Python科学计算环境推荐——Anaconda
Anaconda是一个和Canopy类似的科学计算环境,但用起来更加方便。自带的包管理器conda也很强大。
首先是下载安装。Anaconda提供了Python2.7和Python3.4两个版本,同时如果需要其他版本,还可以通过conda来创建。安装完成后可以看到,Anaconda提供了Spyder,IPython和一个命令行。下面来看一下conda。
输入 conda list 来看一下所有安装时自带的Python扩展。粗略看了一下,其中包括了常用的 Numpy , Scipy , matplotlib 和 networkx 等,以及 beautiful-soup , requests , flask , tornado 等网络相关的扩展。
奇怪的是,里边竟然没有 sklearn ,所以首先装一下它。
conda install scikit-learn
如果需要指定版本,也可以直接用 [package-name]=x.x 来指定。
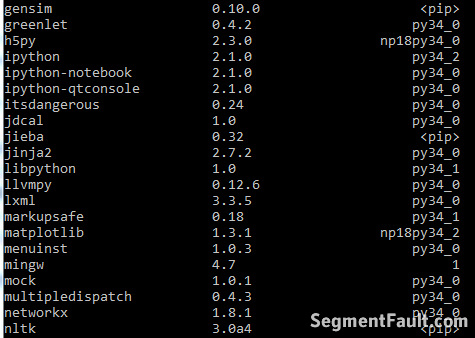
conda的repo中的扩展不算太新,如果想要更新的,可能要用PyPI或者自己下载源码。而conda和pip关联的很好。使用pip安装的东西可以使用conda来管理,这点要比Canopy好。下图是我用pip安装的 nltk , jieba 和 gensim 。
我对这个科学计算环境的另一个要求就是能够多个Python版本并存,尤其是2.x和3.x的并存。这个通过 virtualenv 可以做到。Anaconda也正是通过其实现的。
下面用conda创建一个名叫python2的版本为python2.7的环境。
conda create -n python2 python=2.7
这样就会在Anaconda安装目录下的envs目录下创建python2这个目录。
向其中安装扩展可以:
直接用 conda install 并用 -n 指明安装到的环境,这里自然就是 python2 。
像 virtualenv 那样,先activate,然后在虚拟环境中安装。
这里突然有一个问题,怎样在IDE中使用创建出来的环境?如果是PyCharm等IDE,直接设置Python安装目录就可以了。那spyder呢?其实spyder就是一个Python的扩展,你需要在虚拟环境中也装一个spyder。
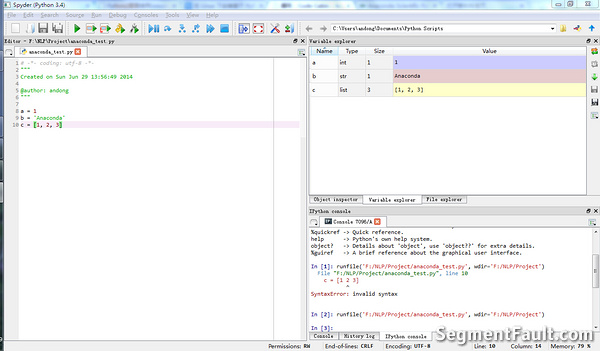
最后就是spyder的主界面。变量查看窗口很好用。
相关推荐
-

更改Ubuntu默认python版本的两种方法python-> Anaconda
你可以按照以下方法使用 ls 命令来查看你的系统中都有那些 Python 的二进制文件可供使用. $ ls /usr/bin/python* /usr/bin/python /usr/bin/python2 /usr/bin/python2.7 /usr/bin/python3 /usr/bin/python3.4 /usr/bin/python3.4m /usr/bin/python3m 执行如下命令查看默认的 Python 版本信息: $ python --version Python 2.
