd.NaT,"2016-07-01" ]})
df.dropna()
3) 保留缺失值.
3. 删除前后空格
使用strip()函数删除前后空格.
import pandas as pd
df = pd.DataFrame({"ID": ["A1000","A1001","A1002"],
"Surname": [" Zhao ","Qian"," Sun " ]})
df["Surname"] = df["Surname"].str.strip()
df

4. 查看数据类型
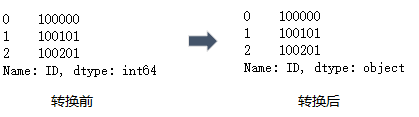
查看所有列的数据类型使用dtypes, 查看单列使用dtype, 具体用法如下:
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
#查看所有列的数据类型
df.dtypes
#查看单列的数据类型
df["ID"].dtype

5. 修改数据类型
使用astype()函数对数据类型进行修改, 用法如下
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
#将ID列的类型转化为字符串的格式
df["ID"].astype(str)
6. 字段的抽取
使用slice(start, end)函数可完成字段的抽取, 注意start是从0开始且不包含end. 比如抽取前两位slice(0, 2).
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname": [" Zhao ","Qian"," Sun " ]})
#需要将ID列的类型转换为字符串, 否则无法使用slice()函数
df["ID"]= df["ID"].astype(str)
#抽取ID前两位
df["ID"].str.slice(0,2)

7. 字段的拆分
使用split()函数进行字段的拆分, split(pat=None, n = -1, expand=True)函数包含三个参数:
第一个参数则是分隔的字符串, 默认是以空格分隔
第二个参数则是分隔符使用的次数, 默认分隔所有
第三个参数若是True, 则在不同的列展开, 否则以序列的形式显示.
import pandas as pd
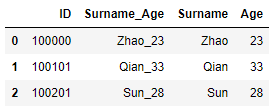
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
#对Surname_Age字段进行拆分
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new

8. 字段的命名
有两种方式一种是使用rename()函数, 另一种是直接设置columns参数
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
#第一种方法使用rename()函数
# df_new = df["Surname_Age"].str.split("_", expand =True).rename(columns={0: "Surname", 1: "Age"})
# df_new
#第二种方法直接设置columns参数
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
df_new
两种方式同样的结果:

9. 字段的合并
使用merge()函数对字段进行合并操作.
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
#使用merge函数对两表的字段进行合并操作.
pd.merge(df, df_new, left_index =True, right_index=True)
10. 字段的删除
利用drop()函数对字段进行删除.
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
df_mer= pd.merge(df, df_new, left_index =True, right_index=True)
#drop()删除字段,第一个参数指要删除的字段,axis=1表示字段所在列,inplace为True表示在当前表执行删除.
df_mer.drop("Surname_Age", axis = 1, inplace =True)
df_mer
删除Surname_Age字段成功:
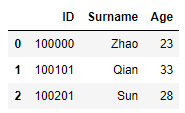
11. 记录的抽取
1) 关系运算: df[df.字段名 关系运算符 数值], 比如抽取年龄大于30岁的记录.
import pandas as pd
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28" ]})
df_new = df["Surname_Age"].str.split("_", expand =True)
df_new.columns = ["Surname","Age"]
df_mer= pd.merge(df, df_new, left_index =True, right_index=True)
df_mer.drop("Surname_Age", axis = 1, inplace =True)
#将Age字段数据类型转化为整型
df_mer["Age"] = df_mer["Age"].astype(int)
#抽取Age中大于30的记录
df_mer[df_mer.Age > 30]
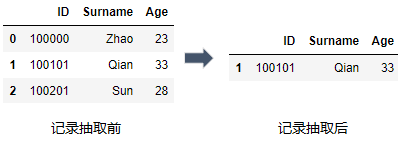
2) 范围运算: df[df.字段名.between(s1, s2)], 注意既包含s1又包含s2, 比如抽取年龄大于等于23小于等于28的记录.
df_mer[df_mer.Age.between(23,28)]
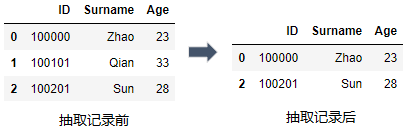
3) 逻辑运算: 与(&) 或(|) 非(not)
比如上面的范围运算df_mer[df_mer.Age.between(23,28)]就等同于df_mer[(df_mer.Age >= 23) & (df_mer.Age <= 28)]
df_mer[(df_mer.Age >= 23 ) & (df_mer.Age <= 28)]

