从源代码分析Android Universal ImageLoader的缓存处理机制
通过本文带大家一起看过UIL这个国内外大牛都追捧的图片缓存类库的缓存处理机制。看了UIL中的缓存实现,才发现其实这个东西不难,没有太多的进程调度,没有各种内存读取控制机制、没有各种异常处理。反正UIL中不单代码写的简单,连处理都简单。但是这个类库这么好用,又有这么多人用,那么非常有必要看看他是怎么实现的。先了解UIL中缓存流程的原理图。
原理示意图
主体有三个,分别是UI,缓存模块和数据源(网络)。它们之间的关系如下:
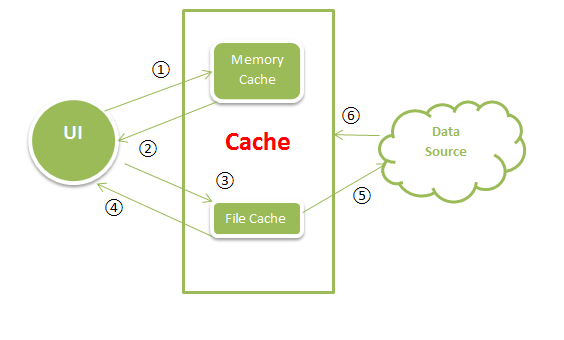
① UI:请求数据,使用唯一的Key值索引Memory Cache中的Bitmap。
② 内存缓存:缓存搜索,如果能找到Key值对应的Bitmap,则返回数据。否则执行第三步。
③ 硬盘存储:使用唯一Key值对应的文件名,检索SDCard上的文件。
④ 如果有对应文件,使用BitmapFactory.decode*方法,解码Bitmap并返回数据,同时将数据写入缓存。如果没有对应文件,执行第五步。
⑤ 下载图片:启动异步线程,从数据源下载数据(Web)。
⑥ 若下载成功,将数据同时写入硬盘和缓存,并将Bitmap显示在UI中。
接下来,我们回顾一下UIL中缓存的配置(具体的见《UNIVERSAL IMAGE LOADER.PART 2》)。重点关注注释部分,我们可以根据自己需要配置内存、磁盘缓存的实现。
File cacheDir = StorageUtils.getCacheDirectory(context, "UniversalImageLoader/Cache"); ImageLoaderConfiguration config = new ImageLoaderConfiguration .Builder(getApplicationContext()) .maxImageWidthForMemoryCache() .maxImageHeightForMemoryCache() .httpConnectTimeout() .httpReadTimeout() .threadPoolSize() .threadPriority(Thread.MIN_PRIORITY + ) .denyCacheImageMultipleSizesInMemory() .memoryCache(new UsingFreqLimitedCache()) // 你可以传入自己的内存缓存 .discCache(new UnlimitedDiscCache(cacheDir)) // 你可以传入自己的磁盘缓存 .defaultDisplayImageOptions(DisplayImageOptions.createSimple()) .build();
UIL中的内存缓存策略
1. 只使用的是强引用缓存
•LruMemoryCache(这个类就是这个开源框架默认的内存缓存类,缓存的是bitmap的强引用,下面我会从源码上面分析这个类)
2.使用强引用和弱引用相结合的缓存有
UsingFreqLimitedMemoryCache(如果缓存的图片总量超过限定值,先删除使用频率最小的bitmap)
•LRULimitedMemoryCache(这个也是使用的lru算法,和LruMemoryCache不同的是,他缓存的是bitmap的弱引用)
•FIFOLimitedMemoryCache(先进先出的缓存策略,当超过设定值,先删除最先加入缓存的bitmap)
•LargestLimitedMemoryCache(当超过缓存限定值,先删除最大的bitmap对象)
•LimitedAgeMemoryCache(当 bitmap加入缓存中的时间超过我们设定的值,将其删除)
3.只使用弱引用缓存
WeakMemoryCache(这个类缓存bitmap的总大小没有限制,唯一不足的地方就是不稳定,缓存的图片容易被回收掉)
我们直接选择UIL中的默认配置缓存策略进行分析。
ImageLoaderConfiguration config = ImageLoaderConfiguration.createDefault(context);
ImageLoaderConfiguration.createDefault(…)这个方法最后是调用Builder.build()方法创建默认的配置参数的。默认的内存缓存实现是LruMemoryCache,磁盘缓存是UnlimitedDiscCache。
LruMemoryCache解析