-
利用Anaconda完美解决Python 2与python 3的共存问题
前言 现在Python3 被越来越多的开发者所接受,同时让人尴尬的是很多遗留的老系统依旧运行在 Python2 的环境中,因此有时你不得不同时在两个版本中进行开发,调试. 如何在系统中同时共存 Python2 和 Python3 是开发者不得不面对的问题,一个利好的消息是,Anaconda 能完美解决Python2 和 Python3 的共存问题,而且在 Windows 平台经常出现安装依赖包(比如 MySQL-python)失败的情况也得以解决. Anaconda 是什么? Anaconda
-
解决python3在anaconda下安装caffe失败的问题
Python 跟 Python3 完全就是两种语言 1. import caffe FAILED 环境为 Ubuntu 16 cuda 8.0 NVIDIA 361.77 Anaconda2.昨天莫名其妙Caffe不能用了: >>> import caffe Traceback (most recent call last): File "<stdin>", line 1, in <module> File "/home/duchen
-
python anaconda 安装 环境变量 升级 以及特殊库安装的方法
Anaconda 是一个旗舰版的python安装包, 因为普通的python没有库, 如果需要安装一些重要的库, 要经常一个一个下载,会非常麻烦. 所以这个一个集成的, 可以手动批量升级的软件. 而且库的安装也很全下载速度快. 从官网下载完以后, next 安装好. 配置环境变量, 把安装的文件夹的绝对路径拷贝到 环境变量的path里面. 不配置python都启动不了, 当然,如果之前安装过其他版本的python 可以考虑把之前多余的环境变量路径删掉. 打开anaconda prompt, 输入
-
开源软件包和环境管理系统Anaconda的安装使用
Anaconda 实际上是一个软件发行版,它附带了conda.Python和150多个科学包及其依赖项.其中,conda是一个开源的软件包管理系统和环境管理系统,和 virtualenv 功能差不多,可以在电脑上同时安装Python2和Python3. 安装: 试了下,不能使用pip安装,需要到 官网下载 ,然后安装. conda使用 通过conda管理包 # 安装pandas $ conda install pandas # 更新pandas $ conda update pandas # 删
-
windows上安装Anaconda和python的教程详解
一提到数字图像处理编程,可能大多数人就会想到matlab,但matlab也有自身的缺点: 1.不开源,价格贵 2.软件容量大.一般3G以上,高版本甚至达5G以上. 3.只能做研究,不易转化成软件. 因此,我们这里使用Python这个脚本语言来进行数字图像处理. 要使用Python,必须先安装python,一般是2.7版本以上,不管是在windows系统,还是Linux系统,安装都是非常简单的. 要使用python进行各种开发和科学计算,还需要安装对应的包.这和matlab非常相似,只是matla
-
Python科学计算环境推荐——Anaconda
Anaconda是一个和Canopy类似的科学计算环境,但用起来更加方便.自带的包管理器conda也很强大. 首先是下载安装.Anaconda提供了Python2.7和Python3.4两个版本,同时如果需要其他版本,还可以通过conda来创建.安装完成后可以看到,Anaconda提供了Spyder,IPython和一个命令行.下面来看一下conda. 输入 conda list 来看一下所有安装时自带的Python扩展.粗略看了一下,其中包括了常用的 Numpy , Scipy , matpl
-
深入浅析Python科学计算库Scipy及安装步骤
一.Scipy 入门 1.1.Scipy 简介及安装 官网:http://www.scipy.org/SciPy 安装:在C:\Python27\Scripts下打开cmd执行: 执行:pip install scipy 1.2.安装Anaconda及环境搭建(举例演示) 创建环境:conda create -n env_name python=3.6 示例: conda create -n Py_36 python=3.6 #创建名为Py_367的环境 列出所有环境:conda info
-
Python科学计算之NumPy入门教程
