Redis主从复制分步讲解使用
主服务器(master)启用二进制日志 选择一个唯一的server-id 创建具有复制权限的用户
从服务器(slave)启用中继日志, 选择一个唯一的server-id 连接至主服务器,并开始复制
主库ip:192.168.235.130 端口:3306 从库ip:192.168.235.139 端口:3306
主库配置
(1)设置server-id值并开启binlog参数
[mysqld]
log_bin = mysql-bin
server_id = 130
重启数据库
(2)建立同步账号
creat user 'rep1'@'192.168.10.139' identified with mysql_native_password by 'Test@1234'#设置账户密码
grant replication slave on *.* to 'rep1'@'192.168.235.139';
grant replication slave on *.* to 'rep1'@'192.168.235.139';
show grants for 'rep1'@'192.168.235.139';
(3)锁表设置只读
为后面备份准备,注意生产环境要提前申请停机时间;
mysql> flush tables with read lock;
提示:如果超过设置时间不操作会自动解锁。
mysql> show variables like '%timeout%';
测试锁表后是否可以创建数据库
4)查看主库状态 查看主库状态,即当前日志文件名和二进制日志偏移量
mysql> show master status;
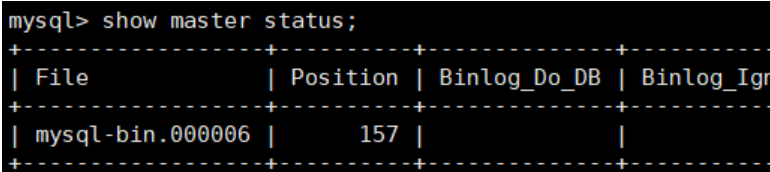
记住file和position,方便slave后续连接。
(5)备份数据库数据
mysqldump -uroot -p -A -B |gzip > mysql_bak.$(date +%F).sql.gz
(6)解锁
mysql> unlock tables;
(7)主库备份数据上传到从库
scp /server/backup/mysql_bak.2022-09-22.sql.gz 192.168.235.139:/root/hh
从库上设置
(1)设置server-id值并关闭binlog参数
#log_bin = /data/mysql/data/mysql-bin
server_id = 139
重启数据库
(2)还原从主库备份数据
cd /server/backup/ gzip -d mysql_bak.2022-09-22.sql.gz mysql -uroot -p < mysql_bak.2022-09-22.sql
检查还原:
mysql -uroot -p -e 'show databases;'
(3)设定从主库同步
mysql> change master to
-> master_host='192.168.235.130',
-> master_port=3306,
-> master_user='rep1',
-> master_password='Test@1234',
-> master_log_file='mysql-bin.000006',
-> master_log_pos=157;
(4)启动从库同步开关
mysql> start slave;
检查状态:
mysql> show slave status\G
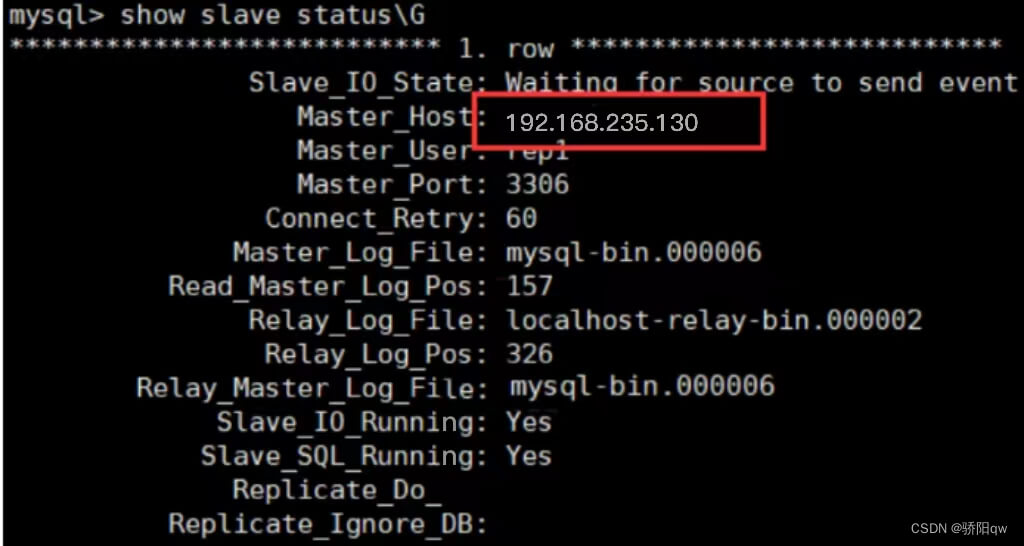
主备复制功能达成。
下面进行测试:
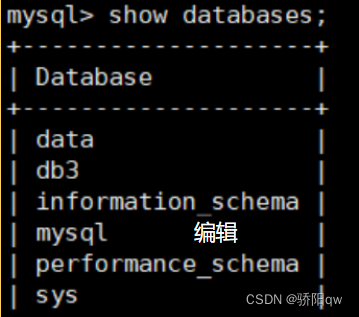
在192.168.235.130(主)上执行:
create databses data; 新建数据库

从虚拟机上也建好了data文件,实现了Mysql的主从复制。
到此这篇关于Redis主从复制分步讲解使用的文章就介绍到这了,更多相关Redis主从复制内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Redis之windows下主从复制案例讲解
一般的主从复制功能最少是一主二从,我这里就以最低要求进行配置. 1.首先下去官网下载并安装redis 若安装成功点击redis-server 如此是成功 2.点击客户端redis-cli 连接客户端即可使用 3.新建7000.7001两个从redis 4.修改redis-windows.conf (1)把端口修改成7000 (2)修改cluster-config-file的名字 以免和6379端口的名字重复其他配置默认即可,我个人认为我们都重新建了一个文件夹也不可能出现和6379重复的错
