Python 3.x基于Xml数据的Http请求方法
1. 前言
由于公司的一个项目是基于B/S架构与WEB服务通信,使用XML数据作为通信数据,在添加新功能时,WEB端与客户端分别由不同的部门负责,所以在WEB端功能实现过程中,需要自己发起请求测试,于是便选择了使用Python编写此脚本。另外由于此脚本最开始希望能在以后发展成具有压力测试的功能,所以除了基本的访问之外,添加了多线程请求。
整个脚本主要涉及到的关于Python的知识点包括:
基于urllib.request的Http访问
多线程
类与方法的定义
全局变量的定义与使用
文件的读取与写入
……
2. 源码与结果
整个程序包括Python源码和配置文件,由于源码中有相应的注释,所以就直接贴源码吧,如下:
# TradeWeb测试脚本
import threading, time, http.client, urllib.request, os
#import matplotlib.pyplot as plt
URL = 'http://127.0.0.1:8888/XXXXXXXXX/httpXmlServlet' # 在配置文件中读取,此处将无效
TOTAL = 0; # 总数
SUCC = 0; # 响应成功数量
FAIL = 0; # 响应失败数量
EXCEPT = 0 # 响应异常数
MAXTIME = 0 # 最大响应时间
MINTIME = 100 # 最小响应时间,初始值为100秒
COUNT_TIME = 0 # 总时间
THREAD_COUNT = 0 # 记录线程数量
CODE_MAP = {200:0, 301:0, 302:0, 304:0} # 状态码信息(部分)
RESULT_FILE = 'tradeWebResult.xml' # 输出结果文件
REQUEST_DATA_FILE = 'requestData.config' # 数据文件
DATA = '''请在tradeWebRequestData.config文件中配置'''
TIME_LIST = [] # 记录访问时间
#创建一个threading.Thread的派生类
class RequestThread(threading.Thread):
#构造函数
def __init__(self, thread_name):
threading.Thread.__init__(self)
self.test_count = 0;
#线程运行的入口函数
def run(self):
global THREAD_COUNT
THREAD_COUNT += 1
#print("Start the count of thread:%d" %(THREAD_COUNT))
self.testPerformace()
#测试性能方法
def testPerformace(self):
global TOTAL
global SUCC
global FAIL
global EXCEPT
global DATA
global COUNT_TIME
global CODE_MAP
global URL
try:
st = time.time() #记录开始时间
start_time
cookies = urllib.request.HTTPCookieProcessor()
opener = urllib.request.build_opener(cookies)
resp = urllib.request.Request(url=URL,
headers={'Content-Type':'text/xml', 'Connection':'Keep-Alive'},
data=DATA.encode('gbk'))
respResult = opener.open(resp)
# 记录状态码 START
code = respResult.getcode()
if code == 200:
SUCC += 1
else:
FAIL += 1
if code in CODE_MAP.keys():
CODE_MAP[code] += 1
else:
CODE_MAP[code] = 1
# print(request.status)
# 记录状态码 END
html = respResult.read().decode('gbk')
print(html)
time_span = time.time() - st # 计算访问时间
# 记录访问时间
TIME_LIST.append(round(time_span * 1000))
# print('%-13s: %f ' %(self.name, time_span))
self.maxtime(time_span)
self.mintime(time_span)
self.writeToFile(html)
# info = respResult.info() # 响应头信息
# url = respResult.geturl() # URL地址
# print(info);
# print(url)
COUNT_TIME += time_span