前言 NumPy是Python用于处理大型矩阵的一个速度极快的数学库.它允许你在Python中做向量和矩阵的运算,而且很多底层的函数都是用C写的,你将获得在普通Python中无法达到的运行速度.这是由于矩阵中每个元素的数据类型都是一样的,这也就减少了运算过程中的类型检测. 矩阵基础 在 numpy 包中我们用数组来表示向量,矩阵和高阶数据结构.他们就由数组构成,一维就用一个数组表示,二维就是数组中包含数组表示. 创建 # coding: utf-8 import numpy as np a =
-
配置python的编程环境之Anaconda + VSCode的教程
1.相信大家,在经过前面的初步学习之后,相信大家也想要有一个舒适的编程环境了.接下来将交给大家一个简单的配置环境 Anaconda + VSCode 首先安装 Anaconda,这个顺序是不能改变的,不然你要花费好久好久的时间来配置VSCode 首先 阿纳康达 的下载:1.官网(不需要翻墙) https://www.anaconda.com/download/#windows 2.国内源清华:https://mirrors.tuna.tsinghua.edu.cn/anacond
-
Python科学计算包numpy用法实例详解
本文实例讲述了Python科学计算包numpy用法.分享给大家供大家参考,具体如下: 1 数据结构 numpy使用一种称为ndarray的类似Matlab的矩阵式数据结构管理数据,比python的列表和标准库的array类更为强大,处理数据更为方便. 1.1 数组的生成 在numpy中,生成数组需要指定数据类型,默认是int32,即整数,可以通过dtype参数来指定,一般用到的有int32.bool.float32.uint32.complex,分别代表整数.布尔值.浮点型.无符号整数和复数 一
-
python科学计算之narray对象用法
写在前面 最近在系统的看一些python科学计算开源包的内容,虽然以前是知道一些的,但都属于零零碎碎的,希望这次能把常用的一些函数.注意项整理下.小白的一些废话,高手请略过^ _ ^.文章中的函数仅仅是为了自己好理解,并没有按照官方文档上的函数声明形式记录. numpy.narray numpy.narray创建 numpy.narray的构造方式挺多的,这里就不一一说明,因为一般情况下,在进行科学计算时是通过给定的数据文件来读取的,而读取时使用的是pandas,具体可参考官方文档,或者参见这位
-
python科学计算之scipy——optimize用法
写在前面 SciPy的optimize模块提供了许多数值优化算法,下面对其中的一些记录. 非线性方程组求解 SciPy中对非线性方程组求解是fslove()函数,它的调用形式一般为fslove(fun, x0),fun是计算非线性方程组的误差函数,它需要一个参数x,fun依靠x来计算线性方程组的每个方程的值(或者叫误差),x0是x的一个初始值. """ 计算非线性方程组: 5x1+3 = 0 4x0^2-2sin(x1x2)=0 x1x2-1.5=0 ""
-
python科学计算之numpy——ufunc函数用法
写在前面 ufunc是universal function的缩写,意思是这些函数能够作用于narray对象的每一个元素上,而不是针对narray对象操作,numpy提供了大量的ufunc的函数.这些函数在对narray进行运算的速度比使用循环或者列表推导式要快很多,但请注意,在对单个数值进行运算时,python提供的运算要比numpy效率高. 四则运算 numpy提供的四则ufunc有如下一些: numpy提供的四则运算unfunc能够大大的提高计算效率,但如果运算式复杂,且参与运算的narra
-
Python科学计算之Pandas详解
起步 Pandas最初被作为金融数据分析工具而开发出来,因此 pandas 为时间序列分析提供了很好的支持. Pandas 的名称来自于面板数据(panel data)和python数据分析 (data analysis) .panel data是经济学中关于多维数据集的一个术语,在Pandas中也提供了panel的数据类型. 在我看来,对于 Numpy 以及 Matplotlib ,Pandas可以帮助创建一个非常牢固的用于数据挖掘与分析的基础.而Scipy当然是另一个主要的也十分出色的科学计
-
Python实现计算圆周率π的值到任意位的方法示例
本文实例讲述了Python实现计算圆周率π的值到任意位的方法.分享给大家供大家参考,具体如下: 一.需求分析 输入想要计算到小数点后的位数,计算圆周率π的值. 二.算法:马青公式 π/4=4arctan1/5-arctan1/239 这个公式由英国天文学教授约翰·马青于1706年发现.他利用这个公式计算到了100位的圆周率.马青公式每计算一项可以得到1.4位的十进制精度.因为它的计算过程中被乘数和被除数都不大于长整数,所以可以很容易地在计算机上编程实现. 三.python语言编写出求圆周率到任意