详解Java实现多种方式的http数据抓取
前言:
时下互联网第一波的浪潮已消逝,随着而来的基于万千数据的物联网时代,因而数据成为企业的重要战略资源之一。基于数据抓取技术,本文介绍了java相关抓取工具,并附上demo源码供感兴趣的朋友测试!
1)JDK自带HTTP连接,获取页面或Json
2) JDK自带URL连接,获取页面或Json

3)HttpClient Get工具,获取页面或Json
4)commons-io工具,获取页面或Json

5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式】

--------------------------------------------------------------------------------
完整代码:
package com.yeezhao.common.http;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import org.apache.commons.httpclient.HttpClient;
import org.apache.commons.httpclient.HttpMethod;
import org.apache.commons.httpclient.methods.GetMethod;
import org.apache.commons.io.IOUtils;
import org.jsoup.Jsoup;
/**
* http工具对比
*
* @author Administrator -> junhong
*
* 2016年12月27日
*/
public class HttpFetchUtil {
/**
* 获取访问的状态码
* @param request
* @return
* @throws Exception
*/
public static int getResponseCode(String request) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
return conn.getResponseCode();
}
/**
* 1)JDK自带HTTP连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception
*/
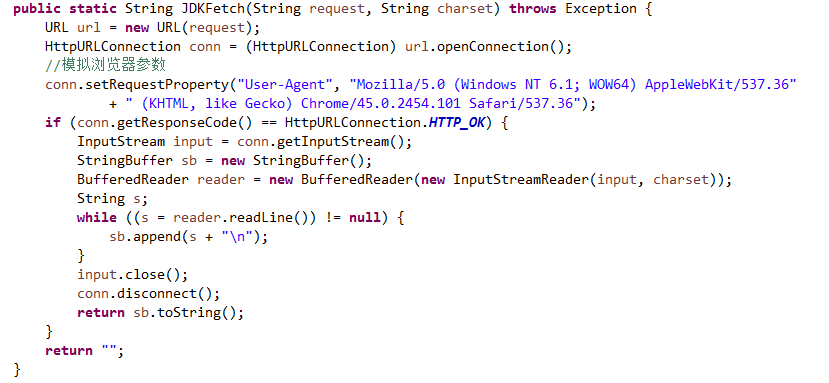
public static String JDKFetch(String request, String charset) throws Exception {
URL url = new URL(request);
HttpURLConnection conn = (HttpURLConnection) url.openConnection();
//模拟浏览器参数
conn.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36"
+ " (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36");
if (conn.getResponseCode() == HttpURLConnection.HTTP_OK) {
InputStream input = conn.getInputStream();
StringBuffer sb = new StringBuffer();
BufferedReader reader = new BufferedReader(new InputStreamReader(input, charset));
String s;
while ((s = reader.readLine()) != null) {
sb.append(s + "\n");
}
input.close();
conn.disconnect();
return sb.toString();
}
return "";
}
/**
* 2) JDK自带URL连接,获取页面或Json
* @param request
* @param charset
* @return
* @throws Exception
*/
public static String URLFetch(String request, String charset) throws Exception {
URL url = new URL(request);
return IOUtils.toString(url.openStream());
}
/**
* 3)HttpClient Get工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception
*/
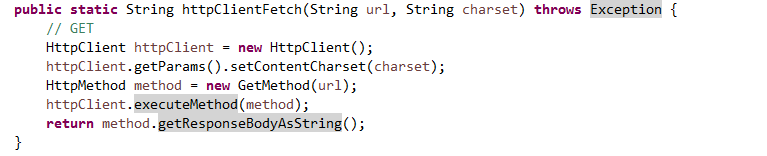
public static String httpClientFetch(String url, String charset) throws Exception {
// GET
HttpClient httpClient = new HttpClient();
httpClient.getParams().setContentCharset(charset);
HttpMethod method = new GetMethod(url);
httpClient.executeMethod(method);
return method.getResponseBodyAsString();
}
/**
* 4)commons-io工具,获取页面或Json
* @param url
* @param charset
* @return
* @throws Exception
*/
public static String commonsIOFetch(String url, String charset) throws Exception {
return IOUtils.toString(new URL(url), charset);
}
/**
* 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式
* @param url
* @return
* @throws Exception
*/
public static String jsoupFetch(String url) throws Exception {
return Jsoup.parse(new URL(url), 2 * 1000).html();
}
}
测试代码:
package com.yeezhao.common.http;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
/**
* 测试类
* 3个测试链接:
* 1)百科网页
* 2)浏览器模拟获取接口数据
* 3)获取普通接口数据
* @author Administrator -> junhong
*
* 2016年12月27日
*/
public class HttpFetchUtilTest {
String seeds[] = {"http://baike.baidu.com/view/1.htm","http://m.ximalaya.com/tracks/26096131.json","http://remyapi.yeezhao.com/api/query?wd=%E5%91%A8%E6%98%9F%E9%A9%B0%E7%9A%84%E7%94%B5%E5%BD%B1"};
final static String DEFAULT_CHARSET = "UTF-8";
@Before
public void setUp() throws Exception {
}
@After
public void tearDown() throws Exception {
System.out.println("--- down ---");
}
@Test
public void testGetResponseCode() throws Exception{
for(String seed:seeds){
int responseCode = HttpFetchUtil.getResponseCode(seed);
System.out.println("ret="+responseCode);
}
}
@Test
public void testJDKFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.JDKFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testURLFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.URLFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testHttpClientFetch()throws Exception {
for(String seed:seeds){
String ret = HttpFetchUtil.httpClientFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testCommonsIOFetch()throws Exception {
for(String seed:seeds){
String ret = HttpFetchUtil.commonsIOFetch(seed, DEFAULT_CHARSET);
System.out.println("ret="+ret);
}
}
@Test
public void testJsoupFetch() throws Exception{
for(String seed:seeds){
String ret = HttpFetchUtil.jsoupFetch(seed);
System.out.println("ret="+ret);
}
}
}
附:相关jar依赖
... <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.7.3</version> </dependency> <dependency> <groupId>commons-httpclient</groupId> <artifactId>commons-httpclient</artifactId> <version>3.1</version> </dependency> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.4</version> </dependency> ...
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
JAVA使用爬虫抓取网站网页内容的方法
本文实例讲述了JAVA使用爬虫抓取网站网页内容的方法.分享给大家供大家参考.具体如下: 最近在用JAVA研究下爬网技术,呵呵,入了个门,把自己的心得和大家分享下 以下提供二种方法,一种是用apache提供的包.另一种是用JAVA自带的. 代码如下: // 第一种方法 //这种方法是用apache提供的包,简单方便 //但是要用到以下包:commons-codec-1.4.jar // commons-httpclient-3.1.jar // commons-logging-1.0.4.jar
-
java 抓取网页内容实现代码
复制代码 代码如下: package test; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStream; import java.io.InputStreamReader; import java.net.Authenticator; import java.net.HttpURLConnection; import java.net.PasswordAuthentication
-

Java模拟新浪微博登陆抓取数据
前言: 兄弟们来了来了,最近有人在问如何模拟新浪微博登陆抓取数据,我听后默默地抽了一口老烟,暗暗的对自己说,老汉是时候该你出场了,所以今天有时间就整理整理,浅谈一二. 首先: 要想登陆新浪微博需要预登陆,即是将账号base64加密,密码rsa加密以及请求http://login.sina.com.cn/sso/prelogin.php链接获取一些登陆需要参数,返回的接送字符串如: {"retcode":0,"servertime":1487292003,"
