sqlserver中几种典型的等待
为了准备今年的双11很久没有更新blog,在最近的几次sqlserver问题的排查中,总结了sqlserver几种典型的等待类型,类似于oracle中的等待事件,如果看到这样的等待类型时候能够迅速定位问题的根源,下面通过一则案例来把这些典型的等待处理方法整理出来:
第一种等待.memory等待
早上接到一用户反馈其RDS实例非常的慢,通过观察sqlserver活动会话监视器(active monitor)的waiting tasks(类似于mysql的thread running)可以看到有10多w的等待任务,可以明确数据库现在已经出现了较大的瓶颈,紧接着通过resource waits看到数据库中有大量的memory内存等待:

看到是memory 资源等待后,为了立刻恢复用户应用,想到立刻去调大内存,发现该实例已经是24G了,看来一下os的空余内存,还有较多的内存剩余,所以将内存调大到36G,发现resource waits还是在memory上等待,同时这个时候的cpu使用率飙升,达到了90%左右(之前在10%左右的等待).这样解决不了根本问题,于是通过recent expensive queries,发现以下sql的逻辑读很高,执行非常频繁:
SELECT * FROM RefundOrder_Message messages0_ WHERE messages0_.Order_Id=@p0;
也可以通过如下方式获得造成内存等待的sql:
SELECT st.text FROM sys.dm_exec_query_memory_grants req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) as ST where req.grant_time is NULL or req.granted_memory_kb is NULL
The columns grant_time and granted_memory_kb will be NULL for those queries which are waiting to get their requested memory
sp_helpindex RefundOrder_Message
发现该表只有一个主键索引:

创建一下索引:
create index ind_RefundOrder_Message_order_id on RefundOrder_Message(Order_Id);

第二种等待:latch等待
在索引加上去后,memory的等待立刻消失,但是resource waits的等待变为了 lock:

通过以下内部视图可以发现如下调用出现了等待:
SELECT ss.host_name, req.blocking_session_id,req.wait_type ,req.wait_time ,req.wait_resource ,req.transaction_id ,st.text FROM sys.dm_exec_requests req CROSS APPLY sys.dm_exec_sql_text(req.sql_handle) as ST
cross apply sys.dm_exec_sessions ss where req.status =N'suspended' and ss.session_id=req.session_id;
得到阻塞其他会话的sql:
(@p0 int,@p1 nvarchar(4000),@p2 bit)
SELECT TOP (@p0) this.* FROM ViewSalesOrder this_ WHERE this_.MemberCode = @p1 and this_.IsObsolete = @p2 ORDER BY this_.OdCode desc;
视图ViewSalesOrder是一张非常核心的视图,里面关联了订单,订单消息,订单发货等多个业务逻辑;查询条件中代入了membercode为店铺的名称,可能操作某个店铺的订单;
通过ViewSalesOrder视图中的定义,membercode,IsObsolete ,OdCode 为salesOrder表的三个字段,查看salesOrder上并没有相应的索引,于是加上如下索引:
create index ind_salesOrder_member on salesOrder(membercode,IsObsolete,code);
在添加完索引后,数据库的waiting tasks 下降,batch requests提升:
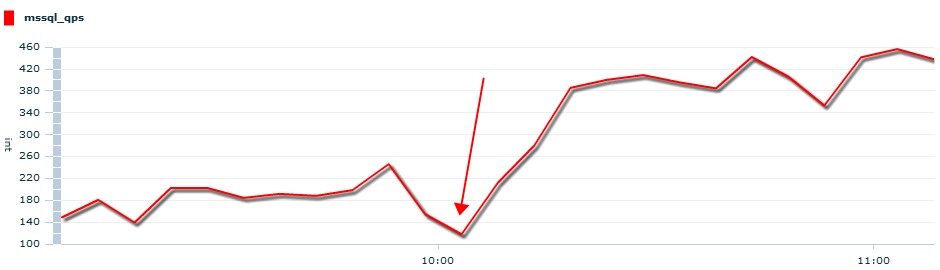
第三种等待:lock
第三种等待是常见的等待,常见的情况在删除,更新的时候由于条件中没有合适的索引导致锁定的记录范围太大,导致阻塞其他的会话请求:
用户在在进行压测的时候发现一条更新语句执行的非常慢,导致整个系统都卡住:

update DD_ShenHe set ZF = 0 where zf is null;
查看dd_shenhe表上面的索引:
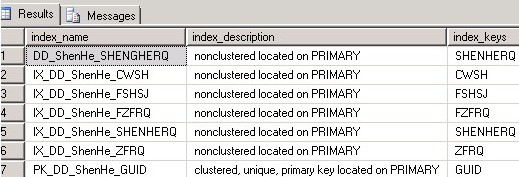
可以看到表中并没有zf字段的索引,而该表总共有400w的数据,zf 为null的有8000条,所以在zf字段添加索引是合适的:
Create index ind_dd_shenhe_zf on dd_shenhe(zf);
添加完索引后,系统恢复正常。
相关推荐
-

SqlServer中如何解决session阻塞问题
简介 对于数据库运维人员来说创建session或者查询时产生问题是常规情况,下面介绍一种很有效且不借助第三方工具的方式来解决类似问题. 最近开始接触运维工作,所以自己总结一些方案便于不懂数据库的同事解决一些不太紧要的数据库问题.类似方法很多理论也很多,我就不做深究,就是简单写一个方案,便于菜鸟使用的. 阻塞理解 在Sql Server 中当一个数据库会话中的事务正锁定一个或多个其他会话事务想要读取或修改的资源时,会产生阻塞(Blocking).通常短时间的阻塞没有问题,且是较忙的应用程序所需要的
-
系统隐形杀手——阻塞与等待(SQL)
前言 应用系统承载着大量的业务,随之而来的是复杂的业务逻辑,在数据库上的表现就是有着大量的不同种类的SQL语句. SQL语句执行的快慢又与阻塞等待有着密不可分的原因. 系统慢可能有很多种原因,硬件资源不足,语句不优化,结构设计不合理,缺少必要的运维方式.所有的这些问题都可以在阻塞与等待中看出端倪,发现并解决问题. 今天这篇我们主要讲述怎么样发现并解决系统的阻塞和等待. 场景描述 您的系统是否有这样的问题? 系统运行缓慢,很多功能需要几十秒才能呈现结果,用户体验极差,领导们不断施压,作为系统的负责
-
SQL2008中SQL应用之-阻塞(Blocking)应用分析
通常短时间的阻塞没有问题,且是较忙的应用程序所需要的.然而,设计糟糕的应用程序会导致长时间的阻塞,这就不必要地锁定了资源,而且阻塞了其他会话读取和更新它们. 在SQL Server中,一个阻塞的进程会无限期地保持阻塞,或者直到它超时(根据set lock_timeout).服务器关闭.进程被杀死.连接完成了更新或者其他发生在原始事务上的操作导致它释放了资源上的锁. 发生长时间阻塞的原因如下: 1.在一个没有索引的表上的过量的行锁会导致SQL Server得到一个锁,从而阻塞其他事务. 2.应用程
-
SQL语句练习实例之三——平均销售等待时间
复制代码 代码如下: ---1.平均销售等待时间 ---有一张Sales表,其中有销售日期与顾客两列,现在要求使用一条SQL语句实现计算 --每个顾客的两次购买之间的平均天数 --假设:在同一个人在一天中不会购买两次 create table sales ( custname varchar(10) not null, saledate datetime not null ) go insert sales select '张三','2010-1-1' union select '张三','20
-
sql server 2000阻塞和死锁问题的查看与解决方法
数据库发生阻塞和死锁的现象: 一.数据库阻塞的现象:第一个连接占有资源没有释放,而第二个连接需要获取这个资源.如果第一个连接没有提交或者回滚,第二个连接会一直等待下去,直到第一个连接释放该资源为止.对于阻塞,数据库无法处理,所以对数据库操作要及时地提交或者回滚.二.数据库死锁的现象:第一个连接占有资源没有释放,准备获取第二个连接所占用的资源,而第二个连接占有资源没有释放,准备获取第一个连接所占用的资源.这种互相占有对方需要获取的资源的现象叫做死锁.对于死锁,数据库处理方法:牺牲一个连接,保证另外
-
mysql的udf编程之非阻塞超时重传
MySQL的UDF(User Defined Function)类似于一种API, 用户根据一定的规范用C/C++(或采用C调用规范的语言)编写一组函数(UDF),然后编译成动态链接库,通过DROP FUNCTION语句来加载和卸载UDF.UDF被加载后可以像调用MySQL的内置函数一样来调用它,并且服务器在启动时会自动加载原来存在的UDF. 复制代码 代码如下: #ifdef STANDARD/* STANDARD is defined, don't use any mysql functio
-
利用sys.sysprocesses检查SqlServer的阻塞和死锁
MSDN:包含正在 SQL Server 实例上运行的进程的相关信息.这些进程可以是客户端进程或系统进程. 视图中主要的字段: 1. Spid:Sql Servr 会话ID 2. Kpid:Windows 线程ID 3. Blocked:正在阻塞求情的会话 ID.如果此列为 Null,则标识请求未被阻塞 4. Waittype:当前连接的等待资源编号,标示是否等待资源,0 或 Null表示不需要等待任何资源 5. Waittime:当前等待时间,单位为毫秒,0 表示没有等待 6. DBID:当前
-
SQL语句实现查询当前数据库IO等待状况
sys.dm_io_pending_io_requests可以返回当前IO Pending的状态,对于SQL Server 中每个挂起的I/O 请求,返回与其对应的一行,跟sys.dm_io_virtual_file_stats配合可以看到具体是哪个数据库IO出现问题. select DB_NAME(database_id) as DBNAME, database_id, file_id, io_stall, io_pending_ms_ticks, scheduler_address from
-
SQL Server误区30日谈 第2天 DBCC CHECKDB会导致阻塞
误区 #2: DBCC CHECKDB会引起阻塞,因为这个命令默认会加锁 这是错误的! 在SQL Server 7.0以及之前的版本中,DBCC CHECKDB命令的本质是C语言实现的一个不断嵌套循环的代码并对表加表锁(循环嵌套算法时间复杂度是嵌套次数的N次方,作为程序员的你懂得),这种方式并不和谐,并且-.. 在SQL Server 2000时代,一个叫Steve Lindell的哥们(现在仍然在SQL Server Team)使用分析事务日志的方法来检查数据库的一致性的方式重写了DBCC C