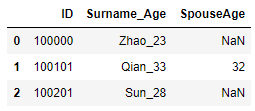
4) 字符匹配: df[df.字段名.str.contains("字符", case = True, na =False)] contains()函数中case=True表示区分大小写, 默认为True; na = False表示不匹配缺失值.
import pandas as pd
import numpy as np
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28"],"SpouseAge":[np.NaN,"32",np.NaN]})
#匹配SpouseAge中包含2的记录
df[df.SpouseAge.str.contains("2",na = False)]

当na改为True时, 结果为:
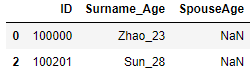
5) 缺失值匹配:df[pd.isnull(df.字段名)]表示匹配该字段中有缺失值的记录.
import pandas as pd
import numpy as np
df = pd.DataFrame({"ID": [100000,100101,100201],"Surname_Age": ["Zhao_23","Qian_33","Sun_28"],"SpouseAge":[np.NaN,"32",np.NaN]})
#匹配SpouseAge中有缺失值的记录
df[pd.isnull(df.SpouseAge)]
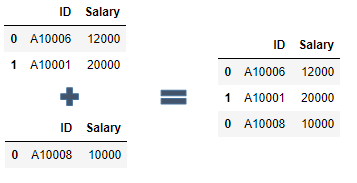
12.记录的合并
使用concat()函数可以将两个或者多个数据表的记录合并一起, 用法: pandas.concat([df1, df2, df3.....])
import pandas as pd
df1 = pd.DataFrame({"ID": ["A10006","A10001"],"Salary": [12000, 20000]})
df2 = pd.DataFrame({"ID": ["A10008"], "Salary": [10000]})
#使用concat()函数将df1与df2的记录进行合并
pd.concat([df1, df2])
以上是部分内容, 还会持续总结更新....
以上所述是小编给大家介绍的Python数据分析--Pandas知识点详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Python数据分析:手把手教你用Pandas生成可视化图表的教程
大家都知道,Matplotlib 是众多 Python 可视化包的鼻祖,也是Python最常用的标准可视化库,其功能非常强大,同时也非常复杂,想要搞明白并非易事.但自从Python进入3.0时代以后,pandas的使用变得更加普及,它的身影经常见于市场分析.爬虫.金融分析以及科学计算中. 作为数据分析工具的集大成者,pandas作者曾说,pandas中的可视化功能比plt更加简便和功能强大.实际上,如果是对图表细节有极高要求,那么建议大家使用matplotlib通过底层图表模块进行编码.当然,我
-
详解10个可以快速用Python进行数据分析的小技巧
一些小提示和小技巧可能是非常有用的,特别是在编程领域.有时候使用一点点黑客技术,既可以节省时间,还可能挽救"生命". 一个小小的快捷方式或附加组件有时真是天赐之物,并且可以成为真正的生产力助推器.所以,这里有一些小提示和小技巧,有些可能是新的,但我相信在下一个数据分析项目中会让你非常方便. Pandas中数据框数据的Profiling过程 Profiling(分析器)是一个帮助我们理解数据的过程,而Pandas Profiling是一个Python包,它可以简单快速地对Pandas 的
-
Python实现的大数据分析操作系统日志功能示例
本文实例讲述了Python实现的大数据分析操作系统日志功能.分享给大家供大家参考,具体如下: 一 代码 1.大文件切分 import os import os.path import time def FileSplit(sourceFile, targetFolder): if not os.path.isfile(sourceFile): print(sourceFile, ' does not exist.') return if not os.path.isdir(targetFolde
-
使用Python对微信好友进行数据分析
1.准备工作 1.1 库介绍 只有登录微信才能获取到微信好友的信息,本文采用wxpy该第三方库进行微信的登录以及信息的获取. wxpy 在 itchat 的基础上,通过大量接口优化提升了模块的易用性,并进行丰富的功能扩展. wxpy一些常见的场景: •控制路由器.智能家居等具有开放接口的玩意儿 •运行脚本时自动把日志发送到你的微信 •加群主为好友,自动拉进群中 •跨号或跨群转发消息 •自动陪人聊天 •逗人玩 总而言之,可用来实现各种微信个人号的自动化操作. 1.2 wxpy库安装 wxpy 支持
-
Python数据分析matplotlib设置多个子图的间距方法
注意,要看懂这里,必须具备简单的Python数据分析知识,必须知道matplotlib的简单使用! 例1: plt.subplot(221) # 第一行的左图 plt.subplot(222) # 第一行的右图 plt.subplot(212) # 第二整行 plt.title('xxx') plt.tight_layout() #设置默认的间距 例2: for i in range(25): plt.subplot(5,5,i+1) plt.tight_layout() 例3: # 设定画图板
-