-
java简单网页抓取的实现方法
本文实例讲述了java简单网页抓取的实现方法.分享给大家供大家参考.具体分析如下: 背景介绍 一 tcp简介 1 tcp 实现网络中点对点的传输 2 传输是通过ports和sockets ports提供了不同类型的传输(例如 http的port是80) 1)sockets可以绑定在特定端口上,并且提供传输功能 2)一个port可以连接多个socket 二 URL简介 URL 是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址. 互联网上的每个文件都有一个唯一的
-
java利用url实现网页内容的抓取
闲来无事,刚学会把git部署到远程服务器,没事做,所以简单做了一个抓取网页信息的小工具,里面的一些数值如果设成参数的话可能扩展性能会更好!希望这是一个好的开始把,也让我对字符串的读取掌握的更加熟练了,值得注意的是JAVA1.8 里面在使用String拼接字符串的时候,会自动把你要拼接的字符串用StringBulider来处理,大大优化了String 的性能,闲话不多说,show my XXX code- 运行效果: 首先打开百度百科,搜索词条,比如"演员",再按F12查看源码 然后抓取
-
java多线程抓取铃声多多官网的铃声数据
一直想练习下java多线程抓取数据. 有天被我发现,铃声多多的官网(http://www.shoujiduoduo.com/main/)有大量的数据. 通过观察他们前端获取铃声数据的ajax http://www.shoujiduoduo.com/ringweb/ringweb.php?type=getlist&listid={类别ID}&page={分页页码} 很容易就能发现通过改变 listId和page就能从服务器获取铃声的json数据, 通过解析json数据, 可以看到都带有{&q
-
java抓取网页数据获取网页中所有的链接实例分享
效果图 复制代码 代码如下: import java.io.BufferedReader;import java.io.IOException;import java.io.InputStreamReader;import java.net.HttpURLConnection;import java.net.URL;import java.util.ArrayList;import java.util.regex.Matcher;import java.util.regex.Pattern; p
-
java在网页上面抓取邮件地址的方法
本文实例讲述了java在网页上面抓取邮件地址的方法.分享给大家供大家参考.具体实现方法如下: 复制代码 代码如下: import java.io.BufferedReader; import java.io.InputStreamReader; import java.net.URL; import java.util.regex.Matcher; import java.util.regex.Pattern; public class h1 { public stati
-
java抓取网页数据示例
下面举例说明: 抓取百度首页的内容: 复制代码 代码如下: URL url = new URL("http://www.baidu.com");HttpURLConnection urlCon=(HttpURLConnection)url.openConnection();urlCon.setConnectTimeout(50000);urlCon.setReadTimeout(300000);DataInputStream fIn;byte[] content = new byte[
-
详解Java实现多种方式的http数据抓取
前言: 时下互联网第一波的浪潮已消逝,随着而来的基于万千数据的物联网时代,因而数据成为企业的重要战略资源之一.基于数据抓取技术,本文介绍了java相关抓取工具,并附上demo源码供感兴趣的朋友测试! 1)JDK自带HTTP连接,获取页面或Json 2) JDK自带URL连接,获取页面或Json 3)HttpClient Get工具,获取页面或Json 4)commons-io工具,获取页面或Json 5) Jsoup工具(通常用于html字段解析),获取页面,非Json返回格式] -------
-
详解Java两种方式简单实现:爬取网页并且保存
对于网络,我一直处于好奇的态度.以前一直想着写个爬虫,但是一拖再拖,懒得实现,感觉这是一个很麻烦的事情,出现个小错误,就要调试很多时间,太浪费时间. 后来一想,既然早早给自己下了保证,就先实现它吧,从简单开始,慢慢增加功能,有时间就实现一个,并且随时优化代码. 下面是我简单实现爬取指定网页,并且保存的简单实现,其实有几种方式可以实现,这里慢慢添加该功能的几种实现方式. UrlConnection爬取实现 package html; import java.io.BufferedReader; i
-
详解Java创建线程的五种常见方式
目录 Java中如何创建线程呢? 1.显示继承Thread,重写run来指定现成的执行代码. 2.匿名内部类继承Thread,重写run来执行线程执行的代码. 3.显示实现Runnable接口,重写run方法. 4.匿名内部类实现Runnable接口,重写run方法 5.通过lambda表达式来描述线程执行的代码 [面试题]:Thread的run和start之间的区别? Thread类的具体用法 Thread类常见的一些属性 中断一个线程 1.方法一:让线程run完 2.方法二:调用interr
-
详解Java中数组判断元素存在几种方式比较
1. 通过将数组转换成List,然后使用List中的contains进行判断其是否存在 public static boolean useList(String[] arr,String containValue){ return Arrays.asList(arr).contains(containValue); } 需要注意的是Arrays.asList这个方法中转换的List并不是java.util.ArrayList而是java.util.Arrays.ArrayList,其中java.