-
Redis主从复制操作和配置详情
目录 前言 一.Redis-server环境变量 二.配置集群的Redis.conf 三.配置主从服务器 四.启动三台Redis服务器 前言 环境:CentOS7下安装Redis集群,默认已安装好5.0及以上版本,操作包括: Redis-server环境变量 配置配置集群的 Redis.confRedis主从配置和启动 测试主从机的数据一致性和读写分离 一.Redis-server环境变量 启动redis服务报错: -bash: redis-server: command not found 原
-
Redis实现主从复制方式(Master&Slave)
目录 主从复制方式(Master&Slave) 一.Master&Slave是什么? 二.它能干嘛? 三.怎么玩? 四.复制原理 五.哨兵模式(sentinel) 六.复制的缺点 Redis master, slave节点部署详解 主从复制方式(Master&Slave) 由于前段时间公司项目比较赶,一直抽不出时间写博客,今天偷空写一篇吧.前面给大家讲解了单机版redis的基本操作,现在继续给大家讲解一下Redis的进阶部分,主从复制和读写分离. 一.Master&Slav
-
关于Redis的主从复制及哨兵问题
目录 服务器配置 主从复制 哨兵 服务器配置 到这里关于redis的一些基本操作就学习完了,接下来我们就来看看redis中更加高级的部分,首先是配置文件中的配置信息. 配置项 说明 daemonize yes no bind 127.0.0.1 绑定主机地址 port 6379 设置服务器端口号 databases 16 设置数据库数量 loglevel debug verbose logfile 端口号.log 设置日志文件名 maxclients 0 设置同一时间最大客户端连接数,默认无限制
-
Redis持久化与主从复制的实践
为什么需要持久化 Redis是基于内存的NoSQL数据库,读写速度自然快,但内存是瞬时的,在redis服务关闭或重启之后,redis存放在内存的数据就会丢失,为了解决这个问题,redis提供了两种持久化方式,以便在发生故障后恢复数据. 持久化选项 redis提供了两种不同的持久化方式来将数据存储到硬盘中.一种是快照方式(也叫RDB方式),它可以将莫一时刻存在于redis中的所有数据存储到硬盘:另一种叫只追加文件(AOF)方式,它会定时的复制redis执行的所有写命令到硬盘.这两种持久化方式各有千
-
Redis超详细讲解高可用主从复制基础与哨兵模式方案
目录 高可用基础---主从复制 主从复制的原理 主从复制配置 示例 1.创建Redis实例 2.连接数据库并设置主从复制 高可用方案---哨兵模式sentinel 哨兵模式简介 哨兵工作原理 哨兵故障修复原理 sentinel.conf配置讲解 哨兵模式的优点 哨兵模式的缺点 高可用基础---主从复制 Redis的复制功能是支持将多个数据库之间进行数据同步,主数据库可以进行读写操作.当主数据库数据发生改变时会自动同步到从数据库,从数据库一般是只读的,会接收注数据库同步过来的数据. 一个主数据库可
-
详解Redis主从复制实践
复制简介 Redis 作为一门非关系型数据库,其复制功能和关系型数据库(MySQL)来说,功能其实都是差不多,无外乎就是实现的原理不同.Redis 的复制功能也是相对于其他的内存性数据库(memcached)所具备特有的功能. Redis 复制功能主要的作用,是集群.分片功能实现的基础:同时也是 Redis 实现高可用的一种策略,例如解决单机并发问题.数据安全性等等问题. 服务介绍 在本文环境演示中,有一台主机,启动了两个 Redis 示例. 实现方式 Redis 复制实现方式分为下面三种方式:
-
浅谈Redis主从复制以及主从复制原理
面临问题 1. 机器故障.我们部署到一台 Redis 服务器,当发生机器故障时,需要迁移到另外一台服务器并且要保证数据是同步的.而数据是最重要的,如果你不在乎,基本上也就不会使用 Redis 了. 2. 容量瓶颈.当我们有需求需要扩容 Redis 内存时,从 16G 的内存升到 64G,单机肯定是满足不了.当然,你可以重新买个 128G 的新机器. 解决办法 要实现分布式数据库的更大的存储容量和承受高并发访问量,我们会将原来集中式数据库的数据分别存储到其他多个网络节点上.Redis 为了解决这个
