IntelliJ IDEA下Maven创建Scala项目的方法步骤
环境:IntelliJ IDEA
版本:Spark-2.2.1 Scala-2.11.0
利用 Maven 第一次创建 Scala 项目也遇到了许多坑
创建一个 Scala 的 WordCount 程序
第一步:IntelliJ IDEA下安装 Scala 插件

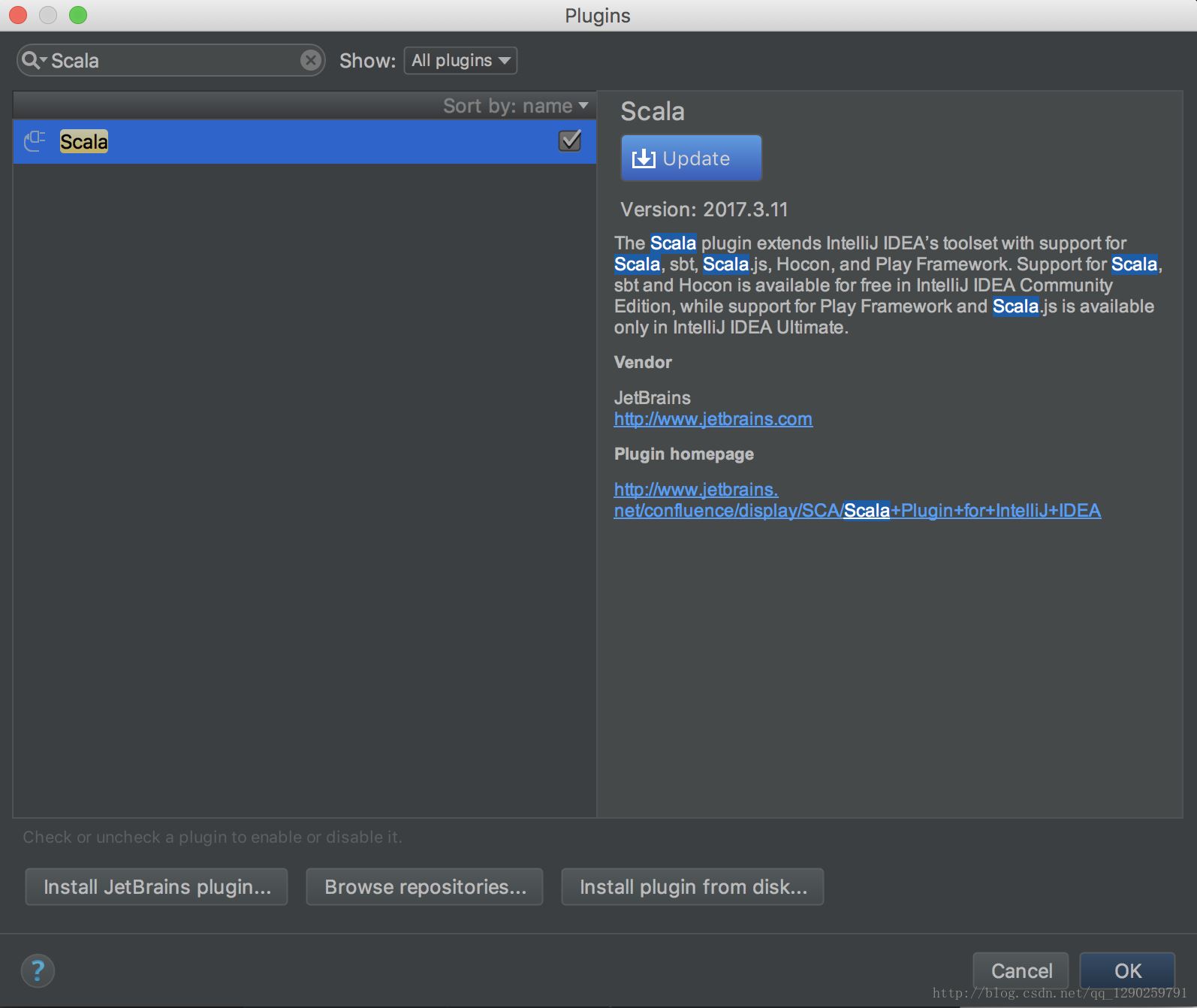
安装完 Scala 插件完成
第二步:Maven 下 Scala 下的项目创建
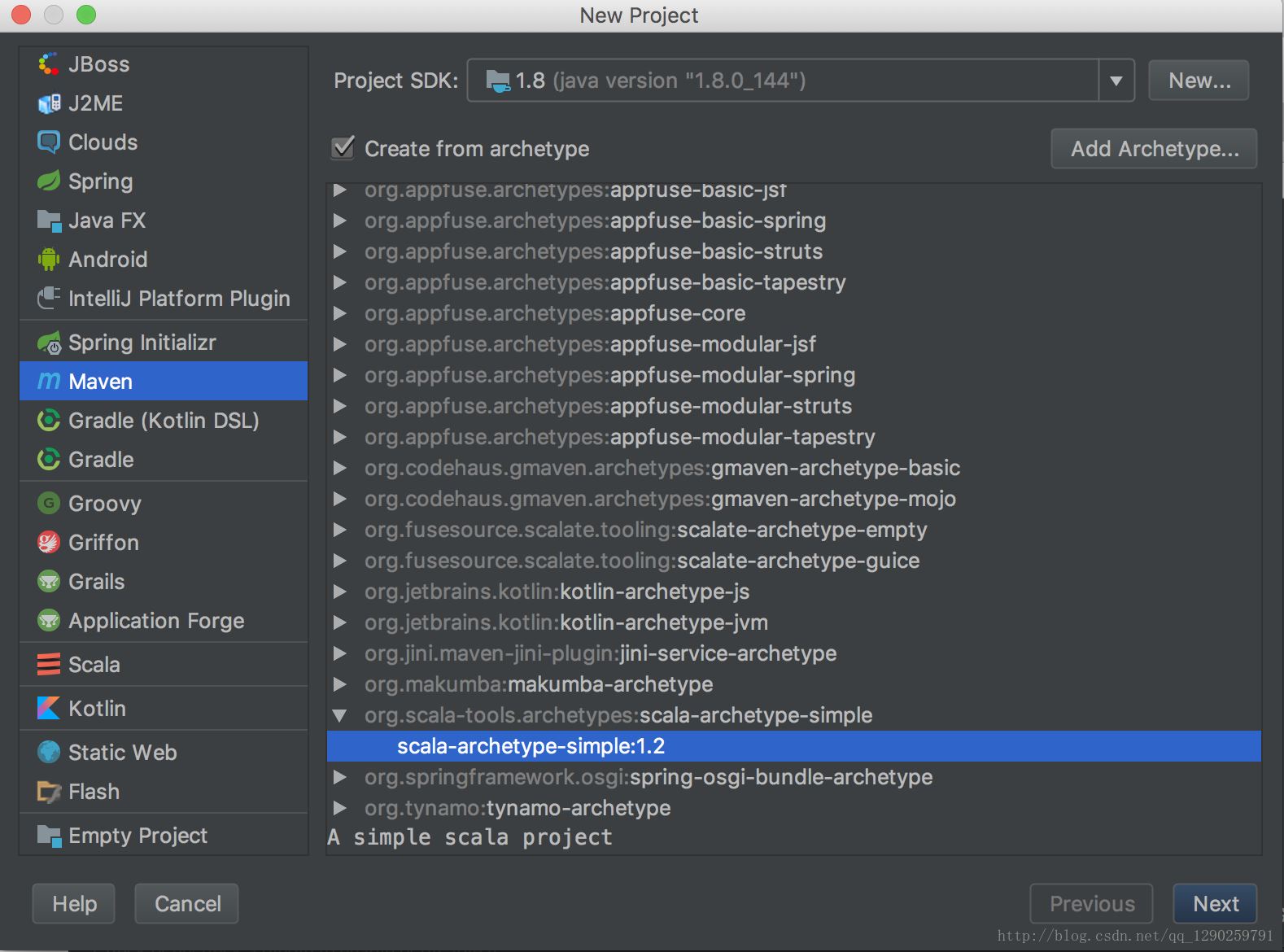
正常创建 Maven 项目(不会的看另一篇 Maven 配置)
第三步:Scala 版本的下载及配置
通过Spark官网下载页面http://spark.apache.org/downloads.html 可知“Note: Starting version 2.0, Spark is built with Scala 2.11 by default.”,建议下载Spark2.2对应的 Scala 2.11。
登录Scala官网http://www.scala-lang.org/,单击download按钮,然后再“Other Releases”标题下找到“下载2.11.0
根据自己的系统下载相应的版本
接下来就是配置Scala 的环境变量(跟 jdk 的配置方法一样)
输入 Scala -version 查看是否配置成功 会显示 Scala code runner version 2.11.0 – Copyright 2002-2013, LAMP/EPFL

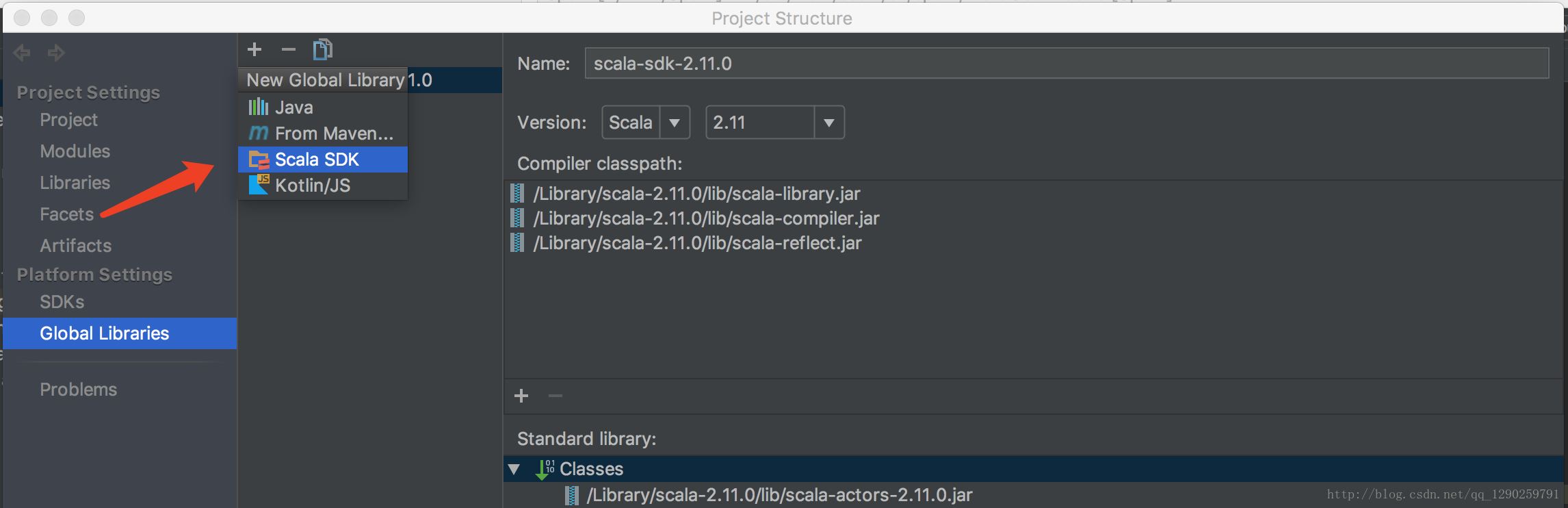
