学习Python3 Dlib19.7进行人脸面部识别
0.引言
自己在下载dlib官网给的example代码时,一开始不知道怎么使用,在一番摸索之后弄明白怎么使用了;
现分享下 face_detector.py 和 face_landmark_detection.py 这两个py的使用方法;
1.简介
python: 3.6.3
dlib: 19.7
利用dlib的特征提取器,进行人脸 矩形框 的特征提取:
dets = dlib.get_frontal_face_detector(img)
利用dlib的68点特征预测器,进行人脸 68点 特征提取:
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
shape = predictor(img, dets[0])
效果:
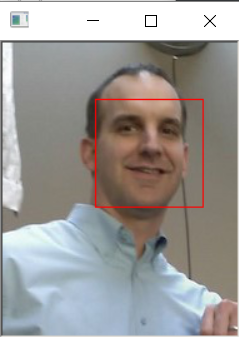

(a) face_detector.py
b) face_landmark_detection.py
2.py文件功能介绍
face_detector.py :
识别出图片文件中一张或多张人脸,并用矩形框框出标识出人脸;
link: http://dlib.net/cnn_face_detector.py.html
face_landmark_detection.py :在face_detector.py的识别人脸基础上,识别出人脸部的具体特征部位:下巴轮廓、眉毛、眼睛、嘴巴,同样用标记标识出面部特征;
link: http://dlib.net/face_landmark_detection.py.html
2.1. face_detector.py
官网给的face_detector.py
#!/usr/bin/python
# The contents of this file are in the public domain. See LICENSE_FOR_EXAMPLE_PROGRAMS.txt
#
# This example program shows how to find frontal human faces in an image. In
# particular, it shows how you can take a list of images from the command
# line and display each on the screen with red boxes overlaid on each human
# face.
#
# The examples/faces folder contains some jpg images of people. You can run
# this program on them and see the detections by executing the
# following command:
# ./face_detector.py ../examples/faces/*.jpg
#
# This face detector is made using the now classic Histogram of Oriented
# Gradients (HOG) feature combined with a linear classifier, an image
# pyramid, and sliding window detection scheme. This type of object detector
# is fairly general and capable of detecting many types of semi-rigid objects
# in addition to human faces. Therefore, if you are interested in making
# your own object detectors then read the train_object_detector.py example
# program.
#
#
# COMPILING/INSTALLING THE DLIB PYTHON INTERFACE
# You can install dlib using the command:
# pip install dlib
#
# Alternatively, if you want to compile dlib yourself then go into the dlib
# root folder and run:
# python setup.py install
# or
# python setup.py install --yes USE_AVX_INSTRUCTIONS
# if you have a CPU that supports AVX instructions, since this makes some
# things run faster.
#
# Compiling dlib should work on any operating system so long as you have
# CMake and boost-python installed. On Ubuntu, this can be done easily by
# running the command:
# sudo apt-get install libboost-python-dev cmake
#
# Also note that this example requires scikit-image which can be installed
# via the command:
# pip install scikit-image
# Or downloaded from http://scikit-image.org/download.html.
import sys
import dlib
from skimage import io
detector = dlib.get_frontal_face_detector()
win = dlib.image_window()
for f in sys.argv[1:]:
print("Processing file: {}".format(f))
img = io.imread(f)
# The 1 in the second argument indicates that we should upsample the image
# 1 time. This will make everything bigger and allow us to detect more
# faces.
dets = detector(img, 1)
print("Number of faces detected: {}".format(len(dets)))
for i, d in enumerate(dets):
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format(
i, d.left(), d.top(), d.right(), d.bottom()))
win.clear_overlay()
win.set_image(img)
win.add_overlay(dets)
dlib.hit_enter_to_continue()