-
详解java代码中init method和destroy method的三种使用方式
在java的实际开发过程中,我们可能常常需要使用到init method和destroy method,比如初始化一个对象(bean)后立即初始化(加载)一些数据,在销毁一个对象之前进行垃圾回收等等. 周末对这两个方法进行了一点学习和整理,倒也不是专门为了这两个方法,而是在巩固spring相关知识的时候提到了,然后感觉自己并不是很熟悉这个,便好好的了解一下. 根据特意的去了解后,发现实际上可以有三种方式来实现init method和destroy method. 要用这两个方法,自然先要知道这两
-
详解Java Callable接口实现多线程的方式
在Java 1.5以前,创建线程的2种方式,一种是直接继承Thread,另外一种就是实现Runnable接口.无论我们以怎样的形式实现多线程,都需要调用Thread类中的start方法去向操作系统请求io,cup等资源.因为线程run方法没有返回值,如果需要获取执行结果,就必须通过共享变量或者使用线程通信的方式来达到效果,这样使用起来就比较麻烦. 而自从Java 1.5开始,就提供了Callable和Future,通过它们可以在任务执行完毕之后得到任务执行结果. Callable和Future介
-
详解java连接mysql数据库的五种方式
第一种方式:将用户名和密码封装在Properties类中 首先,导入数据库连接包这个是毋庸置疑的.创建一个jdbc驱动dirver.将数据库(以MySQL为例)的url保存在所创建的字符串url中.如果mysql版本低于8.0,则url保存形式应该为: String url = "jdbc:mysql://localhost:3306/test" 如果mysql版本为8.0版本或以上,url保存形式为: String url = "jdbc:mysql://localhost
-
详解Java枚举类在生产环境中的使用方式
目录 前言 使用 1.确定业务场景状态 2.定义枚举类 3.自定义查询方法 4.测试效果 总结 前言 Java枚举在项目中使用非常普遍,许多人在做项目时,一定会遇到要维护某些业务场景状态的时候,往往会定义一个常量类,然后添加业务场景相关的状态常量.但实际上,生产环境的项目中业务状态的定义大部分是由枚举类来完成的,因为更加清晰明确,还能自定义不同的方法来获取对应的业务状态值,十分方便. 以下代码均为生产环境已上线项目的代码片段,仅供参考. 使用 大体分为确定业务场景状态.定义枚举类.自定义查询
-
详解Java中的八种单例创建方式
目录 定义 使用场景 单例模式八种方式 饿汉式(静态常量) 饿汉式(静态代码块) 懒汉式(线程不安全) 懒汉式(同步方法) 懒汉式(同步代码块) 双重检查锁方式 静态内部类方式 枚举方式 总结 定义 单例设计模式,就是采取一定的方法保证在整个的软件系统中,对某个类只能存在一个对象实例,并且该类只提供一个取得其对象实例的方法(静态方法) 使用场景 对于一些需要频繁创建销毁的对象 重量级的对象 经常使用到的对象 工具类对象 数据源 session 单例模式八种方式 饿汉式(静态常量) 代码 /**
-
详解Java数组的四种拷贝方式
目录 深拷贝与浅拷贝的区别 1.for循环进行拷贝 拷贝数值类型 拷贝引用类型 2.copyof/copyOfRange 拷贝数值类型 拷贝引用类型 3.arraycopy 拷贝数值类型 拷贝引用类型 4.clone 拷贝数值类型 拷贝引用类型 5.总结 深拷贝与浅拷贝的区别 假设现在有原数组A以及拷贝后的数组B,若是改变A中的某一个值,B数组随之相应的发生变化的拷贝方式称为浅拷贝,反之B数组不受影响,则称为深拷贝:简单总结一下两者的概念: 深拷贝:拷贝后,修改原数组,不会影响到新数组: 浅拷贝