LruMemoryCache:一种使用强引用来保存有数量限制的Bitmap的cache(在空间有限的情况,保留最近使用过的Bitmap)。每次Bitmap被访问时,它就被移动到一个队列的头部。当Bitmap被添加到一个空间已满的cache时,在队列末尾的Bitmap会被挤出去并变成适合被GC回收的状态。
注意:这个cache只使用强引用来保存Bitmap。
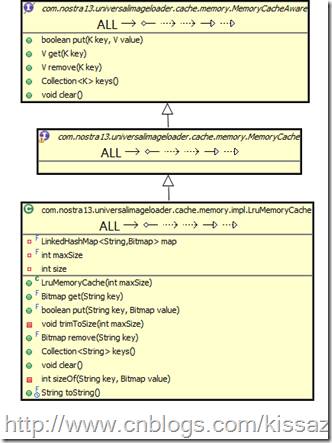
LruMemoryCache实现MemoryCache,而MemoryCache继承自MemoryCacheAware。
public interface MemoryCache extends MemoryCacheAware<String, Bitmap>
下面给出继承关系图
LruMemoryCache.get(…)
我相信接下去你看到这段代码的时候会跟我一样惊讶于代码的简单,代码中除了异常判断,就是利用synchronized进行同步控制。
/**
* Returns the Bitmap for {@code key} if it exists in the cache. If a Bitmap was returned, it is moved to the head
* of the queue. This returns null if a Bitmap is not cached.
*/
@Override
public final Bitmap get(String key) {
if (key == null) {
throw new NullPointerException("key == null");
}
synchronized (this) {
return map.get(key);
}
}
我们会好奇,这不是就简简单单将Bitmap从map中取出来吗?但LruMemoryCache声称保留在空间有限的情况下保留最近使用过的Bitmap。不急,让我们细细观察一下map。他是一个LinkedHashMap<String, Bitmap>型的对象。
LinkedHashMap中的get()方法不仅返回所匹配的值,并且在返回前还会将所匹配的key对应的entry调整在列表中的顺序(LinkedHashMap使用双链表来保存数据),让它处于列表的最后。当然,这种情况必须是在LinkedHashMap中accessOrder==true的情况下才生效的,反之就是get()方法不会改变被匹配的key对应的entry在列表中的位置。
@Override public V get(Object key) {
/*
* This method is overridden to eliminate the need for a polymorphic
* invocation in superclass at the expense of code duplication.
*/
if (key == null) {
HashMapEntry<K, V> e = entryForNullKey;
if (e == null)
return null;
if (accessOrder)
makeTail((LinkedEntry<K, V>) e);
return e.value;
}
// Replace with Collections.secondaryHash when the VM is fast enough (http://b/).
int hash = secondaryHash(key);
HashMapEntry<K, V>[] tab = table;
for (HashMapEntry<K, V> e = tab[hash & (tab.length - )];
e != null; e = e.next) {
K eKey = e.key;
if (eKey == key || (e.hash == hash && key.equals(eKey))) {
if (accessOrder)
makeTail((LinkedEntry<K, V>) e);
return e.value;
}
}
return null;
}
代码第11行的makeTail()就是调整entry在列表中的位置,其实就是双向链表的调整。它判断accessOrder。到现在我们就清楚LruMemoryCache使用LinkedHashMap来缓存数据,在LinkedHashMap.get()方法执行后,LinkedHashMap中entry的顺序会得到调整。那么我们怎么保证最近使用的项不会被剔除呢?接下去,让我们看看LruMemoryCache.put(...)。
LruMemoryCache.put(...)