# Finally, if you really want to you can ask the detector to tell you the score
# for each detection. The score is bigger for more confident detections.
# The third argument to run is an optional adjustment to the detection threshold,
# where a negative value will return more detections and a positive value fewer.
# Also, the idx tells you which of the face sub-detectors matched. This can be
# used to broadly identify faces in different orientations.
if (len(sys.argv[1:]) > 0):
img = io.imread(sys.argv[1])
dets, scores, idx = detector.run(img, 1, -1)
for i, d in enumerate(dets):
print("Detection {}, score: {}, face_type:{}".format(
d, scores[i], idx[i]))
为了方便理解,修改增加注释之后的 face_detector.py
import dlib
from skimage import io
# 使用特征提取器frontal_face_detector
detector = dlib.get_frontal_face_detector()
# path是图片所在路径
path = "F:/code/python/P_dlib_face/pic/"
img = io.imread(path+"1.jpg")
# 特征提取器的实例化
dets = detector(img)
print("人脸数:", len(dets))
# 输出人脸矩形的四个坐标点
for i, d in enumerate(dets):
print("第", i, "个人脸d的坐标:",
"left:", d.left(),
"right:", d.right(),
"top:", d.top(),
"bottom:", d.bottom())
# 绘制图片
win = dlib.image_window()
# 清除覆盖
#win.clear_overlay()
win.set_image(img)
# 将生成的矩阵覆盖上
win.add_overlay(dets)
# 保持图像
dlib.hit_enter_to_continue()
对test.jpg进行人脸检测:
结果:
图片窗口结果:

输出结果:
人脸数: 1 第 0 个人脸: left: 79 right: 154 top: 47 bottom: 121 Hit enter to continue
对于多个人脸的检测结果:

2.2 face_landmark_detection.py
官网给的 face_detector.py
#!/usr/bin/python
# The contents of this file are in the public domain. See LICENSE_FOR_EXAMPLE_PROGRAMS.txt
#
# This example program shows how to find frontal human faces in an image and
# estimate their pose. The pose takes the form of 68 landmarks. These are
# points on the face such as the corners of the mouth, along the eyebrows, on
# the eyes, and so forth.
#
# The face detector we use is made using the classic Histogram of Oriented
# Gradients (HOG) feature combined with a linear classifier, an image pyramid,
# and sliding window detection scheme. The pose estimator was created by
# using dlib's implementation of the paper:
# One Millisecond Face Alignment with an Ensemble of Regression Trees by
# Vahid Kazemi and Josephine Sullivan, CVPR 2014
# and was trained on the iBUG 300-W face landmark dataset (see
# https://ibug.doc.ic.ac.uk/resources/facial-point-annotations/):
# C. Sagonas, E. Antonakos, G, Tzimiropoulos, S. Zafeiriou, M. Pantic.
# 300 faces In-the-wild challenge: Database and results.
# Image and Vision Computing (IMAVIS), Special Issue on Facial Landmark Localisation "In-The-Wild". 2016.
# You can get the trained model file from:
# http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2.
# Note that the license for the iBUG 300-W dataset excludes commercial use.
# So you should contact Imperial College London to find out if it's OK for
# you to use this model file in a commercial product.
#
#
# Also, note that you can train your own models using dlib's machine learning
# tools. See train_shape_predictor.py to see an example.
#
#
# COMPILING/INSTALLING THE DLIB PYTHON INTERFACE
# You can install dlib using the command:
# pip install dlib
#
# Alternatively, if you want to compile dlib yourself then go into the dlib
# root folder and run:
# python setup.py install
# or
# python setup.py install --yes USE_AVX_INSTRUCTIONS
# if you have a CPU that supports AVX instructions, since this makes some
# things run faster.
#
# Compiling dlib should work on any operating system so long as you have
# CMake and boost-python installed. On Ubuntu, this can be done easily by
# running the command:
# sudo apt-get install libboost-python-dev cmake
#
# Also note that this example requires scikit-image which can be installed
# via the command:
# pip install scikit-image
# Or downloaded from http://scikit-image.org/download.html.
import sys
import os
import dlib
import glob
from skimage import io
if len(sys.argv) != 3:
print(
"Give the path to the trained shape predictor model as the first "
"argument and then the directory containing the facial images.\n"
"For example, if you are in the python_examples folder then "
"execute this program by running:\n"
" ./face_landmark_detection.py shape_predictor_68_face_landmarks.dat ../examples/faces\n"
"You can download a trained facial shape predictor from:\n"
" http://dlib.net/files/shape_predictor_68_face_landmarks.dat.bz2")
exit()
predictor_path = sys.argv[1]
faces_folder_path = sys.argv[2]
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor(predictor_path)
win = dlib.image_window()
for f in glob.glob(os.path.join(faces_folder_path, "*.jpg")):
print("Processing file: {}".format(f))
img = io.imread(f)
win.clear_overlay()
win.set_image(img)
# Ask the detector to find the bounding boxes of each face. The 1 in the
# second argument indicates that we should upsample the image 1 time. This
# will make everything bigger and allow us to detect more faces.
dets = detector(img, 1)
print("Number of faces detected: {}".format(len(dets)))
for k, d in enumerate(dets):
print("Detection {}: Left: {} Top: {} Right: {} Bottom: {}".format(
k, d.left(), d.top(), d.right(), d.bottom()))