TOTAL += 1
except Exception as e:
print(e)
TOTAL += 1
EXCEPT += 1
# 设置最大时间,如果传入的时间大于当前最大时间
def maxtime(self, ts):
global MAXTIME
#print("time:%f" %(ts))
if ts > MAXTIME:
MAXTIME = ts
# 设置最小时间,如果传入的时间小于当前最小时间
def mintime(self, ts):
global MINTIME
#print("time:%f" %(ts))
if ts < MINTIME and ts > 0.000000000000000001:
MINTIME = ts
# 写入文件
def writeToFile(self, html):
f = open(RESULT_FILE, 'w')
f.write(html)
f.write('\r\n')
f.close();
# 读取XML数据信息
def loadData():
global URL
global DATA
f = open(REQUEST_DATA_FILE, 'r')
URL = "".join(f.readline())
DATA = "".join(f.readlines())
# print(DATA)
f.close()
if __name__ == "__main__":
# print("============测试开始============")
print("")
# 开始时间
start_time = time.time()
# 并发的线程数
thread_count = 1
loadData() # 加载请求数据
i = 0
while i < thread_count:
t = RequestThread("Thread" + str(i))
t.start()
i += 1
t = 0
while TOTAL < thread_count and t < 60:
# print("total:%d, succ:%d, fail:%d, except:%d\n" %(TOTAL,SUCC,FAIL,EXCEPT))
print("正在请求 ",URL)
t += 1
time.sleep(1)
# 打印信息
print()
print("请求", URL, "的统计信息:")
print(" 总请求数 = %d,成功 = %d,失败 = %d,异常 = %d" %(TOTAL, SUCC, FAIL, EXCEPT))
print()
print("往返程的估计时间(以毫秒为单位):")
print(" 合计 =", int(COUNT_TIME * 1000), "ms", end = '')
print(" 最大 =", round(MAXTIME * 1000), "ms", end = '')
print(" 最小 =", round(MINTIME * 1000), "ms", end = '')
print(" 平均 =", round((COUNT_TIME / thread_count) * 1000), "ms")
print()
print("响应的状态码与次数信息(状态码:次数):")
print(" ", CODE_MAP)
print()
print("输出页面请查看", RESULT_FILE, "文件(建议使用浏览器或XML专业工具打开)")
print()
# os.system("pause")
print(TIME_LIST)
input()
配置文件主要在于易于更改访问路径等,其中SESSION_ID是在Fiddler中抓包获取,配置文件源文件如下(为不泄露公司隐私,数据并非原始数据,但格式相同):
http://127.0.0.1:8888/XXXXXXXXX/httpXmlServlet <?xml version=“1.0” encoding = “GB2312”?> <COM> <REQ name="commodity_query"> <USER_ID>0001</USER_ID> <COMMODITY_ID>0000</COMMODITY_ID> <SESSION_ID>4918081208706966071</SESSION_ID> </REQ> </COM>
测试结果如下:
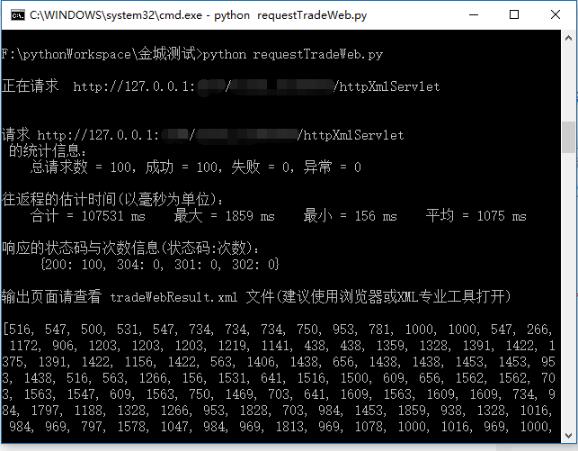
由于公司保密性要求,地址做了模糊处理,另外输出的tradeWebResult.xml结果页面也未展示。
以上仅为个人学习与使用Python过程的一个记录,难免会有程序设计或使用不当,如有更好的意见,欢迎指正。
注:此代码开发环境为Python 3.5 + windows,未在Python 2.x环境下测试
以上这篇Python 3.x基于Xml数据的Http请求方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python基于dom操作xml数据的方法示例