注意到代码第8行中的size+= sizeOf(key, value),这个size是什么呢?我们注意到在第19行有一个trimToSize(maxSize),trimToSize(...)这个函数就是用来限定LruMemoryCache的大小不要超过用户限定的大小,cache的大小由用户在LruMemoryCache刚开始初始化的时候限定。
@Override
public final boolean put(String key, Bitmap value) {
if (key == null || value == null) {
throw new NullPointerException("key == null || value == null");
}
synchronized (this) {
size += sizeOf(key, value);
//map.put()的返回值如果不为空,说明存在跟key对应的entry,put操作只是更新原有key对应的entry
Bitmap previous = map.put(key, value);
if (previous != null) {
size -= sizeOf(key, previous);
}
}
trimToSize(maxSize);
return true;
}
其实不难想到,当Bitmap缓存的大小超过原来设定的maxSize时应该是在trimToSize(...)这个函数中做到的。这个函数做的事情也简单,遍历map,将多余的项(代码中对应toEvict)剔除掉,直到当前cache的大小等于或小于限定的大小。
private void trimToSize(int maxSize) {
while (true) {
String key;
Bitmap value;
synchronized (this) {
if (size < || (map.isEmpty() && size != )) {
throw new IllegalStateException(getClass().getName() + ".sizeOf() is reporting inconsistent results!");
}
if (size <= maxSize || map.isEmpty()) {
break;
}
Map.Entry<String, Bitmap> toEvict = map.entrySet().iterator().next();
if (toEvict == null) {
break;
}
key = toEvict.getKey();
value = toEvict.getValue();
map.remove(key);
size -= sizeOf(key, value);
}
}
}
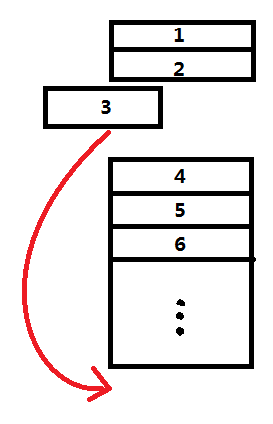
这时候我们会有一个以为,为什么遍历一下就可以将使用最少的bitmap缓存给剔除,不会误删到最近使用的bitmap缓存吗?首先,我们要清楚,LruMemoryCache定义的最近使用是指最近用get或put方式操作到的bitmap缓存。其次,之前我们直到LruMemoryCache的get操作其实是通过其内部字段LinkedHashMap.get(...)实现的,当LinkedHashMap的accessOrder==true时,每一次get或put操作都会将所操作项(图中第3项)移动到链表的尾部(见下图,链表头被认为是最少使用的,链表尾被认为是最常使用的。),每一次操作到的项我们都认为它是最近使用过的,当内存不够的时候被剔除的优先级最低。需要注意的是一开始的LinkedHashMap链表是按插入的顺序构成的,也就是第一个插入的项就在链表头,最后一个插入的就在链表尾。假设只要剔除图中的1,2项就能让LruMemoryCache小于原先限定的大小,那么我们只要从链表头遍历下去(从1→最后一项)那么就可以剔除使用最少的项了。
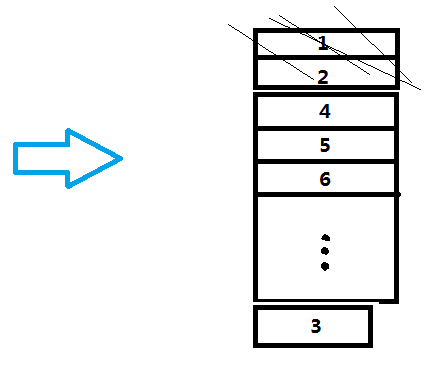
至此,我们就知道了LruMemoryCache缓存的整个原理,包括他怎么put、get、剔除一个元素的的策略。接下去,我们要开始分析默认的磁盘缓存策略了。
UIL中的磁盘缓存策略
像新浪微博、花瓣这种应用需要加载很多图片,本来图片的加载就慢了,如果下次打开的时候还需要再一次下载上次已经有过的图片,相信用户的流量会让他们的叫骂声很响亮。对于图片很多的应用,一个好的磁盘缓存直接决定了应用在用户手机的留存时间。我们自己实现磁盘缓存,要考虑的太多,幸好UIL提供了几种常见的磁盘缓存策略,当然如果你觉得都不符合你的要求,你也可以自己去扩展
•FileCountLimitedDiscCache(可以设定缓存图片的个数,当超过设定值,删除掉最先加入到硬盘的文件)
•LimitedAgeDiscCache(设定文件存活的最长时间,当超过这个值,就删除该文件)
•TotalSizeLimitedDiscCache(设定缓存bitmap的最大值,当超过这个值,删除最先加入到硬盘的文件)
•UnlimitedDiscCache(这个缓存类没有任何的限制)
在UIL中有着比较完整的存储策略,根据预先指定的空间大小,使用频率(生命周期),文件个数的约束条件,都有着对应的实现策略。最基础的接口DiscCacheAware和抽象类BaseDiscCache
UnlimitedDiscCache解析
UnlimitedDiscCache实现disk cache接口,是ImageLoaderConfiguration中默认的磁盘缓存处理。用它的时候,磁盘缓存的大小是不受限的。