# Get the landmarks/parts for the face in box d.
shape = predictor(img, d)
print("Part 0: {}, Part 1: {} ...".format(shape.part(0), shape.part(1)))
# Draw the face landmarks on the screen.
win.add_overlay(shape)
win.add_overlay(dets)
dlib.hit_enter_to_continue()
修改:
绘制两个overlay,矩阵框 和 面部特征
import dlib
from skimage import io
# 使用特征提取器frontal_face_detector
detector = dlib.get_frontal_face_detector()
# dlib的68点模型
path_pre = "F:/code/python/P_dlib_face/"
predictor = dlib.shape_predictor(path_pre+"shape_predictor_68_face_landmarks.dat")
# 图片所在路径
path_pic = "F:/code/python/P_dlib_face/pic/"
img = io.imread(path_pic+"1.jpg")
# 生成dlib的图像窗口
win = dlib.image_window()
win.clear_overlay()
win.set_image(img)
# 特征提取器的实例化
dets = detector(img, 1)
print("人脸数:", len(dets))
for k, d in enumerate(dets):
print("第", k, "个人脸d的坐标:",
"left:", d.left(),
"right:", d.right(),
"top:", d.top(),
"bottom:", d.bottom())
# 利用预测器预测
shape = predictor(img, d)
# 绘制面部轮廓
win.add_overlay(shape)
# 绘制矩阵轮廓
win.add_overlay(dets)
# 保持图像
dlib.hit_enter_to_continue()
结果:
人脸数: 1 第 0 个人脸d的坐标: left: 79 right: 154 top: 47 bottom: 121
图片窗口结果:
蓝色的是绘制的 win.add_overlay(shape) 红色的是绘制的 win.add_overlay(dets)

对于多张人脸的检测结果:
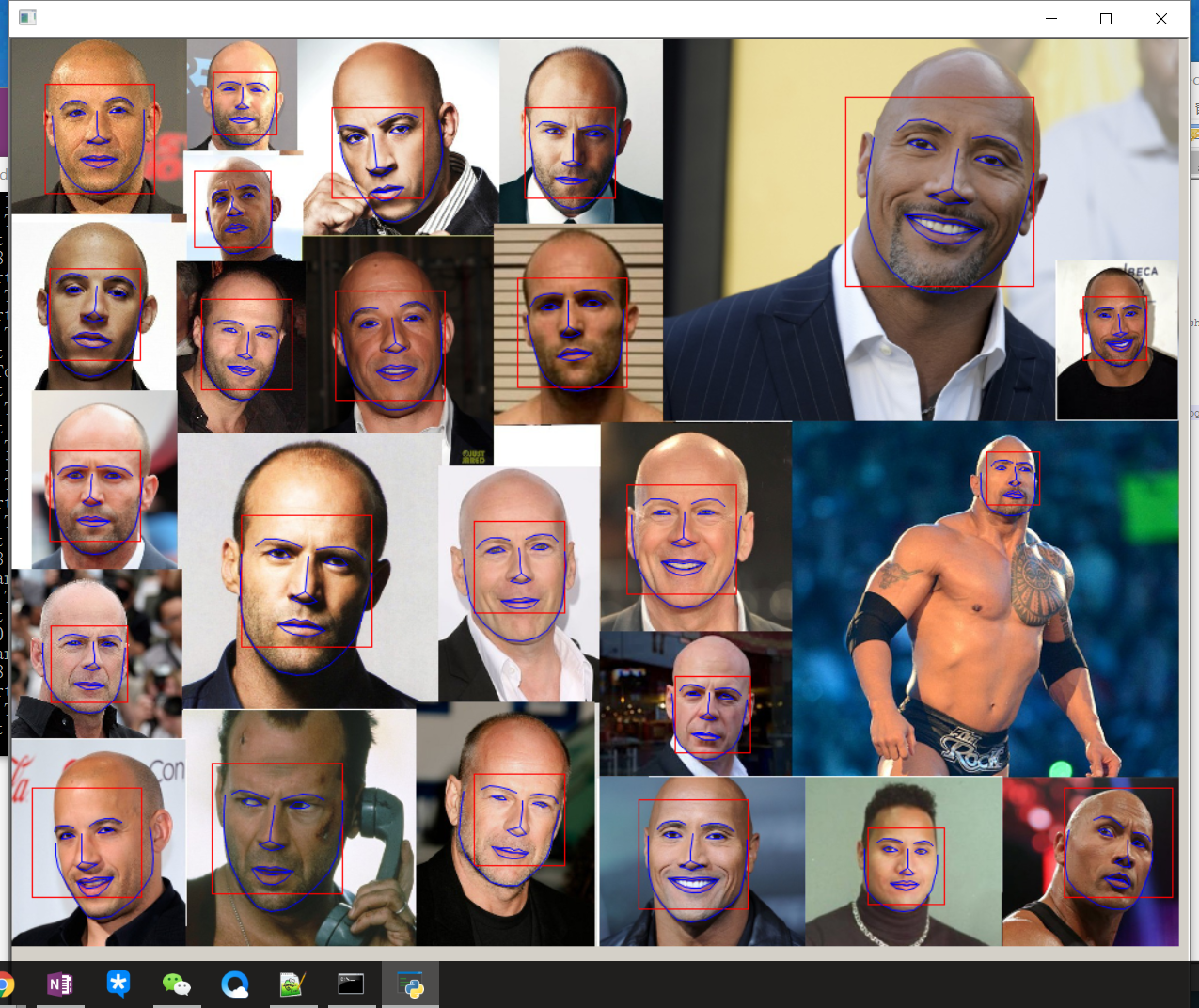
官网例程中是利用sys.argv[]读取命令行输入,其实为了方便我把文件路径写好了,如果对于sys.argv[]有疑惑,可以参照下面的总结:
* 关于sys.argv[]的使用:
( 如果对于代码中 sys.argv[] 的使用不了解可以参考这里 )
用来获取cmd命令行参数,例如 获取cmd命令输入“python test.py XXXXX” 的XXXXX参数,可以用于cmd下读取用户输入的文件路径;
如果不明白可以在python代码内直接 img = imread("F:/*****/test.jpg") 代替 img = imread(sys.argv[1]) 读取图片;
用代码实例来帮助理解:
1.(sys.argv[0],指的是代码文件本身在的路径)
test1.py:
import sys a=sys.argv[0] print(a)
cmd input:
python test1.py
cmd output:
test1.py
2.(sys.argv[1],cmd输入获取的参数字符串中,第一个字符)
test2.py:
import sys a=sys.argv[1] print(a)
cmd input:
python test2.py what is your name
cmd output:
what
(sys.argv[1:],cmd输入获取的参数字符串中,从第一个字符开始到结束)
test3.py:
import sys a=sys.argv[1:] print(a)
cmd input:
python test3.py what is your name
cmd output:
[“what”,“is”,“your”,“name”]
3.(sys.argv[2],cmd输入获取的参数字符串中,第二个字符)
test4.py:
import sys a=sys.argv[2] print(a)
cmd input:
python test4.py what is your name
cmd output:
"is"
您可能感兴趣的文章:
- Python实现识别手写数字 Python图片读入与处理
- Python实现识别手写数字大纲
- python实现识别手写数字 python图像识别算法
- python实现图像识别功能
- Python3结合Dlib实现人脸识别和剪切
- 用Python进行简单图像识别(验证码)
- Python3一行代码实现图片文字识别的示例
- Python用sndhdr模块识别音频格式详解
- Python用imghdr模块识别图片格式实例解析
- Python实现识别手写数字 简易图片存储管理系统
相关推荐
-

Python3一行代码实现图片文字识别的示例
自学Python3第5天,今天突发奇想,想用Python识别图片里的文字.没想到Python实现图片文字识别这么简单,只需要一行代码就能搞定 from PIL import Image import pytesseract #上面都是导包,只需要下面这一行就能实现图片文字识别 text=pytesseract.image_to_string(Image.open('denggao.jpeg'),lang='chi_sim') print(text) 我们以识别诗词为例 下面是我们要识别的图片 先
-
Python3结合Dlib实现人脸识别和剪切
0.引言 利用python开发,借助Dlib库进行人脸识别,然后将检测到的人脸剪切下来,依次排序显示在新的图像上: 实现的效果如下图所示,将图1原图中的6张人脸检测出来,然后剪切下来,在图像窗口中依次输出显示人脸: 实现比较简单,代码量也比较少,适合入门或者兴趣学习. 图1 原图和处理后得到的图像窗口 1.开发环境 python: 3.6.3 dlib: 19.7 OpenCv, numpy import dlib # 人脸识别的库dlib import numpy as np # 数据处理的库
-
python实现识别手写数字 python图像识别算法
写在前面 这一段的内容可以说是最难的一部分之一了,因为是识别图像,所以涉及到的算法会相比之前的来说比较困难,所以我尽量会讲得清楚一点. 而且因为在编写的过程中,把前面的一些逻辑也修改了一些,将其变得更完善了,所以一切以本篇的为准.当然,如果想要直接看代码,代码全部放在我的GitHub中,所以这篇文章主要负责讲解,如需代码请自行前往GitHub. 本次大纲 上一次写到了数据库的建立,我们能够实时的将更新的训练图片存入CSV文件中.所以这次继续往下走,该轮到识别图片的内容了. 首先我们需要从文件夹中
-
用Python进行简单图像识别(验证码)
这是一个最简单的图像识别,将图片加载后直接利用Python的一个识别引擎进行识别 将图片中的数字通过 pytesseract.image_to_string(image)识别后将结果存入到本地的txt文件中 #-*-encoding:utf-8-*- import pytesseract from PIL import Image class GetImageDate(object): def m(self): image = Image.open(u"C:\\a.png") text