python微信好友数据分析详解
基于微信开放的个人号接口python库itchat,实现对微信好友的获取,并对省份.性别.微信签名做数据分析. 效果: 直接上代码,建三个空文本文件stopwords.txt,newdit.txt.unionWords.txt,下载字体simhei.ttf或删除字体要求的代码,就可以直接运行. #wxfriends.py 2018-07-09 import itchat import sys import pandas as pd import matplotlib.pyplot as plt
-
选择python进行数据分析的理由和优势
1.python大量的库为数据分析提供了完整的工具集 2.比起MATLAB.R语言等其他主要用于数据分析语言,python语言功能更加健全 3.python库一直在增加,算法的实现采取的方法更加创新 4.python能很方便的对接其他语言,比如c.java等 什么是IPython? IPython是一个python的交互式的shell (它默认的python shell要好用的多.强大的多) 1.支持代码的自动补全.自动缩进,已经支持bash shell 2.Jupyter NoteBook(以
-
详解Python数据分析--Pandas知识点
本文主要是总结学习pandas过程中用到的函数和方法, 在此记录, 防止遗忘 1. 重复值的处理 利用drop_duplicates()函数删除数据表中重复多余的记录, 比如删除重复多余的ID. import pandas as pd df = pd.DataFrame({"ID": ["A1000","A1001","A1002", "A1002"], "departmentId":
-
详解Python中pandas的安装操作说明(傻瓜版)
很多人来问我pandas的安装(python数据分析里面的必修课) 步骤如下: 安装python的时候,把路径加到系统里,这样,随时可以用pip 路径添加方法: 查找路径: 路径1: 2.例如: 即:C:\Users\Administrator\AppData\Local\Programs\Python\Python36-32 路径2: 打开文件夹"Scripts" 例如:C:\Users\Administrator\AppData\Local\Programs\Python\Pyth
-
Python数据分析pandas模块用法实例详解
本文实例讲述了Python数据分析pandas模块用法.分享给大家供大家参考,具体如下: pandas pandas10分钟入门,可以查看官网:10 minutes to pandas 也可以查看更复杂的cookbook pandas是非常强大的数据分析包,pandas 是基于 Numpy 构建的含有更高级数据结构和工具的数据分析包.就好比 Numpy的核心是 ndarray,pandas 围绕着 Series 和 DataFrame 两个核心数据结构展开 .Series和DataFrame 分
-
详解python爬取弹幕与数据分析
很不幸的是,由于疫情的关系,原本线下的AWD改成线上CTF了.这就很难受了,毕竟AWD还是要比CTF难一些的,与人斗现在变成了与主办方斗. 虽然无奈归无奈,但是现在还是得打起精神去面对下一场比赛.这个开始也是线下的,决赛地点在南京,后来是由于疫情的关系也成了线上. 当然,比赛内容还是一如既往的得现学,内容是关于大数据的. 由于我们学校之前并没有开设过相关培训,所以也只能自己琢磨了. 好了,废话先不多说了,正文开始. 一.比赛介绍 大数据总体来说分为三个过程. 第一个过程是搭建hadoop环境.
-
详解Python如何利用Pandas与NumPy进行数据清洗
目录 准备工作 DataFrame 列的删除 DataFrame 索引更改 DataFrame 数据字段整理 str 方法与 NumPy 结合清理列 apply 函数清理整个数据集 DataFrame 跳过行 DataFrame 重命名列 许多数据科学家认为获取和清理数据的初始步骤占工作的 80%,花费大量时间来清理数据集并将它们归结为可以使用的形式. 因此如果你是刚刚踏入这个领域或计划踏入这个领域,重要的是能够处理杂乱的数据,无论数据是否包含缺失值.不一致的格式.格式错误的记录还是无意义的异常
-
详解Python中四种关系图数据可视化的效果对比
python关系图的可视化主要就是用来分析一堆数据中,每一条数据的节点之间的连接关系从而更好的分析出人物或其他场景中存在的关联关系. 这里使用的是networkx的python非标准库来测试效果展示,通过模拟出一组DataFrame数据实现四种关系图可视化. 其余还包含了pandas的数据分析模块以及matplotlib的画图模块. 若是没有安装这三个相关的非标准库使用pip的方式安装一下即可. pip install pandas -i https://pypi.tuna.tsinghua.e
-
详解python中groupby函数通俗易懂
一.groupby 能做什么? python中groupby函数主要的作用是进行数据的分组以及分组后地组内运算! 对于数据的分组和分组运算主要是指groupby函数的应用,具体函数的规则如下: df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式--函数名称) 举例如下: print(df["评分"].groupby([df["地区"],df["类
-
详解python方法之绑定方法与非绑定方法
写在之前 在 Python 的类里面除了属性之外,还有方法,当然也有文档和注释这类东西,但是这个只是人来看,计算机则不关心.我们之前说过,我们一般用实例调用方法,既然我们说了是一般,那么就说明还有其他调用方法的方式,今天我们就来说一下「绑定方法和非绑定方法」. 绑定方法和非绑定方法 在 Python 中除了特殊方法以外,类中的其他普通方法也是经常用到的,所以对于普通的方法也要进行研究,下面我们来看一个例子: >>> class Sample: ... def f(self): ... p
-
详解python tcp编程
网络连接与通信是我们学习任何编程语言都绕不过的知识点. Python 也不例外,本文就介绍因特网的核心协议 TCP ,以及如何用 Python 实现 TCP 的连接与通信. TCP 协议 TCP协议(Transmission Control Protocol, 传输控制协议)是一种面向连接的传输层通信协议,它能提供高可靠性通信,像 HTTP/HTTPS 等网络服务都采用 TCP 协议通讯.那么网络通讯方面都会涉及到 socket 编程,当然也包括 TCP 协议. Network Socket 我
-
详解python 支持向量机(SVM)算法
相比于逻辑回归,在很多情况下,SVM算法能够对数据计算从而产生更好的精度.而传统的SVM只能适用于二分类操作,不过却可以通过核技巧(核函数),使得SVM可以应用于多分类的任务中. 本篇文章只是介绍SVM的原理以及核技巧究竟是怎么一回事,最后会介绍sklearn svm各个参数作用和一个demo实战的内容,尽量通俗易懂.至于公式推导方面,网上关于这方面的文章太多了,这里就不多进行展开了~ 1.SVM简介 支持向量机,能在N维平面中,找到最明显得对数据进行分类的一个超平面!看下面这幅图: 如上图中,