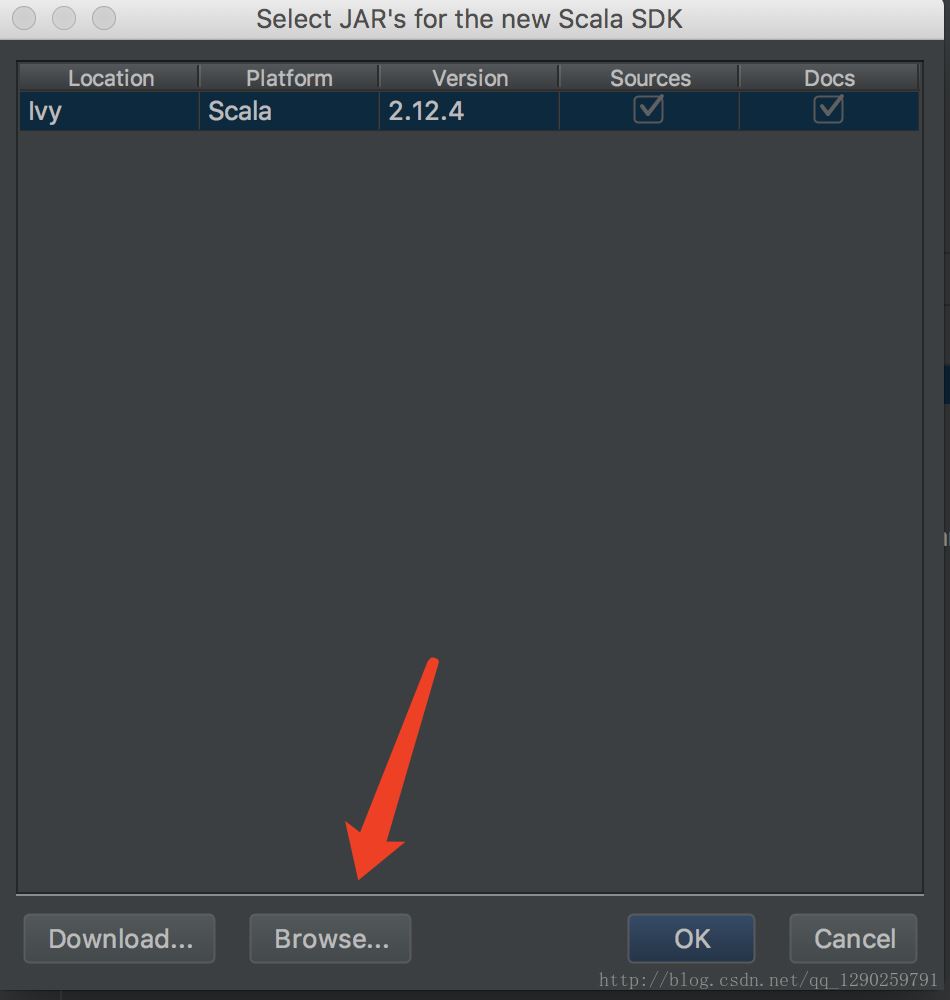
选择自己安装 Scala 的路径
第四步:编写 Scala 程序
将其他的代码删除,不然在编辑的时候会报错
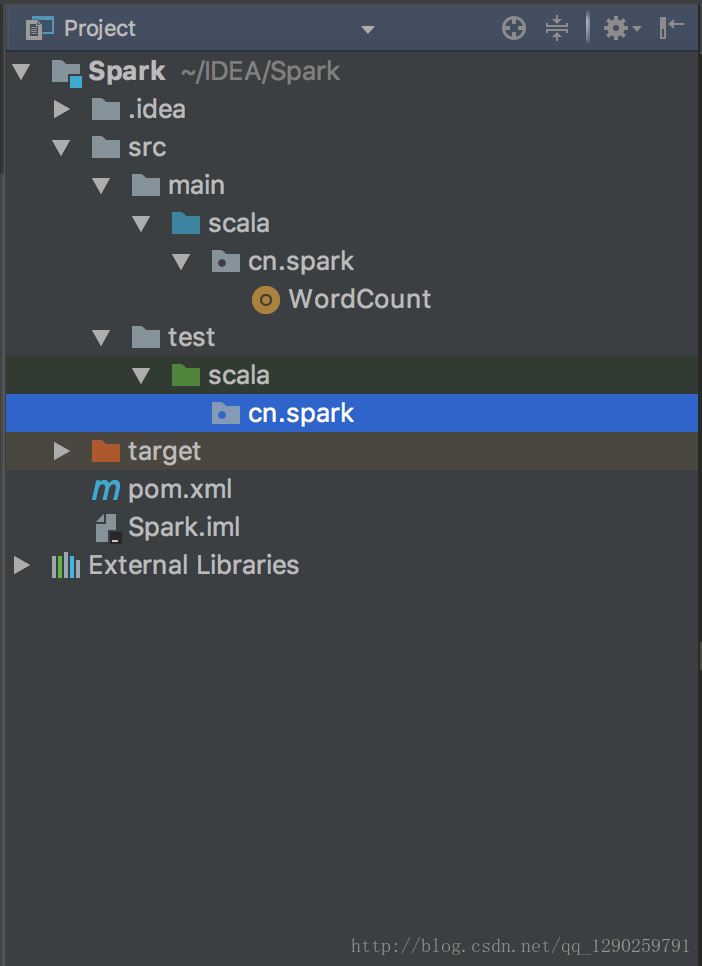
配置 pom.xml文件
在里面添加一个 Spark
<properties>
<scala.version>2.11.0</scala.version>
<spark.version>2.2.1</spark.version>
</properties>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
具体的 pom.xml 内容
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.spark</groupId>
<artifactId>Spark</artifactId>
<version>1.0-SNAPSHOT</version>
<inceptionYear>2008</inceptionYear>
<properties>
<scala.version>2.11.0</scala.version>
<spark.version>2.2.1</spark.version>
</properties>
<pluginRepositories>
<pluginRepository>
<id>scala-tools.org</id>
<name>Scala-Tools Maven2 Repository</name>
<url>http://scala-tools.org/repo-releases</url>