-
Redis主从复制分步讲解使用
主服务器(master)启用二进制日志 选择一个唯一的server-id 创建具有复制权限的用户 从服务器(slave)启用中继日志, 选择一个唯一的server-id 连接至主服务器,并开始复制 主库ip:192.168.235.130 端口:3306 从库ip:192.168.235.139 端口:3306 主库配置 (1)设置server-id值并开启binlog参数 [mysqld]log_bin = mysql-binserver_id = 130 重启数据库 (2)建立同步账号 cr
-
redis主从复制原理的深入讲解
前言 Redis持久化保证了即使redis服务重启也不会丢失数据,因为redis服务重启后会将硬盘上持久化的数据恢复到内存中,但是当redis服务器的硬盘损坏了可能会导致数据丢失,如果通过redis的主从复制机制就可以避免这种单点故障. 本文主要针对redis主从复制的原理进行了讲解,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 1.复制过程 2.数据间的同步 3.全量复制 4.部分复制 5.心跳 6.异步复制 1.复制过程 从节点执行 slaveof 命令. 从节点只是保存了
-
Redis配置文件代码讲解
Redis配置文件解析网上都有,这里不赘述了.提供一些值得修改的参数,标注红色的参数尤其需要注意,不然容易出现主从全量同步死循环 NETWORK bind 127.0.0.1 默认是bind 127.0.0.1,注释掉 protected-mode no 默认protected-mode yes,改为no port 6379 建议修改掉,避免使用默认端口 tcp-backlog 511 建议调大至2048并同时调大Linux内核参数 /proc/sys/net/core/somaxconn 至2
-
Redis主从复制详解
单机Redis存在的问题 无法故障转移 ,无法避免单点故障 磁盘空间的瓶颈 QPS瓶颈 Redis主从复制的作用 提供数据副本 扩展读性能 配置方法 通过命令 通过配置文件 演示 为方便演示,在一台服务器上搭建redis主从(生产上不会这样做),根据端口区分. 主库 6379 从库 6380 编辑配置文件 vi redis-6379.conf #后台进程启动 daemonize yes #端口 port 6379 #日志文件名称 logfile "6379.log" #Redis工作
-
使用Docker搭建Redis主从复制的集群
在主从复制模式的集群里,主节点一般是一个,从节点一般是两个或多个,写入主节点的数据会被复制到从节点上,这样一旦主节点出现故障,应用系统能切换到从节点去读写数据,这样能提升系统的可用性.而且如果再采用主从复制模式里默认的读写分离的机制,更能提升系统的缓存读写性能.所以对性能和实时性不高的系统而言,主从复制模式足以满足一般的性能和安全性方面的需求. 1 概述主从复制模式 在实际应用中,如果有相应的设置,在向一台Redis服务器里写数据后,这个数据可以复制到另外一台(或多台)Redis服务器,这里数据
-
laravel使用redis队列实例讲解
1.队列配置文件是config/queue.php(这里我默认配置即可): 2. 创建迁移表(failed-table .jobs.migrations) php artisan queue:table php artisan queue:failed-table php artisan migrate ps:出现下面错误,修改对应表名即可 ps:出现下面红色错误,修改如下图string(字段,长度(随便填)) 3.创建任务 1)生成任务类: 通常,所有的任务类都保存在 app/Jobs 目录.
-
java、spring、springboot中整合Redis的详细讲解
java整合Redis 1.引入依赖或者导入jar包 <dependency> <groupId>redis.clients</groupId> <artifactId>jedis</artifactId> <version>2.9.0</version> </dependency> 2.代码实现 public class JedisTest { public static void main(String[]