-
Python实现识别手写数字 Python图片读入与处理
写在前面 在上一篇文章Python徒手实现手写数字识别-大纲中,我们已经讲过了我们想要写的全部思路,所以我们不再说全部的思路. 我这一次将图片的读入与处理的代码写了一下,和大纲写的过程一样,这一段代码分为以下几个部分: 读入图片: 将图片读取为灰度值矩阵: 图片背景去噪: 切割图片,得到手写数字的最小矩阵: 拉伸/压缩图片,得到标准大小为100x100大小矩阵: 将图片拉为1x10000大小向量,存入训练矩阵中. 所以下面将会对这几个函数进行详解. 代码分析 基础内容 首先我们现在最前面定义基础
-
Python用imghdr模块识别图片格式实例解析
imghdr模块 功能描述:imghdr模块用于识别图片的格式.它通过检测文件的前几个字节,从而判断图片的格式. 唯一一个API imghdr.what(file, h=None) 第一个参数file可以是用rb模式打开的file对象或者表示路径的字符串和PathLike对象.h参数是一段字节串.函数返回表示图片格式的字符串. >>> import imghdr >>> imghdr.what('test.jpg') 'jpeg' 具体的返回值和描述如下: 返回值 描述
-
python实现图像识别功能
本文实例为大家分享了python实现图像识别的具体代码,供大家参考,具体内容如下 #! /usr/bin/env python from PIL import Image import pytesseract url='img/denggao.jpeg' image=Image.open(url) #image=image.convert('RGB') # RGB image=image.convert('L') # 灰度 image.load() text=pytesseract.image_
-
Python实现识别手写数字大纲
写在前面 其实我之前写过一个简单的识别手写数字的程序,但是因为逻辑比较简单,而且要求比较严苛,是在50x50大小像素的白底图上手写黑色数字,并且给的训练材料也不够多,导致准确率只能五五开.所以这一次准备写一个加强升级版的,借此来提升我对Python处理文件与图片的能力. 这次准备加强难度: 被识别图片可以是任意大小: 不一定是白底图,只要数字颜色是黑色,周围环境是浅色就行: 加强识别手写数字的逻辑,提升准确率. 因为我还没开始正式写,并且最近专业课程学习也比较紧迫,所以可能更新的比较慢.不过放心
-
Python用sndhdr模块识别音频格式详解
本文主要介绍了Python编程中,用sndhdr模块识别音频格式的相关内容,具体如下. sndhdr模块 功能描述:sndhdr模块提供检测音频类型的接口. 唯一一个API sndhdr模块提供了sndhdr.what(filename)和sndhdr.whathdr(filename)两个函数.但实际上它们的功能是一样的.(不知道多写一个的意义何在,what函数在内部调用了whathdr函数并把数据完完整整地返回) 在之前的版本,whathdr函数返回元组类型的数据,在Python3.5版本之
-
Python实现识别手写数字 简易图片存储管理系统
写在前面 上一篇文章Python实现识别手写数字-图像的处理中我们讲了图片的处理,将图片经过剪裁,拉伸等操作以后将每一个图片变成了1x10000大小的向量.但是如果只是这样的话,我们每一次运行的时候都需要将他们计算一遍,当图片特别多的时候会消耗大量的时间. 所以我们需要将这些向量存入一个文件当中,每次先看看图库中有没有新增的图片,如果有新增的图片,那么就将新增的图片变成1x10000向量再存入文件之中,然后从文件中读取全部图片向量即可.当图库中没有新增图片的时候,那么就直接调用文件中的图片向量进