python实现几种归一化方法(Normalization Method)
数据归一化问题是数据挖掘中特征向量表达时的重要问题,当不同的特征成列在一起的时候,由于特征本身表达方式的原因而导致在绝对数值上的小数据被大数据“吃掉”的情况,这个时候我们需要做的就是对抽取出来的features vector进行归一化处理,以保证每个特征被分类器平等对待。下面我描述几种常见的Normalization Method,并提供相应的python实现(其实很简单):
1、(0,1)标准化:
这是最简单也是最容易想到的方法,通过遍历feature vector里的每一个数据,将Max和Min的记录下来,并通过Max-Min作为基数(即Min=0,Max=1)进行数据的归一化处理:
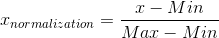
LaTex:{x}_{normalization}=\frac{x-Min}{Max-Min}
Python实现:
def MaxMinNormalization(x,Max,Min): x = (x - Min) / (Max - Min); return x;
找大小的方法直接用np.max()和np.min()就行了,尽量不要用python内建的max()和min(),除非你喜欢用List管理数字。
2、Z-score标准化:
这种方法给予原始数据的均值(mean)和标准差(standard deviation)进行数据的标准化。经过处理的数据符合标准正态分布,即均值为0,标准差为1,这里的关键在于复合标准正态分布,个人认为在一定程度上改变了特征的分布,关于使用经验上欢迎讨论,我对这种标准化不是非常地熟悉,转化函数为:

LaTex:{x}_{normalization}=\frac{x-\mu }{\sigma }
Python实现:
def Z_ScoreNormalization(x,mu,sigma): x = (x - mu) / sigma; return x;
这里一样,mu(即均值)用np.average(),sigma(即标准差)用np.std()即可。
3、Sigmoid函数
Sigmoid函数是一个具有S形曲线的函数,是良好的阈值函数,在(0, 0.5)处中心对称,在(0, 0.5)附近有比较大的斜率,而当数据趋向于正无穷和负无穷的时候,映射出来的值就会无限趋向于1和0,是个人非常喜欢的“归一化方法”,之所以打引号是因为我觉得Sigmoid函数在阈值分割上也有很不错的表现,根据公式的改变,就可以改变分割阈值,这里作为归一化方法,我们只考虑(0, 0.5)作为分割阈值的点的情况:
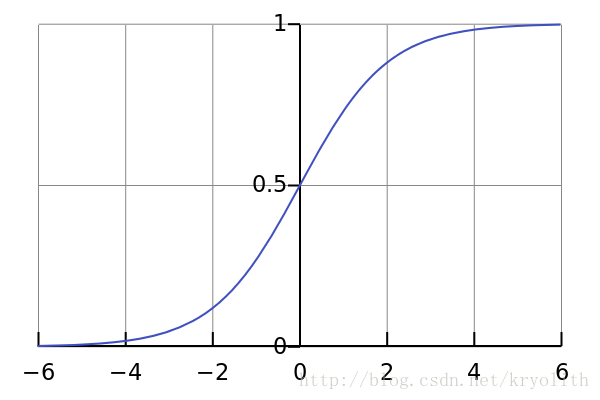
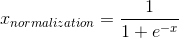
LaTex:{x}_{normalization}=\frac{1}{1+{e}^{-x}}
Python实现:
def sigmoid(X,useStatus): if useStatus: return 1.0 / (1 + np.exp(-float(X))); else: return float(X);
这里useStatus管理是否使用sigmoid的状态,方便调试使用。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python 实现对数据集的归一化的方法(0-1之间)
多数情况下,需要对数据集进行归一化处理,再对数据进行分析 #首先,引入两个库 ,numpy,sklearn from sklearn.preprocessing import MinMaxScaler import numpy as np #将csv文件导入矩阵当中 my_matrix = np.loadtxt(open("xxxx.csv"),delimiter=",",skiprows=0) #将数据集进行归一化处理 scaler = MinMaxScaler(
-
对python3 一组数值的归一化处理方法详解
1.什么是归一化: 归一化就是把一组数(大于1)化为以1为最大值,0为最小值,其余数据按百分比计算的方法.如:1,2,3.,那归一化后就是:0,0.5,1 2.归一化步骤: 如:2,4,6 (1)找出一组数里的最小值和最大值,然后就算最大值和最小值的差值 min = 2: max = 6: r = max - min = 4 (2)数组中每个数都减去最小值 2,4,6 变成 0,2,4 (3)再除去差值r 0,2,4 变成 0,0.5,1 就得出归一化后的数组了 3.用python 把一个矩阵中
-

Python数据预处理之数据规范化(归一化)示例
本文实例讲述了Python数据预处理之数据规范化.分享给大家供大家参考,具体如下: 数据规范化 为了消除指标之间的量纲和取值范围差异的影响,需要进行标准化(归一化)处理,将数据按照比例进行缩放,使之落入一个特定的区域,便于进行综合分析. 数据规范化方法主要有: - 最小-最大规范化 - 零-均值规范化 数据示例 代码实现 #-*- coding: utf-8 -*- #数据规范化 import pandas as pd import numpy as np datafile = 'normali
-
python numpy 按行归一化的实例
如下所示: import numpy as np Z=np.random.random((5,5)) Zmax,Zmin=Z.max(axis=0),Z.min(axis=0) Z=(Z-Zmin)/(Zmax-Zmin) print(Z) 以上这篇python numpy 按行归一化的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
基于数据归一化以及Python实现方式
数据归一化: 数据的标准化是将数据按比例缩放,使之落入一个小的特定区间,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权. 为什么要做归一化: 1)加快梯度下降求最优解的速度 如果两个特征的区间相差非常大,其所形成的等高线非常尖,很有可能走"之字型"路线(垂直等高线走),从而导致需要迭代很多次才能收敛. 2)有可能提高精度 一些分类器需要计算样本之间的距离,如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时
-
详解python实现数据归一化处理的方式:(0,1)标准化
在机器学习过程中,对数据的处理过程中,常常需要对数据进行归一化处理,下面介绍(0, 1)标准化的方式,简单的说,其功能就是将预处理的数据的数值范围按一定关系"压缩"到(0,1)的范围类. 通常(0, 1)标注化处理的公式为: 即将样本点的数值减去最小值,再除以样本点数值最大与最小的差,原理公式就是这么基础. 下面看看使用python语言来编程实现吧 import numpy as np import matplotlib.pyplot as plt def noramlization(
-
python实现几种归一化方法(Normalization Method)
数据归一化问题是数据挖掘中特征向量表达时的重要问题,当不同的特征成列在一起的时候,由于特征本身表达方式的原因而导致在绝对数值上的小数据被大数据"吃掉"的情况,这个时候我们需要做的就是对抽取出来的features vector进行归一化处理,以保证每个特征被分类器平等对待.下面我描述几种常见的Normalization Method,并提供相应的python实现(其实很简单): 1.(0,1)标准化: 这是最简单也是最容易想到的方法,通过遍历feature vector里的每一个数据,将
-
Python深入学习之特殊方法与多范式
Python一切皆对象,但同时,Python还是一个多范式语言(multi-paradigm),你不仅可以使用面向对象的方式来编写程序,还可以用面向过程的方式来编写相同功能的程序(还有函数式.声明式等,我们暂不深入).Python的多范式依赖于Python对象中的特殊方法(special method). 特殊方法名的前后各有两个下划线.特殊方法又被成为魔法方法(magic method),定义了许多Python语法和表达方式,正如我们在下面的例子中将要看到的.当对象中定义了特殊方法的时候,Py
-
python中常用的九种预处理方法分享
本文总结的是我们大家在python中常见的数据预处理方法,以下通过sklearn的preprocessing模块来介绍; 1. 标准化(Standardization or Mean Removal and Variance Scaling) 变换后各维特征有0均值,单位方差.也叫z-score规范化(零均值规范化).计算方式是将特征值减去均值,除以标准差. sklearn.preprocessing.scale(X) 一般会把train和test集放在一起做标准化,或者在train集上做标准化
-
Python单例模式的两种实现方法
Python单例模式的两种实现方法 方法一 import threading class Singleton(object): __instance = None __lock = threading.Lock() # used to synchronize code def __init__(self): "disable the __init__ method" @staticmethod def getInstance(): if not Singleton.__instanc
-
Python with语句上下文管理器两种实现方法分析
本文实例讲述了Python with语句上下文管理器.分享给大家供大家参考,具体如下: 在编程中会经常碰到这种情况:有一个特殊的语句块,在执行这个语句块之前需要先执行一些准备动作:当语句块执行完成后,需要继续执行一些收尾动作.例如,文件读写后需要关闭,数据库读写完毕需要关闭连接,资源的加锁和解锁等情况. 对于这种情况python提供了上下文管理器(Context Manager)的概念,可以通过上下文管理器来定义/控制代码块执行前的准备动作,以及执行后的收尾动作. 一.为何使用上下文管理器 1.
-
Python模拟登录的多种方法(四种)
正文 方法一:直接使用已知的cookie访问 特点: 简单,但需要先在浏览器登录 原理: 简单地说,cookie保存在发起请求的客户端中,服务器利用cookie来区分不同的客户端.因为http是一种无状态的连接,当服务器一下子收到好几个请求时,是无法判断出哪些请求是同一个客户端发起的.而"访问登录后才能看到的页面"这一行为,恰恰需要客户端向服务器证明:"我是刚才登录过的那个客户端".于是就需要cookie来标识客户端的身份,以存储它的信息(如登录状态). 当然,这也
-
Python PCA降维的两种实现方法
目录 前言 PCA降维的一般步骤为: 实现PCA降维,一般有两种方法: 总结 前言 PCA降维,一般是用于数据分析和机器学习.它的作用是把一个高维的数据在保留最大信息量的前提下降低到一个低维的空间,从而使我们能够提取数据的主要特征分量,从而得到对数据影响最大的主成分,便于我们对数据进行分析等后续操作. 例如,在机器学习中,当你想跟据一个数据集来进行预测工作时,往往要采用特征构建.不同特征相乘.相加等操作,来扩建特征,所以,当数据处理完毕后,每个样本往往会有很多个特征,但是,如果把所有数据全部喂入
-
Python编程实现二叉树及七种遍历方法详解
本文实例讲述了Python实现二叉树及遍历方法.分享给大家供大家参考,具体如下: 介绍: 树是数据结构中非常重要的一种,主要的用途是用来提高查找效率,对于要重复查找的情况效果更佳,如二叉排序树.FP-树.另外可以用来提高编码效率,如哈弗曼树. 代码: 用Python实现树的构造和几种遍历算法,虽然不难,不过还是把代码作了一下整理总结.实现功能: ① 树的构造 ② 递归实现先序遍历.中序遍历.后序遍历 ③ 堆栈实现先序遍历.中序遍历.后序遍历 ④ 队列实现层次遍历 #coding=utf-8 cl
-
Python 模拟登陆的两种实现方法
Python 模拟登陆的两种实现方法 有时候我们的抓取项目时需要登陆到某个网站上,才能看见某些内容的,所以模拟登陆功能就必不可少了,散仙这次写的文章,主要有2个例子,一个是普通写法写的,另外一个是基于面向对象写的. 模拟登陆的重点,在于找到表单真实的提交地址,然后携带cookie,post数据即可,只要登陆成功,我们就可以访问其他任意网页,从而获取网页内容. 方式一: import urllib.request import urllib.parse import http.cookiejar
-
遍历python字典几种方法总结(推荐)
如下所示: aDict = {'key1':'value1', 'key2':'value2', 'key3':'value3'} print '-----------dict-------------' for d in aDict: print "%s:%s" %(d, aDict[d]) print '-----------item-------------' for (k,v) in aDict.items(): print '%s:%s' %(k, v) #效率最高 prin