图文详解JAVA实现哈夫曼树
前言
我想学过数据结构的小伙伴一定都认识哈夫曼,这位大神发明了大名鼎鼎的“最优二叉树”,为了纪念他呢,我们称之为“哈夫曼树”。哈夫曼树可以用于哈夫曼编码,编码的话学问可就大了,比如用于压缩,用于密码学等。今天一起来看看哈夫曼树到底是什么东东。
概念
当然,套路之一,首先我们要了解一些基本概念。
1、路径长度:从树中的一个结点到另一个结点之间的分支构成这两个结点的路径,路径上的分支数目称为路径长度。
2、树的路径长度:从树根到每一个结点的路径长度之和,我们所说的完全二叉树就是这种路径长度最短的二叉树。
3、树的带权路径长度:如果在树的每一个叶子结点上赋上一个权值,那么树的带权路径长度就等于根结点到所有叶子结点的路径长度与叶子结点权值乘积的总和。
那么我们怎么判断一棵树是否为最优二叉树呢,先看看下面几棵树:

他们的带权长度分别为:
WPL1:7*2+5*2+2*2+4*2=36
WPL2:7*3+5*3+2*1+4*2=46
WPL3:7*1+5*2+2*3+4*3=35
很明显,第三棵树的带权路径最短(不信的小伙伴可以试一试,要是能找到更短的,估计能拿图灵奖了),这就是我们所说的“最优二叉树(哈夫曼树)”,它的构建方法很简单,依次选取权值最小的结点放在树的底部,将最小的两个连接构成一个新结点,需要注意的是构成的新结点的权值应该等于这两个结点的权值之和,然后要把这个新结点放回我们需要构成树的结点中继续进行排序,这样构成的哈夫曼树,所有的存储有信息的结点都在叶子结点上。
概念讲完,可能有点小伙伴还是“不明觉厉”。
下面举个例子构建一下就清楚了。
有一个字符串:aaaaaaaaaabbbbbaaaaaccccccccddddddfff
第一步,我们先统计各个字符出现的次数,称之为该字符的权值。a 15 ,b 5, c 8, d 6, f 3。
第二步,找去这里面权值最小的两个字符,b5和f3,构建节点。
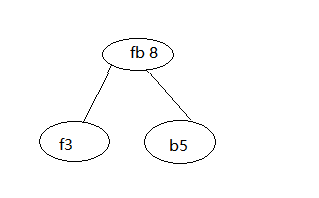
然后将f3和b5去掉,现在是a15,c8,d6,fb8。
第三步,重复第二步,直到构建出只剩一个节点。
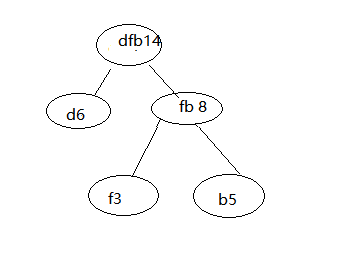
现在是dfb14,a15,c8。
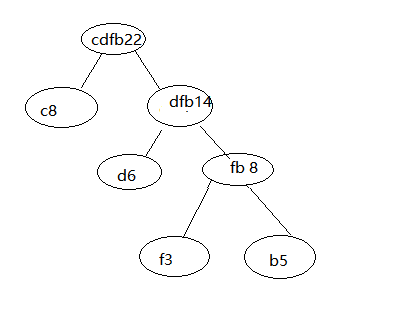
最后,

ok,这样我们的哈夫曼树就构造完成了。
构建的步骤
按照上面的逻辑,总结起来,就是一下几个步骤:
1.统计字符串中字符以及字符的出现次数;
2.根据第一步的结构,创建节点;
3.对节点权值升序排序;
4.取出权值最小的两个节点,生成一个新的父节点;
5.删除权值最小的两个节点,将父节点存放到列表中;
6.重复第四五步,直到剩下一个节点;
7.将最后的一个节点赋给根节点。
java代码
原理说完了,接下来是代码实现了。
首先需要有个节点类来存放数据。
package huffman;
/**
* 节点类
* @author yuxiu
*
*/
public class Node {
public String code;// 节点的哈夫曼编码
public int codeSize;// 节点哈夫曼编码的长度
public String data;// 节点的数据
public int count;// 节点的权值
public Node lChild;
public Node rChild;
public Node() {
}
public Node(String data, int count) {
this.data = data;
this.count = count;
}
public Node(int count, Node lChild, Node rChild) {
this.count = count;
this.lChild = lChild;
this.rChild = rChild;
}
public Node(String data, int count, Node lChild, Node rChild) {
this.data = data;
this.count = count;
this.lChild = lChild;
this.rChild = rChild;
}
}
然后就是实现的过程了。
package huffman;
import java.io.*;
import java.util.*;
public class Huffman {
private String str;// 最初用于压缩的字符串
private String newStr = "";// 哈夫曼编码连接成的字符串
private Node root;// 哈夫曼二叉树的根节点
private boolean flag;// 最新的字符是否已经存在的标签
private ArrayList<String> charList;// 存储不同字符的队列 相同字符存在同一位置
private ArrayList<Node> NodeList;// 存储节点的队列
15 16 /**
* 构建哈夫曼树
*
* @param str
*/
public void creatHfmTree(String str) {
this.str = str;
charList = new ArrayList<String>();
NodeList = new ArrayList<Node>();
// 1.统计字符串中字符以及字符的出现次数
// 基本思想是将一段无序的字符串如ababccdebed放到charList里,分别为aa,bbb,cc,dd,ee
// 并且列表中字符串的长度就是对应的权值
for (int i = 0; i < str.length(); i++) {
char ch = str.charAt(i); // 从给定的字符串中取出字符
flag = true;
for (int j = 0; j < charList.size(); j++) {
if (charList.get(j).charAt(0) == ch) {// 如果找到了同一字符
String s = charList.get(j) + ch;
charList.set(j, s);
flag = false;
break;
}
}
if (flag) {
charList.add(charList.size(), ch + "");
}
}
// 2.根据第一步的结构,创建节点
for (int i = 0; i < charList.size(); i++) {
String data = charList.get(i).charAt(0) + ""; // 获取charList中每段字符串的首个字符