本文实例讲述了Python基于dom操作xml数据的方法.分享给大家供大家参考,具体如下: 1.xml的内容为del.xml,如下 <?xml version="1.0" encoding="utf-8"?> <catalog> <maxid>4</maxid> <login username="pytest" passwd='123456'> <caption>Python
-
python发送HTTP请求的方法小结
本文实例讲述了python发送HTTP请求的方法.分享给大家供大家参考.具体如下: 这里包含 Python 使用 GET/HEAD/POST 方法进行 HTTP 请求 1. GET 方法: >>> import httplib >>> conn = httplib.HTTPConnection("www.python.org") >>> conn.request("GET", "/index.html&
-
详细解读Python中解析XML数据的方法
Python可以使用 xml.etree.ElementTree 模块从简单的XML文档中提取数据. 为了演示,假设你想解析Planet Python上的RSS源.下面是相应的代码: from urllib.request import urlopen from xml.etree.ElementTree import parse # Download the RSS feed and parse it u = urlopen('http://planet.python.org/rss20.xm
-
Python模仿POST提交HTTP数据及使用Cookie值的方法
本文实例讲述了在Python中模仿POST HTTP数据及带Cookie提交数据的实现方法,分享给大家供大家参考.具体实现方法如下: 方法一 如果不使用Cookie, 发送HTTP POST非常简单: 复制代码 代码如下: import urllib2, urllib data = {'name' : 'www', 'password' : '123456'} f = urllib2.urlopen( url = 'http://www.jb51.net/',
-
python通过get,post方式发送http请求和接收http响应的方法
本文实例讲述了python通过get,post方式发送http请求和接收http响应的方法.分享给大家供大家参考.具体如下: 测试用CGI,名字为test.py,放在apache的cgi-bin目录下: #!/usr/bin/python import cgi def main(): print "Content-type: text/html\n" form = cgi.FieldStorage() if form.has_key("ServiceCode") a
-
Python3处理HTTP请求的实例
Python3处理HTTP请求的包:http.client,urllib,urllib3,requests 其中,http 比较 low-level,一般不直接使用 urllib更 high-level一点,属于标准库.urllib3跟urllib类似,拥有一些重要特性而且易于使用,但是属于扩展库,需要安装 requests 基于urllib3 ,也不是标准库,但是使用非常方便 个人感觉,如果非要用标准库,就使用urllib.如果没有限制,就用requests # import http.cli
-
python3.x上post发送json数据
一.摘要 做接口自动化测试时,常常需要使用python发送一些json内容的接口报文,如果使用urlencode对内容进行编码解析并发送请求,会发现服务器返回了200,OK的状态,但响应内容不可读(像是一堆加密报文).定位问题时发现抓包发现发送报文的内容与我们发送的json内容不符(会去掉"{"与"}"等内容),所以重新采用了json封装后,问题解决. 二.解决方法 1.先导入json模块,采用json.dumps将json内容进行封装 eg: import jso
-
Python 3.x基于Xml数据的Http请求方法
1. 前言 由于公司的一个项目是基于B/S架构与WEB服务通信,使用XML数据作为通信数据,在添加新功能时,WEB端与客户端分别由不同的部门负责,所以在WEB端功能实现过程中,需要自己发起请求测试,于是便选择了使用Python编写此脚本.另外由于此脚本最开始希望能在以后发展成具有压力测试的功能,所以除了基本的访问之外,添加了多线程请求. 整个脚本主要涉及到的关于Python的知识点包括: 基于urllib.request的Http访问 多线程 类与方法的定义 全局变量的定义与使用 文件的读取与写
-
Python 解析简单的XML数据
问题 你想从一个简单的XML文档中提取数据. 解决方案 可以使用 xml.etree.ElementTree 模块从简单的XML文档中提取数据.为了演示,假设你想解析Planet Python上的RSS源.下面是相应的代码: from urllib.request import urlopen from xml.etree.ElementTree import parse # Download the RSS feed and parse it u = urlopen('http://plane