接下来我们来看看实现UnlimitedDiscCache的源代码,通过源代码我们发现他其实就是继承了BaseDiscCache,这个类内部没有实现自己独特的方法,也没有重写什么,那么我们就直接看BaseDiscCache这个类。在分析这个类之前,我们先想想自己实现一个磁盘缓存需要做多少麻烦的事情:
1、图片的命名会不会重。你没有办法知道用户下载的图片原始的文件名是怎么样的,因此很可能因为文件重名将有用的图片给覆盖掉了。
2、当应用卡顿或网络延迟的时候,同一张图片反复被下载。
3、处理图片写入磁盘可能遇到的延迟和同步问题。
BaseDiscCache构造函数
首先,我们看一下BaseDiscCache的构造函数:
cacheDir:文件缓存目录
reserveCacheDir:备用的文件缓存目录,可以为null。它只有当cacheDir不能用的时候才有用。
fileNameGenerator:文件名生成器。为缓存的文件生成文件名。
public BaseDiscCache(File cacheDir, File reserveCacheDir, FileNameGenerator fileNameGenerator) {
if (cacheDir == null) {
throw new IllegalArgumentException("cacheDir" + ERROR_ARG_NULL);
}
if (fileNameGenerator == null) {
throw new IllegalArgumentException("fileNameGenerator" + ERROR_ARG_NULL);
}
this.cacheDir = cacheDir;
this.reserveCacheDir = reserveCacheDir;
this.fileNameGenerator = fileNameGenerator;
}
我们可以看到一个fileNameGenerator,接下来我们来了解UIL具体是怎么生成不重复的文件名的。UIL中有3种文件命名策略,这里我们只对默认的文件名策略进行分析。默认的文件命名策略在DefaultConfigurationFactory.createFileNameGenerator()。它是一个HashCodeFileNameGenerator。真的是你意想不到的简单,就是运用String.hashCode()进行文件名的生成。
public class HashCodeFileNameGenerator implements FileNameGenerator {
@Override
public String generate(String imageUri) {
return String.valueOf(imageUri.hashCode());
}
}
BaseDiscCache.save()
分析完了命名策略,再看一下BaseDiscCache.save(...)方法。注意到第2行有一个getFile()函数,它主要用于生成一个指向缓存目录中的文件,在这个函数里面调用了刚刚介绍过的fileNameGenerator来生成文件名。注意第3行的tmpFile,它是用来写入bitmap的临时文件(见第8行),然后就把这个文件给删除了。大家可能会困惑,为什么在save()函数里面没有判断要写入的bitmap文件是否存在的判断,我们不由得要看看UIL中是否有对它进行判断。还记得我们在《从代码分析Android-Universal-Image-Loader的图片加载、显示流程》介绍的,UIL加载图片的一般流程是先判断内存中是否有对应的Bitmap,再判断磁盘(disk)中是否有,如果没有就从网络中加载。最后根据原先在UIL中的配置判断是否需要缓存Bitmap到内存或磁盘中。也就是说,当需要调用BaseDiscCache.save(...)之前,其实已经判断过这个文件不在磁盘中。
public boolean save(String imageUri, InputStream imageStream, IoUtils.CopyListener listener) throws IOException {
File imageFile = getFile(imageUri);
File tmpFile = new File(imageFile.getAbsolutePath() + TEMP_IMAGE_POSTFIX);
boolean loaded = false;
try {
OutputStream os = new BufferedOutputStream(new FileOutputStream(tmpFile), bufferSize);
try {
loaded = IoUtils.copyStream(imageStream, os, listener, bufferSize);
} finally {
IoUtils.closeSilently(os);
}
} finally {
IoUtils.closeSilently(imageStream);
if (loaded && !tmpFile.renameTo(imageFile)) {
loaded = false;
}
if (!loaded) {
tmpFile.delete();
}
}
return loaded;
}
BaseDiscCache.get()
BaseDiscCache.get()方法内部调用了BaseDiscCache.getFile(...)方法,让我们来分析一下这个在之前碰过的函数。 第2行就是利用fileNameGenerator生成一个唯一的文件名。第3~8行是指定缓存目录,这时候你就可以清楚地看到cacheDir和reserveCacheDir之间的关系了,当cacheDir不可用的时候,就是用reserveCachedir作为缓存目录了。
最后返回一个指向文件的对象,但是要注意当File类型的对象指向的文件不存在时,file会为null,而不是报错。
protected File getFile(String imageUri) {
String fileName = fileNameGenerator.generate(imageUri);
File dir = cacheDir;
if (!cacheDir.exists() && !cacheDir.mkdirs()) {
if (reserveCacheDir != null && (reserveCacheDir.exists() || reserveCacheDir.mkdirs())) {
dir = reserveCacheDir;
}
}
return new File(dir, fileName);
}
总结
现在,我们已经分析了UIL的缓存机制。其实从UIL的缓存机制的实现并不是很复杂,虽然有各种缓存机制,但是简单地说:内存缓存其实就是利用Map接口的对象在内存中进行缓存,可能有不同的存储机制。磁盘缓存其实就是将文件写入磁盘。
相关推荐
-
Android Imageloader的配置的实现代码
Android Imageloader的配置的实现代码 ImageLoader 优点 (1) 支持下载进度监听 (2) 可以在 View 滚动中暂停图片加载 通过 PauseOnScrollListener 接口可以在 View 滚动中暂停图片加载. (3) 默认实现多种内存缓存算法 这几个图片缓存都可以配置缓存算法,不过 ImageLoader 默认实现了较多缓存算法,如 Size 最大先删除.使用最少先删除.最近最少使用.先进先删除.时间最长先删除等. (4) 支持本地缓存文件名规则定义
-
Android ListView实现ImageLoader图片加载的方法
本文实例讲述了Android ListView实现ImageLoader图片加载的方法.分享给大家供大家参考,具体如下: 最近一直忙着做项目,今天也是忙里偷闲,想写篇博客来巩固下之前在应用中所用的知识.之前我们可能会也会肯定遇到了图片的异步加载问题,然而我们也可能会遇到图片二次或多次加载,这是ListView的特性造成的,具体原因不在这里讨论,又或者是OOM等问题.今天要讲的是一个开源框架Imageloader,个人觉得非常的好用. 该框架在github的地址.https://github.co
-
Android Universal ImageLoader 缓存图片
项目介绍: Android上最让人头疼的莫过于从网络获取图片.显示.回收,任何一个环节有问题都可能直接OOM,这个项目或许能帮到你.Universal Image Loader for Android的目的是为了实现异步的网络图片加载.缓存及显示,支持多线程异步加载.它最初来源于Fedor Vlasov的项目,且自此之后,经过大规模的重构和改进. 特性列举: 多线程下载图片,图片可以来源于网络,文件系统,项目文件夹assets中以及drawable中等 支持随意的配置ImageLoader,例如
-

Android开发之ImageLoader使用详解
先给大家展示效果图,看看是大家想要的效果吗,如果还满意,请参考以下代码: 前言 UniversalImageLoader是用于加载图片的一个开源项目,在其项目介绍中是这么写的, •支持多线程图片加载 •提供丰富的细节配置,比如线程池大小,HTPP请求项,内存和磁盘缓存,图片显示时的参数配置等等: •提供双缓存 •支持加载过程的监听: •提供图片的个性化显示配置接口: •Widget支持(这个,个人觉得没必要写进来,不过尊重原文) 其他类似的项目也有很多,但这个作为github上著名的开源项目被广
-
SimpleCommand框架ImageLoader API详解(三)
ImageLoader API 详细介绍,具体内容如下 在ImageLoader中有以下几个不同的构造器: /** * 注意: 次构造器不支持下载进度提示功能 * @param context * @param withCache 是否支持缓存 * false--不带缓存 * true--支持缓存功能,默认缓存路径在外置存储缓冲目录中的picasso-big-cache文件夹中 */ public ImageLoader(Context context, boolean withCache) {
-
Android ImageLoader第三方框架解析
本文实例为大家分享了Android ImageLoader框架的使用方法,供大家参考,具体内容如下 1.准备工作 1)导入universal-image-loader-1.9.5.jar到项目中 2)创建MyApplication继承Application,在oncreate()中初始化ImageLoader public class MyApplication extends Application { @Override public void onCreate() { super.onCr
-
Android开发之ImageLoader本地缓存
ImageLoader是一个图片缓存的开源库,提供了强大的图片缓存机制,很多开发者都在使用,今天给大家介绍Android开发之ImageLoader本地缓存,具体内容如下所示: 本地缓存在缓存文件时对文件名称的修改提供了两种方式,每一种方式对应了一个Java类 1) HashCodeFileNameGenerator ,该类负责获取文件名称的hashcode然后转换成字符串. 2) Md5FileNameGenerator ,该类把源文件的名称同过md5加密后保存. 两个类都继承了FileNam
-
从源代码分析Android Universal ImageLoader的缓存处理机制
通过本文带大家一起看过UIL这个国内外大牛都追捧的图片缓存类库的缓存处理机制.看了UIL中的缓存实现,才发现其实这个东西不难,没有太多的进程调度,没有各种内存读取控制机制.没有各种异常处理.反正UIL中不单代码写的简单,连处理都简单.但是这个类库这么好用,又有这么多人用,那么非常有必要看看他是怎么实现的.先了解UIL中缓存流程的原理图. 原理示意图 主体有三个,分别是UI,缓存模块和数据源(网络).它们之间的关系如下: ① UI:请求数据,使用唯一的Key值索引Memory Cache中的Bit
-
Android系统进程间通信Binder机制在应用程序框架层的Java接口源代码分析
在前面几篇文章中,我们详细介绍了Android系统进程间通信机制Binder的原理,并且深入分析了系统提供的Binder运行库和驱动程序的源代码.细心的读者会发现,这几篇文章分析的Binder接口都是基于C/C++语言来实现的,但是我们在编写应用程序都是基于Java语言的,那么,我们如何使用Java语言来使用系统的Binder机制来进行进程间通信呢?这就是本文要介绍的Android系统应用程序框架层的用Java语言来实现的Binder接口了. 熟悉Android系统的读者,应该能想到应用程序框架
-
Android系统进程间通信(IPC)机制Binder中的Client获得Server远程接口过程源代码分析
在上一篇文章中,我们分析了Android系统进程间通信机制Binder中的Server在启动过程使用Service Manager的addService接口把自己添加到Service Manager守护过程中接受管理.在这一篇文章中,我们将深入到Binder驱动程序源代码去分析Client是如何通过Service Manager的getService接口中来获得Server远程接口的.Client只有获得了Server的远程接口之后,才能进一步调用Server提供的服务. 这里,我们仍然是通过A
-
Android系统进程间通信(IPC)机制Binder中的Server启动过程源代码分析
在前面一篇文章Android系统进程间通信(IPC)机制Binder中的Server和Client获得Service Manager接口之路中,介绍了在Android系统中Binder进程间通信机制中的Server角色是如何获得Service Manager远程接口的,即defaultServiceManager函数的实现.Server获得了Service Manager远程接口之后,就要把自己的Service添加到Service Manager中去,然后把自己启动起来,等待Client的请求.
-
Android 图片的三级缓存机制实例分析
Android 图片的三级缓存机制实例分析 当我们获取图片的时候,如果不加以协调好图片的缓存,就会造成大流量,费流量应用,用户体验不好,影响后期发展.为此,我特地分享Android图片的三级缓存机制之从网络中获取图片,来优化应用,具体分三步进行: (1)从缓存中获取图片 (2)从本地的缓存目录中获取图片,并且获取到之后,放到缓存中 (3)从网络去下载图片,下载完成之后,保存到本地和放到缓存中 很好的协调这三层图片缓存就可以大幅度提升应用的性能和用户体验. 快速实现三级缓存的工具类ImageCac
-
分析Android Activity的启动过程
分析Android Activity的启动过程 对于Android Activity 的启动过程,我在Android源码中读了好久的源码,以下是我整理出来的Activity启动过程和大家分享下: Activity作为Android的四大组件之一,也是最基本的组件,负责与用户交互的所有功能.Activity的启动过程也并非一件神秘的事情,接下来就简单的从源码的角度分析一下Activity的启动过程. 根Activity一般就是指我们项目中的MainActivity,代表了一个android应用程序
-
从源码分析Android的Glide库的图片加载流程及特点
0.基础知识 Glide中有一部分单词,我不知道用什么中文可以确切的表达出含义,用英文单词可能在行文中更加合适,还有一些词在Glide中有特别的含义,我理解的可能也不深入,这里先记录一下. (1)View: 一般情况下,指Android中的View及其子类控件(包括自定义的),尤其指ImageView.这些控件可在上面绘制Drawable (2)Target: Glide中重要的概念,目标.它即可以指封装了一个View的Target(ViewTarget),也可以不包含View(SimpleTa
-
通过源代码分析Mybatis的功能流程详解
SQL解析 Mybatis在初始化的时候,会读取xml中的SQL,解析后会生成SqlSource对象,SqlSource对象分为两种. DynamicSqlSource,动态SQL,获取SQL(getBoundSQL方法中)的时候生成参数化SQL. RawSqlSource,原始SQL,创建对象时直接生成参数化SQL. 因为RawSqlSource不会重复去生成参数化SQL,调用的时候直接传入参数并执行,而DynamicSqlSource则是每次执行的时候参数化SQL,所以RawSqlSourc