Springboot2.x+ShardingSphere实现分库分表的示例代码
之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程。
概念解析
垂直分片
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
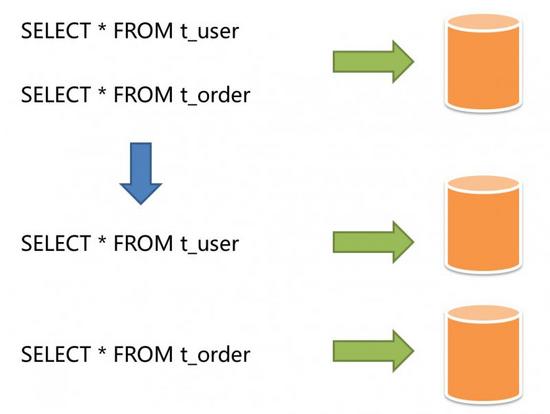
垂直分片往往需要对架构和设计进行调整。通常来讲,是来不及应对互联网业务需求快速变化的;而且,它也并无法真正的解决单点瓶颈。 垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入0库(或表),奇数主键的记录放入1库(或表),如下图所示。
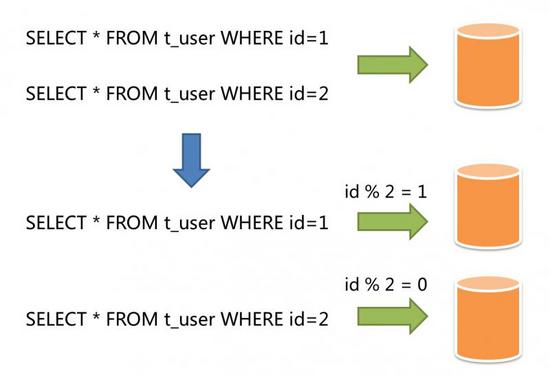
水平分片从理论上突破了单机数据量处理的瓶颈,并且扩展相对自由,是分库分表的标准解决方案。
开发准备
分库分表常用的组件就是shardingsphere,目前已经是apache顶级项目,这次我们使用springboot2.1.9 + shardingsphere4.0.0-RC2(均为最新版本)来完成分库分表的操作。
假设有一张订单表,我们需要将它分成2个库,每个库三张表,根据id字段取模确定最终数据的位置,数据库环境配置如下:
172.31.0.129
- blog
- t_order_0
- t_order_1
- t_order_2
172.31.0.131
- blog
- t_order_0
- t_order_1
- t_order_2
三张表的逻辑表为t_order,大家可以根据建表语句准备好其他所有数据表。
DROP TABLE IF EXISTS `t_order_0; CREATE TABLE `t_order_0` ( `id` bigint(20) NOT NULL, `name` varchar(255) DEFAULT NULL COMMENT '名称', `type` varchar(255) DEFAULT NULL COMMENT '类型', `gmt_create` timestamp NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '创建时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
注意,千万不能将主键的生成规则设置成自增长,需要按照一定规则来生成主键,这里使用shardingsphere中的SNOWFLAKE俗称雪花算法来生成主键
代码实现
修改pom.xml,引入相关组件
<properties>
<java.version>1.8</java.version>
<mybatis-plus.version>3.1.1</mybatis-plus.version>
<sharding-sphere.version>4.0.0-RC2</sharding-sphere.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>2.0.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>${mybatis-plus.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-namespace</artifactId>
<version>${sharding-sphere.version}</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
配置mysql-plus
@Configuration
@MapperScan("com.github.jianzh5.blog.mapper")
public class MybatisPlusConfig {
/**
* 攻击 SQL 阻断解析器
*/
@Bean
public PaginationInterceptor paginationInterceptor(){
PaginationInterceptor paginationInterceptor = new PaginationInterceptor();
List<ISqlParser> sqlParserList = new ArrayList<>();
sqlParserList.add(new BlockAttackSqlParser());
paginationInterceptor.setSqlParserList(sqlParserList);
return new PaginationInterceptor();
}
/**
* SQL执行效率插件
*/
@Bean
// @Profile({"dev","test"})
public PerformanceInterceptor performanceInterceptor() {
return new PerformanceInterceptor();
}
}
编写实体类Order
@Data
@TableName("t_order")
public class Order {
private Long id;
private String name;
private String type;
private Date gmtCreate;
}
编写DAO层,OrderMapper
/**
* 订单Dao层
*/
public interface OrderMapper extends BaseMapper<Order> {
}
编写接口及接口实现
public interface OrderService extends IService<Order> {
}
/**
* 订单实现层
* @author jianzh5
* @date 2019/10/15 17:05
*/
@Service
public class OrderServiceImpl extends ServiceImpl<OrderMapper, Order> implements OrderService {
}
配置文件(配置说明见备注)
server.port=8080
# 配置ds0 和ds1两个数据源
spring.shardingsphere.datasource.names = ds0,ds1
#ds0 配置
spring.shardingsphere.datasource.ds0.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds0.driver-class-name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds0.jdbc-url = jdbc:mysql://192.168.249.129:3306/blog?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.shardingsphere.datasource.ds0.username = root
spring.shardingsphere.datasource.ds0.password = 000000
#ds1 配置
spring.shardingsphere.datasource.ds1.type = com.zaxxer.hikari.HikariDataSource
spring.shardingsphere.datasource.ds1.driver-class-name = com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds1.jdbc-url = jdbc:mysql://192.168.249.131:3306/blog?characterEncoding=utf8&zeroDateTimeBehavior=convertToNull&useSSL=false
spring.shardingsphere.datasource.ds1.username = root
spring.shardingsphere.datasource.ds1.password = 000000
# 分库策略 根据id取模确定数据进哪个数据库
spring.shardingsphere.sharding.default-database-strategy.inline.sharding-column = id
spring.shardingsphere.sharding.default-database-strategy.inline.algorithm-expression = ds$->{id % 2}
# 具体分表策略
# 节点 ds0.t_order_0,ds0.t_order_1,ds1.t_order_0,ds1.t_order_1
spring.shardingsphere.sharding.tables.t_order.actual-data-nodes = ds$->{0..1}.t_order_$->{0..2}
# 分表字段id
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.sharding-column = id
# 分表策略 根据id取模,确定数据最终落在那个表中
spring.shardingsphere.sharding.tables.t_order.table-strategy.inline.algorithm-expression = t_order_$->{id % 3}
# 使用SNOWFLAKE算法生成主键
spring.shardingsphere.sharding.tables.t_order.key-generator.column = id
spring.shardingsphere.sharding.tables.t_order.key-generator.type = SNOWFLAKE
#spring.shardingsphere.sharding.binding-tables=t_order
spring.shardingsphere.props.sql.show = true
编写单元测试,查看结果是否正确
public class OrderServiceImplTest extends BlogApplicationTests {
@Autowired
private OrderService orderService;
@Test
public void testSave(){
for (int i = 0 ; i< 100 ; i++){
Order order = new Order();
order.setName("电脑"+i);
order.setType("办公");
orderService.save(order);
}
}
@Test
public void testGetById(){
long id = 1184489163202789377L;
Order order = orderService.getById(id);
System.out.println(order.toString());
}
}
在数据表中查看数据,确认数据正常插入
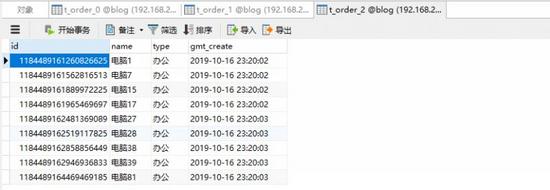
至此分库分表开发完成
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
SpringBoot 2.0 整合sharding-jdbc中间件实现数据分库分表
一.水平分割 1.水平分库 1).概念: 以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中. 2).结果 每个库的结构都一样:数据都不一样: 所有库的并集是全量数据: 2.水平分表 1).概念 以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中. 2).结果 每个表的结构都一样:数据都不一样: 所有表的并集是全量数据: 二.Shard-jdbc 中间件 1.架构图 2.特点 1).Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零. 2).适
-
Springboot2.x+ShardingSphere实现分库分表的示例代码
之前一篇文章中我们讲了基于Mysql8的读写分离(文末有链接),这次来说说分库分表的实现过程. 概念解析 垂直分片 按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用. 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务.而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库. 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案. 垂直分片往往需要对架构和设计进行调整.通常来讲,是来不及应对互联网业务需求快速变化
-

Java基于ShardingSphere实现分库分表的实例详解
目录 一.简介 二.项目使用 1.引入依赖 2.数据库 3.实体类 4.mapper 5.yml配置 6.测试类 7.数据 一.简介 Apache ShardingSphere 是一套开源的分布式数据库解决方案组成的生态圈,它由 JDBC.Proxy 和 Sidecar(规划中)这 3 款既能够独立部署,又支持混合部署配合使用的产品组成. 它们均提供标准化的数据水平扩展.分布式事务和分布式治理等功能,可适用于如 Java 同构.异构语言.云原生等各种多样化的应用场景. Apache Sh
-
利用Sharding-Jdbc进行分库分表的操作代码
目录 1. Sharding-Jdbc介绍 2. Sharding-Jdbc引入使用 3. 配置广播表 4. 配置绑定表 5. 读写分离配置 1. Sharding-Jdbc介绍 https://shardingsphere.apache.org/ sharding-jdbc是一个分布式的关系型数据库中间件 客户端代理模式,不需要搭建服务器,只需要后端数据库即可,有个IDE就行了 定位于轻量级的Java框架,以jar的方式提供服务 可以理解为增强版的jdbc驱动 完全兼容主流的ORM框架 sha
-
springboot+mybatis-plus基于拦截器实现分表的示例代码
目录 前言 一.设计思路 二.实现思路 三.代码实现 接口描述 核心组成部分 1.本地线程工具类 2.注解部分 3.拦截器实现 四.测试 后记 前言 最近在工作遇到数据量比较多的情况,单表压力比较大,crud的操作都受到影响,因为某些原因,项目上没有引入sharding-jdbc这款优秀的分表分库组件,所以打算简单写一个基于mybatis拦截器的分表实现 一.设计思路 在现有的业务场景下,主要实现的目标就是表名的替换,需要解决的问题有 如何从执行的方法中,获取对应的sql并解析获取当前执行的表名
-
SpringBoot 如何使用sharding jdbc进行分库分表
目录 基于4.0版本,Springboot2.1 在pom里确保有如下引用 里面我profiles.active了另一个 之后手工把表都建好 写个测试代码 需要注意一个坑 基于4.0版本,Springboot2.1 之前写过一篇使用sharding-jdbc进行分库分表的文章,不过当时的版本还比较早,现在已经不能用了.这一篇是基于最新版来写的. 新版已经变成了shardingsphere了,https://shardingsphere.apache.org/. 有点不同的是,这一篇,我们是采用多
-
Java中ShardingSphere分库分表实战
目录 一. 项目需求 二. 简介sharding-sphere 三. 项目实战 四. 测试 一. 项目需求 我们做项目的时候,数据量比较大,单表千万级别的,需要分库分表,于是在网上搜索这方面的开源框架,最常见的就是mycat,sharding-sphere,最终我选择后者,用它来做分库分表比较容易上手. 二. 简介sharding-sphere 官网地址: https://shardingsphere.apache.org/ ShardingSphere是一套开源的分布式数据库中间件解决方案组成
-
springboot整合shardingjdbc实现分库分表最简单demo
一.概览 1.1 简介 ShardingSphere-JDBC定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务. 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架. 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC. 支持任何第三方的数据库连接池,如:DBCP,
-
SpringBoot整合sharding-jdbc实现分库分表与读写分离的示例
目录 一.前言 二.数据库表准备 三.整合 四.docker-compose部署mysql主从 五.本文案例demo源码 一.前言 本文将基于以下环境整合sharding-jdbc实现分库分表与读写分离 springboot2.4.0 mybatis-plus3.4.3.1 mysql5.7主从 https://github.com/apache/shardingsphere 二.数据库表准备 温馨小提示:此sql执行时,如果之前有存在相应库和表会进行自动删除后再创建! DROP DATABAS
-
Spring Boot 集成 Sharding-JDBC + Mybatis-Plus 实现分库分表功能
一. Sharding-jdbc简介 " Sharding-jdbc是开源的数据库操作中间件:定位为轻量级Java框架,在Java的JDBC层提供的额外服务.它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架. 官方文档地址:https://shardingsphere.apache.org/document/current/cn/overview/ 本文demo实现了分库分表功能.如有错误,欢迎各位在评论中指出.不
-
MySQL分库分表与分区的入门指南
前言 关系型数据库比较容易成为系统瓶颈,单机存储容量.连接数.处理能力都有限,当数据量和并发量起来之后,就必须对数据库进行切分了. 数据切分(sharding)的手段就是分库分表.分库分表有两方面,可能是光分库不分表,也可能是光分表不分库. 数据库分布式的核心内容无非就是数据切分,以及切分后对数据的定位.整合. 为什么要分库分表 分表 单表数据量太大时,会严重影响sql执行的性能.一般单表到达几百万的时候,性能就会相对差一些了,这时就得分表了. 分表就是把一个表的数据放到多个表中,然后查询的时候