-
sqlserver中几种典型的等待
为了准备今年的双11很久没有更新blog,在最近的几次sqlserver问题的排查中,总结了sqlserver几种典型的等待类型,类似于oracle中的等待事件,如果看到这样的等待类型时候能够迅速定位问题的根源,下面通过一则案例来把这些典型的等待处理方法整理出来: 第一种等待.memory等待 早上接到一用户反馈其RDS实例非常的慢,通过观察sqlserver活动会话监视器(active monitor)的waiting tasks(类似于mysql的thread running)可以看到有10
-
浅谈c语言中一种典型的排列组合算法
c语言中的全排列算法和组合数算法在实际问题中应用非常之广,但算法有许许多多,而我个人认为方法不必记太多,最好只记熟一种即可,一招鲜亦可吃遍天 全排列: #include<stdio.h> void swap(int *p1,int *p2) { int t=*p1; *p1=*p2; *p2=t; } void permutation(int a[],int index,int size) { if(index==size) { for(int i=0;i<size;i++) print
-
SQLServer中使用扩展事件获取Session级别的等待信息及SQLServer 2016中Session级别等待信息的增强
什么是等待 简单说明一下什么是等待: 当应用程序对SQL Server发起一个Session请求的时候,这个Session请求在数据库中执行的过程中会申请其所需要的资源, 比如可能会申请内存资源,表上的锁资源,物理IO资源,网络资源等等, 如果当前Session运行过程中需要申请的某些资源无法立即得到满足,就会产生等待. SQL Server会以不用的方式来展现这个等待信息,比活动Session的等待信息,实例级的等待信息等等. SQL Server中,等待事件是作为DBA进行TroubleSh
-
C#批量插入数据到Sqlserver中的三种方式
本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记录的ID的值然后再进行加1运算要少.而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的.如果表中无可避免的存在索引,我们可以通过先删除索引,然后批量插入,最后再重建索引的方式来提高效率. create database C
-
详解C#批量插入数据到Sqlserver中的四种方式
本篇,我将来讲解一下在Sqlserver中批量插入数据. 先创建一个用来测试的数据库和表,为了让插入数据更快,表中主键采用的是GUID,表中没有创建任何索引.GUID必然是比自增长要快的,因为你生成一个GUID算法所花的时间肯定比你从数据表中重新查询上一条记录的ID的值然后再进行加1运算要少.而如果存在索引的情况下,每次插入记录都会进行索引重建,这是非常耗性能的.如果表中无可避免的存在索引,我们可以通过先删除索引,然后批量插入,最后再重建索引的方式来提高效率. create database C
-
python中3种等待元素出现的方法总结
目录 前言 一.强制等待 二.隐性等待 三.显性等待 总结 前言 在做web或app的自动化测试经过会出现找不到元素而报错的情况,很多时候是因为元素 还没有被加载出来,查找的代码就已经被执行了,自然就找不到元素了.那么我可以用等待 元素加载完成后再执行查找元素的code. Python里有三种等待的方式: 一.强制等待 Sleep(54) 这个方法在time模块,使用时通过from time import sleep导入 比如: Sleep(10) #表示强行等待10s再执行下一句代码 Driv
-
SQLServer中防止并发插入重复数据的方法详解
SQLServer中防止并发插入重复数据,大致有以下几种方法: 1.使用Primary Key,Unique Key等在数据库层面让重复数据无法插入. 2.插入时使用条件 insert into Table(****) select **** where not exists(select 1 from Table where ****); 3.使用SERIALIZABLE隔离级别,并且使用updlock或者xlock锁提示(等效于在默认隔离级别下使用(updlock,holdlock)或(xl
-
Oracle中常见的33个等待事件小结
一. 等待事件的相关知识 1.1 等待事件主要可以分为两类,即空闲(IDLE)等待事件和非空闲(NON-IDLE)等待事件.1). 空闲等待事件指ORACLE正等待某种工作,在诊断和优化数据库的时候,不用过多注意这部分事件.2). 非空闲等待事件专门针对ORACLE的活动,指数据库任务或应用运行过程中发生的等待,这些等待事件 是在调整数据库的时候需要关注与研究的. 在Oracle 10g中的等待事件有872个,11g中等待事件1116个. 我们可以通过v$event_name 视图来查看等待事件
-
Python 中 -m 的典型用法、原理解析与发展演变
在命令行中使用 Python 时,它可以接收大约 20 个选项(option),语法格式如下: python [-bBdEhiIOqsSuvVWx?] [-c command | -m module-name | script | - ] [args] 本文想要聊聊比较特殊的"-m"选项: 关于它的典型用法.原理解析与发展演变的过程. 首先,让我们用"--help"来看看它的解释: -m mod run library module as a script (ter