Python模块域名dnspython解析
目录
- dnspython源码安装
- python模块域名解析方法讲解
- 总结
dnspython是python实现的一个DNS工具包,它支持记录类型、查询、传输并动态更新ZONE信息等等。据说dnspython可以代替dig、nslookup等工具。下面我们就来介绍dnspython模块的使用。
dnspython源码安装
这里介绍一下dnspython模块的安装,采用源码的安装方式,目前使用的版本是1.16.0

如下安装:
wget https://www.dnspython.org/kits/1.16.0/dnspython-1.16.0.tar.gz

tar -zxvf dnspython-1.16.0.tar.gz

cd dnspython-1.16.0 python setup.py install
看到红框的信息说明安装完成了。

好了,开始进入今天的正题,python模块的讲解。
python模块域名解析方法讲解
平常测试DNS的时候,有些操作手动处理不方便,需要写个脚本来实现,这是就会想到使用dnspython模块,它提供了大量的DNS处理方法,我们知道最常用的方法就是域名查询,dnspyhton库提供一个解析器类(resolver),我们可以使用它query方法实现域名查询功能。这里要说一下query:
query(self, qname, rdtype = 1, rdclass = 1, tcp = False, source = None, raise_on_no_answer = True, source_port = 0)
qname:查询的域名。
rdtype :指定RR资源的类型
全部的rdtype类型为:

常用的有以下几种:
A记录:将主机名转换成IP地址
MX记录:邮件交换记录,定义邮件服务器的域名
CNAME记录:别名记录,实现域名间的映射
NS记录:标记区域的域名服务器及授权子域
PTR记录:反向解析,与A记录相反,将IP地址转换为主机名
SOA记录:SOA标记,一个起始授权区的定义
rdclass: 指定网络类型,可选的值为CH、IN。其中IN为默认的,使用最广泛。

tcp :指定查询是否启动TCP协议,默认不启动。
source与source_port:指定的查询源地址与端口。
raise_on_no_answer :指定查询无应答时是否触发异常,默认为True。
下面我们开始对常见解析类型进行说明。
解析类型说明
A记录
#!/usr/local/bin/python38
# -*- coding: utf-8 -*-
import dns.resolver
domain = input('Please input an domain: ') #输入域名地址
A = dns.resolver.query(domain, 'A') #查询记录为A记录
for i in A.response.answer:
for j in i.items:
if j.rdtype == 1: #加判断,不然会出现AttributeError: 'CNAME' object has no attribute 'address'
print(j.address)
运行代码查看结果,这里以www.baidu.com域名为例:

这样子我们就将www.baidu.com的域名解析出来了。 来看看效果:

MZ记录
#!/usr/local/bin/python38
# -*- coding: utf-8 -*-
import dns.resolver
domain = input('Input an domain : ')
MX = dns.resolver.query(domain, 'MX') # 指定解析类型为MX记录
for i in MX: # 遍历回应结果
print('MX preference =', i.preference, 'mail exchanger =', i.exchange)
运行代码查看结果,这里以qq.com域名为例:

其中我们可以看到preference值(优先级)和exchange值(交换地址),其中优先级默认为10,MX记录可以通过设置优先级实现主辅服务器设置,”优先级”中的数字越小表示级别越高,“优先级”仅对MX记录有效。
NS记录
NS(Name Server)域名服务器记录。用来表明由哪台服务器对该域名进行解析。在注册域名时,总有默认的DNS服务器,每个注册的域名都是由一个DNS域名服务器来进行解析的。
下面实现NS记录查询方法:
#!/usr/local/bin/python38
import dns.resolver
domain = input('Input an domain : ')
NS = dns.resolver.query(domain, 'NS')
for i in NS.response.answer:
for j in i.items:
print(j.to_text())
运行结果如下:

只限输入一级域名,如baidu.com。如果输入二级或多级域名,如:www.baidu.com,则是错误的,我们可以试一下,验证问题:
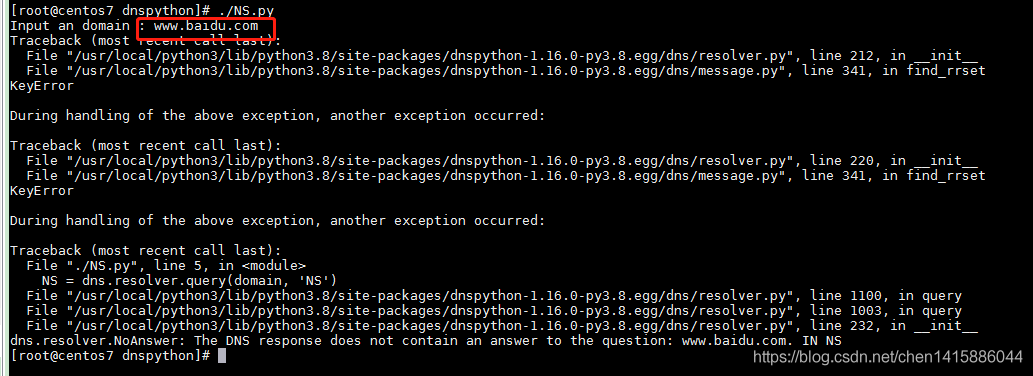
CNAME记录
使用CNAME时,CNAME的目标主机地址只能使用主机名,不能使用IP地址。主机名前不能有任何其他前缀,如:http://等是不被允许的。
来看看下面代码实现CNAME记录方法:
#!/usr/local/bin/python38
import dns.resolver
domain = input('Input an domain: ')
CNAME = dns.resolver.query(domain,'CNAME')
for i in CNAME.response.answer:
for j in i.items:
print(j.to_text())
运行结果如下:

运行结果出现www.a.shifen.com域名,这个域名就是www.baidu.com的别名指向。相当于用子域名来代替ip地址,优点是如果ip地址变化,只需要改动子域名的解析,而不需要逐一改变ip地址解析。
DNS域名轮询业务监控
大部分的DNS解析器都是一个域名对应一个IP地址,但是通过DNS轮询技术可以做到一个域名对应多个IP,从而实现最简单高效的负载平衡,不过此方最大的弊端是目标主机不可用时无法被自动剔除,因此做好业务主机的服务可用监控至关重要。
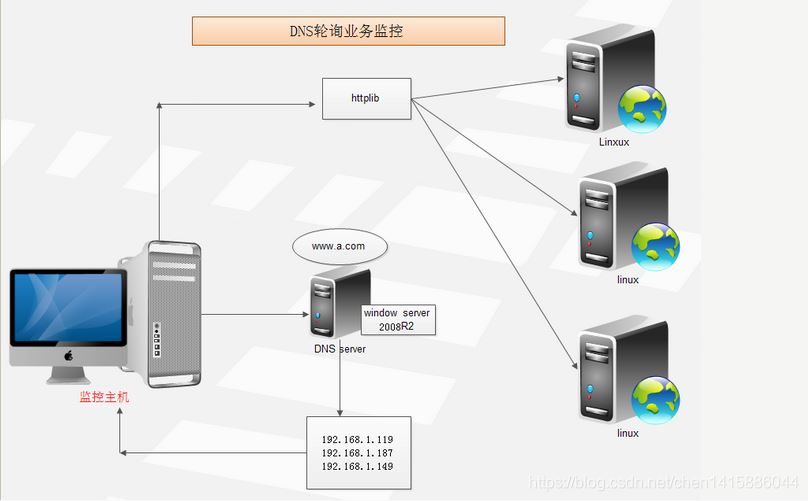
下面我们来实现域名的解析,获取域名的所有A记录解析IP列表。
#!/usr/local/bin/python38
import dns.resolver
import httplib2
iplist = []
appdomain = "www.baidu.com"
def get_iplist(domain=""):
try:
A = dns.resolver.query(domain,"A")
except Exception as e:
print("dns resolver error:" + str(e))
return
for i in A.response.answer:
for j in i.items:
if j.rdtype == 1:
iplist.append(j.address)
return True
def checkip(ip):
checkurl = 'http://' + ip + ":80"
getcontent = ""
httplib2.socket.setdefaulttimeout(5)
conn = httplib2.Http()
try:
resp,getcontent=conn.request(checkurl)
finally:
if resp['status']== "200":
print(ip+"[OK]")
else:
print(ip+"[Error]")
if __name__ == "__main__":
if get_iplist(appdomain) and len(iplist) > 0:
for ip in iplist:
checkip(ip)
运行结果如下:

从结果可以看出,域名www.baidu.com解析出3个IP地址,并且服务都是正常的。上面的代码,第一步通过dns.resolver.query()方法获取业务域名A记录信息,查询出所有IP地址列表,再使用httplib模块的request()方法以GET方式请求监控页面,监控业务所有服务的IP是否服务正常。
总结
我们知道将IP地址转换为可读格式或单词后,便称为域名。在python中,域名到IP地址的转换由python模块dnspython管理。它支持记录类型、查询、传输并动态更新ZONE信息的方法。感兴趣的朋友,可以去看看dnspython源码。
到此这篇关于Python模块域名dnspython解析 的文章就介绍到这了,更多相关Python模块域名dnspython内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python中使用scapy模拟数据包实现arp攻击、dns放大攻击例子
scapy是python写的一个功能强大的交互式数据包处理程序,可用来发送.嗅探.解析和伪造网络数据包,常常被用到网络攻击和测试中. 这里就直接用python的scapy搞. 这里是arp的攻击方式,你可以做成arp攻击. 复制代码 代码如下: #!/usr/bin/python """ ARP attack """ import sys, os from scapy.all import * if os.geteuid() != 0:
-
python批量处理多DNS多域名的nslookup解析实现
利用EXCLE生成CSV文档,批量处理nslookup解析.并保存为CSV文档,方便进行查看: 输入文档格式: data\domain.csv 最终输出文档情况: data\nlookup.csv 代码: # coding=gbk import subprocess import csv def get_nslookup(domain, dns): res = subprocess.Popen("nslookup {0} {1}".format(domain, dns), stdin=
-
python实现DNS正向查询、反向查询的例子
1.DNS查询过程: 以查询 www.baidu.com为例 (1)电脑向本地域名服务器发送解析www.baidu.com的请求(2)本地域名服务器收到请求后,先查询本地的缓存,如果找到直接返回查询结果,如果没有该记录,本地域名服务器把www.baidu.com的请求发送给根域名服务器(3)根域名服务器收到请求后,把.com域的服务器IP地址返回给本地域名服务器(4)本地域名服务器连接.com服务器,向其请求解析域名www.baidu.com, .com服务器把baidu.com服务器的IP地址
-
Python实现的简单dns查询功能示例
本文实例讲述了Python实现的简单dns查询功能.分享给大家供大家参考,具体如下: #!/usr/bin/python import sys,socket def print_array(*arr): array = arr for item in array: print item[4][0] print '''this script is for host resolve print "now this begin... if you want to leave,please input
-
Python爬虫DNS解析缓存方法实例分析
本文实例讲述了Python爬虫DNS解析缓存方法.分享给大家供大家参考,具体如下: 前言: 这是Python爬虫中DNS解析缓存模块中的核心代码,是去年的代码了,现在放出来 有兴趣的可以看一下. 一般一个域名的DNS解析时间在10~60毫秒之间,这看起来是微不足道,但是对于大型一点的爬虫而言这就不容忽视了.例如我们要爬新浪微博,同个域名下的请求有1千万(这已经不算多的了),那么耗时在10~60万秒之间,一天才86400秒.也就是说单DNS解析这一项就用了好几天时间,此时加上DNS解析缓存,效果就
-

Python DNS查询放大攻击实现原理解析
查询放大攻击的原理是,通过网络中存在的DNS服务器资源,对目标主机发起的拒绝服务攻击,其原理是伪造源地址为被攻击目标的地址,向DNS递归服务器发起查询请求,此时由于源IP是伪造的,固在DNS服务器回包的时候,会默认回给伪造的IP地址,从而使DNS服务成为了流量放大和攻击的实施者,通过查询大量的DNS服务器,从而实现反弹大量的查询流量,导致目标主机查询带宽被塞满,实现DDOS的目的. 此时我们使用scapy工具构建一个DNS请求数据包 sr1(IP(dst="8.8.8.8")/UDP(
-
python实现域名系统(DNS)正向查询的方法
本文实例讲述了python实现域名系统(DNS)正向查询的方法.分享给大家供大家参考,具体如下: 域名系统(DNS)是一个分布式的数据库,主要是用来把主机名换成IP地址. DNS存在有两大理由: (1)可以使用户方便记住名字,而不是纯粹的IP地址: (2)允许服务器改变IP地址,但可以使用原来的域名. 系统中最基本的查询为正向查询,它会根据一个主机名来查找IP地址.例如如果你想从www.example.com上下载一个web页面,首先要寻找到IP地址.正想查询会帮你完成这个任务,它会把一个名字翻
-
利用Python+阿里云实现DDNS动态域名解析的方法
引子 我想大家应该都很熟悉DNS了,这回在DNS前面加了一个D又变成了什么呢?这个D就是Dynamic(动态),也就是说,按照传统,一个域名所对应的IP地址应该是定死的,而使用了DDNS后,域名所对应的IP是可以动态变化的.那这个有什么用呢? 比如,在家里的路由器上连着一个raspberry pi(树莓派),上面跑着几个网站,我应该如和在外网环境下访问网站.登陆树莓派的SSH呢? 还有,家里的NAS(全称Network Attach Storage 网络附属存储,可以理解为私有的百度网盘)上存储
-
Python写的一个简单DNS服务器实例
因为突然有个邪恶的想法,想在自己的Android平板上面搭建一个DNS服务器,因为平板上之前安装过SL4A和Python的解释器,也想继续学学Python因此,就打算用Python实现了. 在Google上面找了一下,Python实现的DNS,没找到我所希望的答案,因此就决定自己来实现了. 现在所实现的没什么高深的,只是能够对A记录查询进行简单的匹配和回复. 实现的代码如下: 复制代码 代码如下: '''Created on 2012-10-15 @author: RobinTang''' im
-
Python模块域名dnspython解析
目录 dnspython源码安装 python模块域名解析方法讲解 总结 dnspython是python实现的一个DNS工具包,它支持记录类型.查询.传输并动态更新ZONE信息等等.据说dnspython可以代替dig.nslookup等工具.下面我们就来介绍dnspython模块的使用. dnspython源码安装 这里介绍一下dnspython模块的安装,采用源码的安装方式,目前使用的版本是1.16.0 如下安装: wget https://www.dnspython.org/kits/1
-
python 解析XML python模块xml.dom解析xml实例代码
一 .python模块 xml.dom 解析XML的APIminidom.parse(filename)加载读取XML文件 doc.documentElement获取XML文档对象 node.getAttribute(AttributeName)获取XML节点属性值 node.getElementsByTagName(TagName)获取XML节点对象集合 node.childNodes #返回子节点列表. node.childNodes[index].nodeValue获取XML节点值 nod
-
Python实现XML文件解析的示例代码
1. XML简介 XML(eXtensible Markup Language)指可扩展标记语言,被设计用来传输和存储数据,已经日趋成为当前许多新生技术的核心,在不同的领域都有着不同的应用.它是web发展到一定阶段的必然产物,既具有SGML的核心特征,又有着HTML的简单特性,还具有明确和结构良好等许多新的特性. test.XML文件 <?xml version="1.0" encoding="utf-8"?> <catalog> <m
-
Python argparse模块应用实例解析
这篇文章主要介绍了Python argparse模块应用实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 简介 argparse是python用于解析命令行参数和选项的标准模块.argparse模块的作用是用于解析命令行参数. 使用步骤 1.首先导入该模块 2.然后创建一个解析对象 3.然后向该对象中添加你要关注的命令行参数和选项,每一个add_argument方法对应一个你要关注的参数或选项 4.最后调用parse_args()方法进行
-
Python hashlib模块加密过程解析
这篇文章主要介绍了Python hashlib模块加密过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 hashlib模块 用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法 import hashlib m = hashlib.md5() m.update(b"Hello") m.update(b"It's me
-
python模块和包的应用BASE_PATH使用解析
这篇文章主要介绍了python模块和包的应用BASE_PATH使用解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 python中的模块(module)是管理python应用程序的工具,而包(package)是管理模块的工具.在管理和使用包的时候需要注意,调用注意设置文件的相对路径,以保证程序的可移植性. 下面的小程序主要应用os和sys模块中的一些目录管理方法实现了BASE_PATH的设置. import os import sys BAS
-
python getopt模块使用实例解析
这篇文章主要介绍了python getopt模块使用实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 官方介绍地址: https://docs.python.org/3.1/library/getopt.html 实用方向: 处理命令行参数的一个方法,简单好用. 方法: getopt模块总共有2个函数,分别为: getopt.getopt getopt.gnu_getopt 简单使用: getopt这个函数常用,简单看一下这个函数的使用:
-
Python hmac模块使用实例解析
这篇文章主要介绍了Python hmac模块使用实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 hmac模块的作用: 用于验证信息的完整性. 1.hmac消息签名(默认使用MD5加算法) hmac_md5.py #!/usr/bin/env python # -*- coding: utf-8 -*- import hmac #默认使用是md5算法 digest_maker = hmac.new('secret-shared-key'.
-
Python argparse模块使用方法解析
这篇文章主要介绍了Python argparse模块使用方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1. 说明 argparse 模块是python 用于解析命令行参数和选项的标准模块. 程序定义它需要的参数,然后 argparse 模块将弄清如何从 sys.argv 解析出那些参数. argparse 模块还会自动生成帮助和使用手册,并在用户给程序传入无效参数时报出错误信息. 2. 使用流程 使用argparse 模块配置命令行参
-
Python PyPDF2模块安装使用解析
这篇文章主要介绍了Python PyPDF2模块安装使用解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 PyPDF2模块主要的功能是分割或合并PDF文件,裁剪或转换PDF文件中的页面. 0.安装PyPDF2的模块 pip install PyPDF2 1.常用的函数 #!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2020/1/15 13:38 # @Author : suk