int count = charList.get(i).length(); // 列表中字符串的长度就是对应的权值
Node node = new Node(data, count); // 创建节点对象
NodeList.add(i, node); // 加入到节点队列
}
// 3.对节点权值升序排序
Sort(NodeList);
while (NodeList.size() > 1) {// 当节点数目大于一时
// 4.取出权值最小的两个节点,生成一个新的父节点
// 5.删除权值最小的两个节点,将父节点存放到列表中
Node left = NodeList.remove(0);
Node right = NodeList.remove(0);
int parentWeight = left.count + right.count;// 父节点权值等于子节点权值之和
Node parent = new Node(parentWeight, left, right);
NodeList.add(0, parent); // 将父节点置于首位
}
// 6.重复第四五步,就是那个while循环
// 7.将最后的一个节点赋给根节点
root = NodeList.get(0);
}
/**
* 升序排序
*
* @param nodelist
*/
public void Sort(ArrayList<Node> nodelist) {
for (int i = 0; i < nodelist.size() - 1; i++) {
for (int j = i + 1; j < nodelist.size(); j++) {
Node temp;
if (nodelist.get(i).count > nodelist.get(j).count) {
temp = nodelist.get(i);
nodelist.set(i, nodelist.get(j));
nodelist.set(j, temp);
}
}
}
}
/**
* 遍历
*
* @param node
* 节点
*/
public void output(Node node) {
if (node.lChild != null) {
output(node.lChild);
}
System.out.print(node.count + " "); // 中序遍历
if (node.rChild != null) {
output(node.rChild);
}
}
public void output() {
output(root);
}
/**
* 主方法
*
* @param args
*/
public static void main(String[] args) {
Huffman huff = new Huffman();//创建哈弗曼对象
huff.creatHfmTree("sdfassvvdfgsfdfsdfs");//构造树
}
总结
以上就是基于JAVA实现哈夫曼树的全部内容,希望这篇文章对大家学习使用JAVA能有所帮助。如果有疑问可以留言讨论。
相关推荐
-
java实现哈夫曼压缩的实例
哈夫曼压缩的原理: 通过统计文件中每个字节出现的频率,将8位的01串转换为位数较短的哈夫曼编码. 其中哈夫曼编码是根据文件中字节出现的频率构建的,其中出现频率越高的字节,其路径长度越短; 出现频率越低的字节其路径长度越长.从而达到压缩的目的. 如何构造哈夫曼树? 一. 定义字节类 我的字节类定义了一下属性 public int data;//节点数据 public int weight;//该节点的权值 public int point;//该节点所在的左右位置 0-左 1-右 privat
-
java哈夫曼树实例代码
本文实例为大家分享了哈夫曼树java代码,供大家参考,具体内容如下 package boom; import java.util.ArrayDeque; import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.Queue; class Node<T> implements Comparable<Node<T>>{ private T
-

图文详解JAVA实现哈夫曼树
前言 我想学过数据结构的小伙伴一定都认识哈夫曼,这位大神发明了大名鼎鼎的"最优二叉树",为了纪念他呢,我们称之为"哈夫曼树".哈夫曼树可以用于哈夫曼编码,编码的话学问可就大了,比如用于压缩,用于密码学等.今天一起来看看哈夫曼树到底是什么东东. 概念 当然,套路之一,首先我们要了解一些基本概念. 1.路径长度:从树中的一个结点到另一个结点之间的分支构成这两个结点的路径,路径上的分支数目称为路径长度. 2.树的路径长度:从树根到每一个结点的路径长度之和,我们所说的完全
-
图文详解Java的反射机制
目录 1.什么是反射 2.Hello,java反射 3.java程序运行的三个阶段 4.反射相关类 5.反射的优化 6.Class类分析 7.获取Class对象的六种方式 8.类加载机制 动态加载和静态加载 类加载流程概述 加载阶段 连接阶段 初始化 9.通过反射获取类的结构信息 1.什么是反射 反射就是Reflection,Java的反射是指程序在运行期可以拿到一个对象的所有信息. 加载类后,在堆中就产生了一个class类型的对象,这个对象包含了类的完整结构的信息,通过这个对象得到类的结构.这
-
图文详解Java中的序列化机制
目录 概述 对象序列化和反序列化机制 修改默认的序列化机制 使用transient关键字 自定义readObject.writeObject方法 实现Externalizable接口 serialVersionUID的作用 使用序列化clone 概述 java中的序列化可能大家像我一样都停留在实现Serializable接口上,对于它里面的一些核心机制没有深入了解过.直到最近在项目中踩了一个坑,就是序列化对象添加一个字段以后,使用方系统报了反序列化失败,原因是我们双方的序列化对象没有加上seri
-
Java实现赫夫曼树(哈夫曼树)的创建
目录 一.赫夫曼树是什么? 1.路径和路径长度 2.节点的权和带权路径长度 3.树的带权路径长度 二.创建赫夫曼树 1.图文创建过程 2.代码实现 一.赫夫曼树是什么? 给定N个权值作为N个叶子结点,构造一棵二叉树,若该树的带权路径长度(WPL)达到最小,称这样的二叉树为最优二叉树,也称为哈夫曼树(Huffman Tree).哈夫曼树是带权路径长度最短的树,权值较大的结点离根较近. 图1 一棵赫夫曼树 1.路径和路径长度 在一棵树中,从一个结点往下可以达到的孩子或孙子结点之间的通路,称为路径.