</pluginRepository>
</pluginRepositories>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.4</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.specs</groupId>
<artifactId>specs</artifactId>
<version>1.2.5</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
<args>
<arg>-target:jvm-1.5</arg>
</args>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-eclipse-plugin</artifactId>
<configuration>
<downloadSources>true</downloadSources>
<buildcommands>
<buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand>
</buildcommands>
<additionalProjectnatures>
<projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature>
</additionalProjectnatures>
<classpathContainers>
<classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer>
<classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer>
</classpathContainers>
</configuration>
</plugin>
</plugins>
</build>
<reporting>
<plugins>
<plugin>
<groupId>org.scala-tools</groupId>
<artifactId>maven-scala-plugin</artifactId>
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
</plugins>
</reporting>
</project>
编写 WordCount 文件
package cn.spark
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by hubo on 2018/1/13
*/
object WordCount {
def main(args: Array[String]) {
var masterUrl = "local"
var inputPath = "/Users/huwenbo/Desktop/a.txt"
var outputPath = "/Users/huwenbo/Desktop/out"
if (args.length == 1) {
masterUrl = args(0)
} else if (args.length == 3) {
masterUrl = args(0)
inputPath = args(1)
outputPath = args(2)
}
println(s"masterUrl:$masterUrl, inputPath: $inputPath, outputPath: $outputPath")
val sparkConf = new SparkConf().setMaster(masterUrl).setAppName("WordCount")
val sc = new SparkContext(sparkConf)
val rowRdd = sc.textFile(inputPath)
val resultRdd = rowRdd.flatMap(line => line.split("\\s+"))
.map(word => (word, 1)).reduceByKey(_ + _)
resultRdd.saveAsTextFile(outputPath)
}
}
var masterUrl = “local”
local代表自己本地运行,在 hadoop 上运行添加相应地址
在配置中遇到的错误,会写在另一篇文章里。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

详解IDEA用maven创建springMVC项目和配置
本文介绍了IDEA用maven创建springMVC项目和配置,分享给大家,具体如下: 工具准备:IDEA2016.3 Java jdk 1.8 1.DEA创建项目 新建一个maven project,并且选择webapp原型. 然后点击next 这里的GroupId和ArtifactID随意填写,但是ArtifactID最好和你的项目一名一样然后next 为了快一点创建,我们添加一个属性值,如图中亮的所示,点右边的加号,name=archetypeCatalog value=internal.
-
IntelliJ IDEA创建maven多模块项目(图文教程)
项目主要分成3个模块,wms-root为父模块,wms-core和wms-app(webapp类型的模块)为子模块. 一.Parent Project,创建wms-root父模块. 1.依次点击:File->New->Project 2.左侧面板选择maven(不要选择Create from archetype选项),如下图,点击Next即可. 3.依次补全如下信息,点击Next 4.输入项目名字.如ModuleProject,我们主要是在这个项目下创建我们的子模块. 5.这样我们就创建好了一
-
使用IntelliJ IDEA 15和Maven创建Java Web项目(图文)
1. Maven简介 相对于传统的项目,Maven 下管理和构建的项目真的非常好用和简单,所以这里也强调下,尽量使用此类工具进行项目构建, 它可以管理项目的整个生命周期. 可以通过其命令做所有相关的工作,其常用命令如下: - mvn compile - mvn test - mvn clean - mvn package - mvn install //把新创建的jar包安装到仓库中 - mvn archetype:generate //创建新项目 中央工厂URL:http
-
Maven在Windows中的配置以及IDE中的项目创建(图文教程)
Maven在Windows下的配置 1.Maven下载地址:http://maven.apache.org/download.cgi,下载红框里的版本即可. 2.解压到D盘: 3.修改配置文件settings.xml. a)修改为阿里云的镜像,国内的镜像下载速度会快很多. <mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://m
-
基于maven使用IDEA创建多模块项目
鉴于最近学习一个分布式项目的开发,讲一下关于使用IntelliJ IDEA基于Maven创建多模块项目的实际开发,可能有不合适的地方,但是项目是可以跑通的,也请有不足之处,都提出来,一起讨论下. 一. 项目工程目录 首先展示一下,最终整个项目的工程目录: 简单介绍一下目录结构: common-parent为所有项目的父项目,主要用来管理所有项目使用的jar包及其版本. common-utils为公共的工具类项目,继承父项目,它会被打成jar包供其它项目使用. taotao-manager为我们自
-
初次使用IDEA创建maven项目的教程
第一次使用IDEA,创建一个maven项目,首先下载maven,官方地址:http://maven.apache.org/download.cgi 解压,在环境变量里配置 path里 D:\maven\apache-maven-3.5.2\bin,打开cmd,输入mvn -version 可以查看是否配置成功 打开IDEA,new project,选择maven项目,Project SDK选择自己的jdk, 选中webapp项目,点击next,GroupId是组名(一般是域名+公司名或姓名),A
-
Maven在Windows中的配置以及IDE中的项目创建实例
Maven在Windows下的配置 1.Maven下载地址:http://maven.apache.org/download.cgi,下载红框里的版本即可. 2.解压到D盘: 3.修改配置文件settings.xml. a)修改为阿里云的镜像,国内的镜像下载速度会快很多. <mirrors> <mirror> <id>alimaven</id> <name>aliyun maven</name> <url>http://m
-
使用maven创建web项目的方法步骤(图文)
目前做的项目使用的是MAVEN来管理jar包,这也是我第一次接触maven,感觉非常好,再也不用一个一个去添加和下载jar包了,直接在maven配置文件中配置就可以了,maven可以帮助我们自动下载.非常方便.之前比较忙没时间整理,现在整理一下,记录下来,加深印象.当然我们使用maven也只是最基本的,很多其他功能都没有使用到,本篇仅介绍如何创建一个maven项目,不做其他. 环境搭建参考之前一篇博文:http://www.jb51.net/article/131269.htm 下面推荐2个ma
-
IntelliJ IDEA下Maven创建Scala项目的方法步骤
环境:IntelliJ IDEA 版本:Spark-2.2.1 Scala-2.11.0 利用 Maven 第一次创建 Scala 项目也遇到了许多坑 创建一个 Scala 的 WordCount 程序 第一步:IntelliJ IDEA下安装 Scala 插件 安装完 Scala 插件完成 第二步:Maven 下 Scala 下的项目创建 正常创建 Maven 项目(不会的看另一篇 Maven 配置) 第三步:Scala 版本的下载及配置 通过Spark官网下载页面http://spark.a
-
IDEA+Maven创建Spring项目的实现步骤
这篇随笔搭建的工程是普通的Spring工程,用于学习Spring框架,如果要搭建SpringMVC工程,可以参考另一篇 第一步:在IDEA点击new -> project 左侧选择Maven,直接点击Next.第一次使用IDEA的朋友,顶部还要选择Project SDK路径,就是Java的安装路径. 这里随便填一下之后点击Next 选择项目存放路径,或者保持默认,点击Finish,来到工程页面之后,在项目文件夹上右键并选择Add Framework Support 在这个页面找一下Spring,
-
Maven搭建springboot项目的方法步骤
Maven搭建springboot项目 本文是基于Windows 10系统环境,使用Maven搭建springboot项目 Windows 10 apache-maven-3.6.0 IntelliJ IDEA 2018.3.4 x64 一.springboot项目搭建 (1) 新建目录 在某个可用目录下,新建一个文件夹,本文新建目录为 D:\demo\zs200 (2) 创建maven父工程zs200a-parent 填写项目maven坐标 填写项目名称和路径 (2) maven父工程zs20
-
idea2020.1.3 手把手教你创建web项目的方法步骤
首先: IDEA中的项目(project)与eclipse中的项目(project)是不同的概念,IDEA的project 相当于之前eclipse的workspace,IDEA的Module是相当于eclipse的项目(project). 第一步:配置tomcat (1)点击run下面的edit configuration (2)点击template左边的三角 (3)找到Tomcat Server,有两个选项,第一个表示本地的,第二个表示远程的.这里我们因为在自己电脑,选择本地的 (4)点击c
-
vue-cli4.x创建企业级项目的方法步骤
安装脚手架(vue-cli) $ npm install @vue/cli -g //全局安装最新的脚手架 创建项目 $ vue create vue-demo 在创建项目的时候可以使用 $ vue ui 来进行创建,两种方式在创建的时候,直接选择上router和vuex,来进行项目创建 移动端Vant # 通过 npm 安装 $ npm i vant -S # 通过 yarn 安装 $ yarn add vant 我这里都是使用的按需引入,用了 babel-plugin-import 是一款
-
Eclipse+Maven构建Hadoop项目的方法步骤
Maven 翻译为"专家"."内行",是 Apache 下的一个纯 Java 开发的开源项目.基于项目对象模型(Project Object Model 缩写:POM)概念,Maven利用一个中央信息片断能管理一个项目的构建.报告和文档等步骤.Maven 是一个项目管理工具,可以对 Java 项目进行构建.依赖管理. 在开发一些大型项目的时候,需要用到各种各样的开源包jar,为了方便管理及加载jar,使用maven开发项目可以节省大量时间且方便项目移动至新的开发环境
-
使用IDEA创建SpringBoot项目的方法步骤
1.打开IDEA,创建新项目,选择Spring Initializr 2.输入Artifact 3.勾选Web 4.点击finish完成 5.进入项目,可以将以下内容删除 pom.xml文件: <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3
-
IDEA+Maven搭建JavaWeb项目的方法步骤
目录 前言 1. 项目搭建 2. 配置项目 添加web部署的插件 3. 项目运行 使用Tomact插件运行项目 4. 注意事项 前言 本章节主要内容是描述如何使用maven构建javaweb项目 Maven依赖仓库: https://mvnrepository.com/ Tomcat7插件的命令: https://tomcat.apache.org/maven-plugin-trunk/tomcat7-maven-plugin/plugin-info.html 1. 项目搭建 选择maven模板
-
使用koa2创建web项目的方法步骤
Github上有一个express风格的koa脚手架,用着挺方便,一直以来使用koa开发web项目用的也都是那个脚手架,今天想自己从头搭一个web项目,就折腾了一下 脚手架地址: https://github.com/17koa/koa-generator 初始化 使用 npm init 初始化一个nodejs项目 mkdir koa-demo cd koa-demo npm init 一直回车即可,创建好之后目录里会有一个 package.json 文件 安装依赖 npm install --