-
python flask框架实现传数据到js的方法分析
本文实例讲述了python flask框架实现传数据到js的方法.分享给大家供大家参考,具体如下: 首先要清楚后台和前端交互所采用的数据格式. 一般选JSON,因为和js完美贴合. 后台返回的数据进行序列化 在/homepageRecommend 路由的 view方法中返回序列化数据 dict = {"a":1, "b":2}<br data-filtered="filtered"> import json json.dumps(di
-
python小程序基于Jupyter实现天气查询的方法
天气查询python小程序第0步:导入工具库第一步:生成查询天气的url链接第二步:访问url链接,解析服务器返回的json数据,变成python的字典数据第三步:对字典进行索引,获取气温.风速.风向等天气信息第四步:遍历forecast列表中的五个元素,打印天气信息完整Python代码 本案例是一个非常有趣的python小程序,调用网络API查询指定城市的天气,并打印输出天气信息. 你将学到以下技能: 向网络API发起请求,解析和处理服务器返回的json数据,可以迁移到各种各样的API中,如P
-
PHP实现使用DOM将XML数据存入数组的方法示例
本文实例讲述了PHP实现使用DOM将XML数据存入数组的方法.分享给大家供大家参考,具体如下: <?php $doc = new DOMDocument('1.0','utf-8'); $doc->load("config.xml"); $roots=$doc->documentElement;//获取根节点也就是config(仅有一个) $childs=$roots->childNodes;//获取根节点下所有子节点也就是 db smarty for($i=0
-
C#实现基于XML配置MenuStrip菜单的方法
本文实例讲述了C#实现基于XML配置MenuStrip菜单的方法.分享给大家供大家参考.具体如下: 1.关于本程序的说明 用XML配置MenuStrip菜单,本程序只是提供一个思路.程序在Load函数中根据XML文件中的设置动态生成一个MenuStrip组件的Items集合. 程序示例如下: 2.使用到的XML文档示例 <?xml version="1.0" encoding="gb2312"?> <!--MenuStrip:mnsMainMenu
-
Android发送xml数据给服务器的方法
本文实例讲述了Android发送xml数据给服务器的方法.分享给大家供大家参考.具体如下: 一.发送xml数据: public static void main(String[] args) throws Exception { String xml = "<?xml version=\"1.0\" encoding=\"UTF-8\"?><videos><video><title>中国</title&
-
python pandas中DataFrame类型数据操作函数的方法
python数据分析工具pandas中DataFrame和Series作为主要的数据结构. 本文主要是介绍如何对DataFrame数据进行操作并结合一个实例测试操作函数. 1)查看DataFrame数据及属性 df_obj = DataFrame() #创建DataFrame对象 df_obj.dtypes #查看各行的数据格式 df_obj['列名'].astype(int)#转换某列的数据类型 df_obj.head() #查看前几行的数据,默认前5行 df_obj.tail() #查看后几
-
python 读取文本文件的行数据,文件.splitlines()的方法
一般跟踪训练的ground_truth的数据保存在文本文文件中,故每一行的数据为一张图片的标签数据,这个时候读取每一张图片的标签,具体实现如下: test_txt = '/home/zcm/tensorf/siamfc-tf-master/data/Biker/groundtruth.txt' def load_label_set(label_dir): label_folder = open(label_dir, "r") trainlines = label_folder.read
-
python向json中追加数据的两种方法总结
目录 前言 1. list dump (不推荐) 2. json update (推荐使用) 总结 前言 json以其轻量级的数据交换格式,且易于阅读和编写而使用率很广泛,而使用json的过程中时而需要增加字段,本人验证两种方式之后将其集成梳理. 具体操作详情如下: 1. list dump (不推荐) 采用list方式,向json中添加字段.此法存在一定的问题,不推荐使用. 方法如下: (1)先创建一个列表: json_content = [] (2)将当前json文件中已有的内容读入列表中: