浅谈Git分支管理策略
如果你严肃对待编程,就必定会使用"版本管理系统"(Version Control System)。
眼下最流行的"版本管理系统",非Git莫属。

相比同类软件,Git有很多优点。其中很显著的一点,就是版本的分支(branch)和合并(merge)十分方便。有些传统的版本管理软件,分支操作实际上会生成一份现有代码的物理拷贝,而Git只生成一个指向当前版本(又称"快照")的指针,因此非常快捷易用。
但是,太方便了也会产生副作用。如果你不加注意,很可能会留下一个枝节蔓生、四处开放的版本库,到处都是分支,完全看不出主干发展的脉络。
Vincent Driessen提出了一个分支管理的策略,我觉得非常值得借鉴。它可以使得版本库的演进保持简洁,主干清晰,各个分支各司其职、井井有条。理论上,这些策略对所有的版本管理系统都适用,Git只是用来举例而已。如果你不熟悉Git,跳过举例部分就可以了。
一、主分支Master
首先,代码库应该有一个、且仅有一个主分支。所有提供给用户使用的正式版本,都在这个主分支上发布。
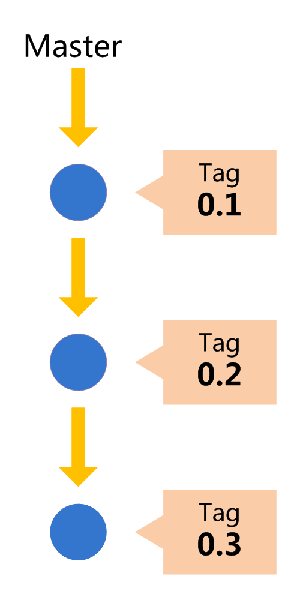
Git主分支的名字,默认叫做Master。它是自动建立的,版本库初始化以后,默认就是在主分支在进行开发。
二、开发分支Develop
主分支只用来分布重大版本,日常开发应该在另一条分支上完成。我们把开发用的分支,叫做Develop。
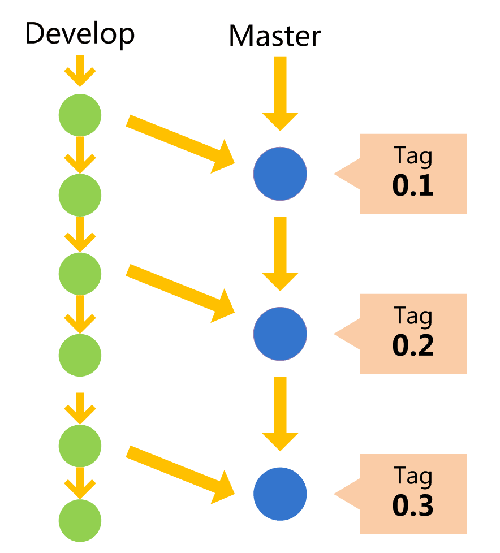
这个分支可以用来生成代码的最新隔夜版本(nightly)。如果想正式对外发布,就在Master分支上,对Develop分支进行"合并"(merge)。
Git创建Develop分支的命令:
git checkout -b develop master
将Develop分支发布到Master分支的命令:
# 切换到Master分支 git checkout master # 对Develop分支进行合并 git merge --no-ff develop
这里稍微解释一下,上一条命令的--no-ff参数是什么意思。默认情况下,Git执行"快进式合并"(fast-farward merge),会直接将Master分支指向Develop分支。
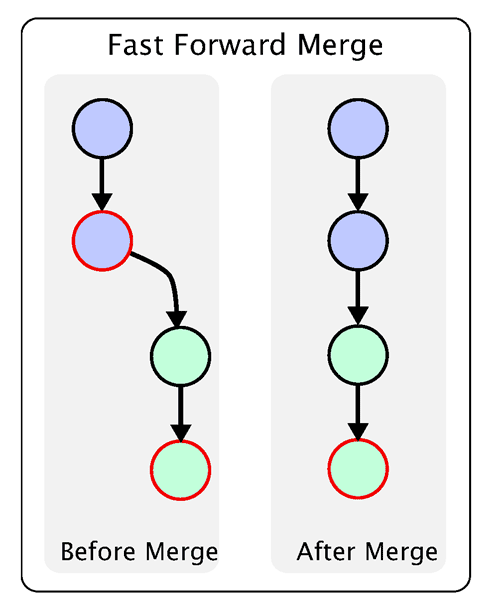
使用--no-ff参数后,会执行正常合并,在Master分支上生成一个新节点。为了保证版本演进的清晰,我们希望采用这种做法。关于合并的更多解释,请参考Benjamin Sandofsky的《Understanding the Git Workflow》。

三、临时性分支
前面讲到版本库的两条主要分支:Master和Develop。前者用于正式发布,后者用于日常开发。其实,常设分支只需要这两条就够了,不需要其他了。
但是,除了常设分支以外,还有一些临时性分支,用于应对一些特定目的的版本开发。临时性分支主要有三种:
* 功能(feature)分支
* 预发布(release)分支
* 修补bug(fixbug)分支
这三种分支都属于临时性需要,使用完以后,应该删除,使得代码库的常设分支始终只有Master和Develop。
四、 功能分支
接下来,一个个来看这三种"临时性分支"。
第一种是功能分支,它是为了开发某种特定功能,从Develop分支上面分出来的。开发完成后,要再并入Develop。
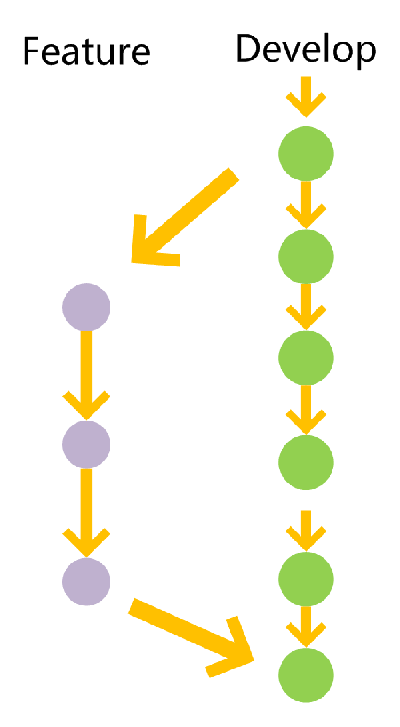
功能分支的名字,可以采用feature-*的形式命名。
创建一个功能分支:
git checkout -b feature-x develop
开发完成后,将功能分支合并到develop分支:
git checkout develop git merge --no-ff feature-x
删除feature分支:
git branch -d feature-x
五、预发布分支
第二种是预发布分支,它是指发布正式版本之前(即合并到Master分支之前),我们可能需要有一个预发布的版本进行测试。
预发布分支是从Develop分支上面分出来的,预发布结束以后,必须合并进Develop和Master分支。它的命名,可以采用release-*的形式。
创建一个预发布分支:
git checkout -b release-1.2 develop
确认没有问题后,合并到master分支:
git checkout master git merge --no-ff release-1.2 # 对合并生成的新节点,做一个标签 git tag -a 1.2
再合并到develop分支:
git checkout develop git merge --no-ff release-1.2
最后,删除预发布分支:
git branch -d release-1.2
六、修补bug分支
最后一种是修补bug分支。软件正式发布以后,难免会出现bug。这时就需要创建一个分支,进行bug修补。
修补bug分支是从Master分支上面分出来的。修补结束以后,再合并进Master和Develop分支。它的命名,可以采用fixbug-*的形式。
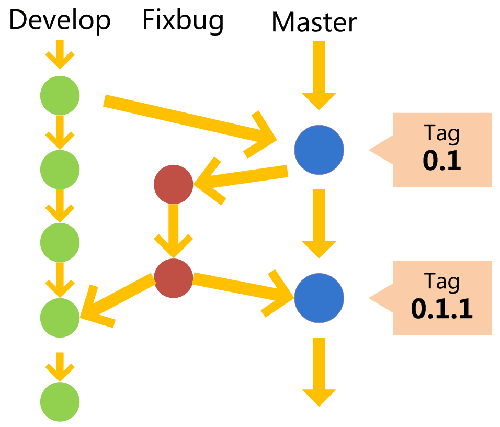
创建一个修补bug分支:
git checkout -b fixbug-0.1 master
修补结束后,合并到master分支:
git checkout master git merge --no-ff fixbug-0.1 git tag -a 0.1.1
再合并到develop分支:
git checkout develop git merge --no-ff fixbug-0.1
最后,删除"修补bug分支":
git branch -d fixbug-0.1
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

在Ubuntu Linux上安装和使用Git和GitHub
Git的简介 Git是2005年Linus Torvalds 为了帮助管理 Linux(R) 内核开发而开发的一个开放源码的版本控制软件,正如所提供的文档中说的一样: Git 是一个快速.可扩展的分布式版本控制系统,它具有极为丰富的命令集,对内部系统提供了高级操作和完全访问. Github是一个存放着世界上最棒的一些软件项目的宝藏,这些软件项目由全世界的开发者无私贡献.这个看似简单,实则非常强大的平台因为大大帮助了那些对开发大规模软件感兴趣的开发者而被开源社区所称道. 这篇向导是对于安装和使用G
-
Linux 搭建Git服务器的方法
安装Git yum install -y git git --version 创建 Git 用户 sudo adduser git // 设置密码 passwd git 导入公钥 find / -name authorized_keys vim /root/.ssh/authorized_keys 创建Git仓库 # 切到指定目录下 sudo git init --bare server.git # owner指定为git sudo chown -R git:git server.git 禁用g
-
Git使用基础篇(一些常用命令和原理)
Git是一个分布式的版本控制工具,本篇文章从介绍Git开始,重点在于介绍Git的基本命令和使用技巧,让你尝试使用Git的同时,体验到原来一个版本控制工具可以对开发产生如此之多的影响,文章分为两部分,第一部分介绍Git的一些常用命令,其中穿插介绍Git的基本概念和原理,第二篇重点介绍 Git的使用技巧,最后会在Git Hub上创建一个开源项目开启你的Git实战之旅 1.Git是什么 Git在Wikipedia上的定义:它是一个免费的.分布式的版本控制工具,或是一个强调了速度快的源代码管理工具.Gi
-
Git原理和常用操作
由于gitlab的免费私有仓库的优势,所以在公司使用gitlab会多一些,对于gitlab来说,注册需要翻墙,而登录不需要. 关于git是做什么的,这里就不多说了.相信大家知道,这里就带大家,一小时掌握git原理,学会git操作. Git 工作流程 在gitlab上一般每个人或每个项目或者每个bug都会有自己独立的分支.分支不影响主分支master. 一般工作流程如下: 克隆 Git 资源作为工作目录. 在克隆的资源上添加或修改文件. 如果其他人修改了,你可以更新资源. 在提交前查看修改. 提交
-
分享Git常用7大技巧和命令
Git 是一个非常强大的工具,它包含丰富的工具用以维护项目.本文介绍了一些 Git 日常使用过程中的实用技巧和命令,希望这些内容能够对大家有所帮助. 一.Git diff比对命令 通常情况下,我们会在自己的独立分支中完成需求开发,此时就会有需求将自己的分支和其他分支进行对比.这个功能可以通过 git diff branch1 branch 命令来实现. 如果希望对比暂存区和当前的 HEAD,那么使用 git diff --cached 命令会非常方便.普通的git diff命令默认对比的是没有加
-
总结PHP代码规范、流程规范、git规范
代码规范.git规范.teambition规范.yii规范 1. 命名规范 (1).变量命名规范 1.变量使用驼峰命名法 禁止使用拼音或者拼音加数字 2.变量也应具有描述性,杜绝一切拼音.或拼音英文混杂的命名方式 3.变量包数字.字母和下划线字符,不允许使用其他字符,变量命名最好使用项目 中有据可查的英文缩写方式, 尽可以要使用一目了然容易理解的形式: 4.变量以字母开头,如果变量包多个单词,首字母小写,当包多个单词时,后面 的每个单词的首字母大写.例如 :$itSports 5.变量使用有效命
-
Git如何删除历史记录中的大文件详解
前言 Git 作为一个分布式的版本管理工具,代码仓库中是会保存所有历史记录的.虽然,Git 的 .gitignore 文件里可以定义一些忽略文件的规则,但是,在我们提交代码的过程中,总会不小心误提一些没用的文件,如果文件中存在大文件,就会导致:就算我们把它删了重新提交,.git 文件夹依然会占用较大的空间. 如何解决这个问题呢?其实,Git 已经为我们提供了解决方案,就是被称为核弹级的命令 filter-branch.这个命令可以用来修改历史提交记录,把不需要的文件永久地从历史记录中删除. 方法