-
图文详解Java中class的初始化顺序
class的装载 在讲class的初始化之前,我们来讲解下class的装载顺序. 以下摘自<Thinking in Java 4> 由于Java 中的一切东西都是对象,所以许多活动 变得更加简单,这个问题便是其中的一例.正如下一章会讲到的那样,每个对象的代码都存在于独立的文件中.除非真的需要代码,否则那个文件是不会载入的.通常,我们可认为除非那个类的一个对象构造完毕,否则代码不会真的载入.由于static 方法存在一些细微的歧义,所以也能认为"类代码在首次使用的时候载入".
-
图文详解Java环境变量配置方法
前言 首先是要安装JDK,JDK安装好之后,还需要在电脑上配置"JAVA_HOME"."path"."classpath"这三个环境变量才能够把java的开发环境搭建好.在没安装过jdk的环境下,path环境变量是系统变量,本来存在的,而JAVA_HOME和classpath是不存在的. 一.配置JAVA_HOME的环境变量[推荐方式,不要使用绝对路径] 操作步骤(win7系统):计算机→右键"属性"→高级系统设置→高级→环境
-
图文详解java内存回收机制
在Java中,它的内存管理包括两方面:内存分配(创建Java对象的时候)和内存回收,这两方面工作都是由JVM自动完成的,降低了Java程序员的学习难度,避免了像C/C++直接操作内存的危险.但是,也正因为内存管理完全由JVM负责,所以也使Java很多程序员不再关心内存分配,导致很多程序低效,耗内存.因此就有了Java程序员到最后应该去了解JVM,才能写出更高效,充分利用有限的内存的程序. 1.Java在内存中的状态 首先我们先写一个代码为例子: Person.java package test
-
图文详解JAVA实现快速排序
高快省的排序算法 有没有既不浪费空间又可以快一点的排序算法呢?那就是"快速排序"啦!光听这个名字是不是就觉得很高端呢. 假设我们现在对"6 1 2 7 9 3 4 5 10 8"这个10个数进行排序.首先在这个序列中随便找一个数作为基准数(不要被这个名词吓到了,就是一个用来参照的数,待会你就知道它用来做啥的了).为了方便,就让第一个数6作为基准数吧.接下来,需要将这个序列中所有比基准数大的数放在6的右边,比基准数小的数放在6的左边,类似下面这种排列: 3 1 2 5
-
图文详解Java中的字节输入与输出流
目录 字节输入流 字节输入流结构图 FileInputStream类 构造方法: 常用读取方法: 字节输出流 字节输出流结构图: FileOutputStream类 构造方法: 常用写入方法: 总结 字节输入流 java.io.InputStream抽象类是所有字节输入流的超类,将数据从文件中读取出来. 字节输入流结构图 在Java中针对文件的读写操作有一些流,其中介绍最常见的字节输入流. FileInputStream类 FileInputStream流被称为字节输入流,对文件以字节的形式读取
-
图文详解Java线程和线程池
目录 一.什么是线程,线程和进程的区别是什么 二.线程中的基本概念,线程的生命周期 三.单线程和多线程 四,线程池的原理解析 五,常见的几种线程池的特点以及各自的应用场景 总结 一.什么是线程,线程和进程的区别是什么 程序执行流的最小执行单位,是行程中的实际运作单位,经常容易和进程这个概念混淆.那么,线程和进程究竟有什么区别呢?首先,进程是一个动态的过程,是一个活动的实体.简单来说,一个应用程序的运行就可以被看做是一个进程,而线程,是运行中的实际的任务执行者.可以说,进程中包含了多个可以同时运行