-
详解git仓库迁移的两种解决方案
Git仓库迁移而不丢失log的方法 要求能保留原先的commit记录,应该如何迁移呢? 同时,本地已经clone了原仓库,要配置成新的仓库地址,该如何修改呢? 注意:如果使用了代码审核工具Gerrit,那么在进行操作之前需要将Gerrit关掉,等成功恢复后再将Gerrit开户即可 1.使用git push --mirror 先了解一些git的基本参数介绍 git clone --bare GIT-CLONE(1) Git Manual GIT-CLONE(1) NAME git-clone -
-
浅谈Git分支管理策略
如果你严肃对待编程,就必定会使用"版本管理系统"(Version Control System). 眼下最流行的"版本管理系统",非Git莫属. 相比同类软件,Git有很多优点.其中很显著的一点,就是版本的分支(branch)和合并(merge)十分方便.有些传统的版本管理软件,分支操作实际上会生成一份现有代码的物理拷贝,而Git只生成一个指向当前版本(又称"快照")的指针,因此非常快捷易用. 但是,太方便了也会产生副作用.如果你不加注意,很可能
-
Git分支管理策略
目录 一.创建测试项目 1.新建GitHub仓库 2.将本地仓库项目上传到GitHub 2.1.初始化本地仓库 2.2.把文件添加到暂存区 2.3.提交到本地仓库 2.4.关联远程GitHub仓库 2.5.将本地仓库推送到远程仓库 2.6.查看状态 二.管理分支 1.创建本地仓库新分支 2.查看新创建的分支是否成功 3.切换分支 4.查看当前分支 5.将创建的分支推送到远程仓库 6.修改文件 7.将修改后的文件提交到暂存区 8.提交到本地仓库 9.推送到远程仓库 10.查看文件状态 11.合并到
-
浅谈用SpringBoot实现策略模式
目录 问题的提出 策略模式代码的实现 进一步的思考 心得体会 问题的提出 阅读别人代码的时候最讨厌遇到的就是大段大段的if-else分支语句,一般来说读到下面的时候就忘了上面在判断什么了.很多资料上都会讲到使用策略模式来改进这种代码逻辑. 策略模式的类图如下: 只需要按照这个图写代码就可以了. 策略模式代码的实现 借助Spring框架我们能够轻松的实现策略模式. 举一个简单的例子,我们去咖啡店买咖啡的时候,会根据自己的喜好和胃容量选择大小杯.那么我们就要实现一个CoffeeStategy: pa
-
浅谈java内存管理与内存溢出异常
说到内存管理,笔者这里想先比较一下java与C.C++之间的区别: 在C.C++中,内存管理是由程序员负责的,也就是说程序员既要完成繁重的代码编写工作又要时常考虑到系统内存的维护 在java中,程序员无需考虑内存的控制和维护,而是交由JVM自动管理,这样就不容易出现内存泄漏和溢出的问题.然而,一旦出现内存泄漏和溢出方面的问题,如果不了解JVM的内存管理机制就很难找到错误所在. 1.JVM运行时数据区 JVM在运行java程序的时候会将它所管理的内存划分为若干个不同的区域,这些区域不仅有自己的用途
-
浅谈vue权限管理实现及流程
一.整体思路 后端返回用户权限,前端根据用户权限处理得到左侧菜单:所有路由在前端定义好,根据后端返回的用户权限筛选出需要挂载的路由,然后使用 addRoutes 动态挂载路由. 二.实现要点 (1)路由定义,分为初始路由和动态路由,一般来说初始路由只有 login,其他路由都挂载在 home 路由之下需要动态挂载. (2)用户登录,登录成功之后得到 token,保存在 sessionStorage,跳转到 home,此时会进入路由拦截根据 token 获取用户权限列表. (3)全局路由拦截,根据
-
浅谈Redis缓存更新策略
内存淘汰 超时剔除 主动更新 说明 不用自己维护,利用Redis的内存淘汰机制,当内存不足时自动淘汰部分数据.下次查询时更新缓存 给缓存数据添加TTL时间,到期后自动删除缓存,下次查询时更新缓存 编写业务逻辑,在修改数据的同时,更新缓存 一致性 差 一般 好 维护成本 无 低 高 业务场景需求: 在基本不会更新数据的情况下可以使用内存淘汰机制 在频繁更新数据的情况下可以使用主动更新,并以超时剔除作为兜底方案. 主动更新的三种方法 Cache Aside Pattern:由缓存的调用者,在更新
-
git分支管理_动力节点Java学院整理
分支就是科幻电影里面的平行宇宙,当你正在电脑前努力学习Git的时候,另一个你正在另一个平行宇宙里努力学习SVN. 如果两个平行宇宙互不干扰,那对现在的你也没啥影响.不过,在某个时间点,两个平行宇宙合并了,结果,你既学会了Git又学会了SVN! 分支在实际中有什么用呢?假设你准备开发一个新功能,但是需要两周才能完成,第一周你写了50%的代码,如果立刻提交,由于代码还没写完,不完整的代码库会导致别人不能干活了.如果等代码全部写完再一次提交,又存在丢失每天进度的巨大风险. 现在有了分支,就不用怕了.你
-
浅谈Tomcat Session管理分析
前言 在上文Nginx+Tomcat关于Session的管理中简单介绍了如何使用redis来集中管理session,本文首先将介绍默认的管理器是如何管理Session的生命周期的,然后在此基础上对Redis集中式管理Session进行分析. Tomcat Manager介绍 上文中在Tomcat的context.xml中配置了Session管理器RedisSessionManager,实现了通过redis来存储session的功能:Tomcat本身提供了多种Session管理器,如下类图: 1.
-
浅谈Angular路由复用策略
一.引言 路由在执行过程中对组件无状态操作,即路由离退时组件状态也一并被删除:当然在绝大多数场景下这是合理的. 但有时一些特殊需求会让人半死亡状态,当然这一切都是为了用户体验:一种非常常见场景,在移动端中用户通过关键词搜索商品,而死不死的这样的列表通常都会是自动下一页动作,此时用户好不容易滚动到第二页并找到想要看的商品时,路由至商品详情页,然后一个后退--用户懵逼了. Angular路由与组件一开始就透过 RouterModule.forRoot 形成一种关系,当路由命中时利用Component
-
浅谈spring-boot-rabbitmq动态管理的方法
使用spring boot + rabbitmq的时候,在开发过程中,可能会想要临时停用/启用监听,或修改监听消费者数量.如果每次修改都重启比较浪费时间,所以研究了一下不停机就启用停用监听或修改一些配置 一. 关于rabbitmq监听的配置 配置属性类:RabbitProperties,包含rabbitmq的认证.监听.发送者以及其他的一些配置 自动配置类:RabbitAutoConfiguration,主要配置rabbitmq的连接工厂和发送者等,不包含监听的配置 rabbitmq监听的配置是