详解Python中四种关系图数据可视化的效果对比
python关系图的可视化主要就是用来分析一堆数据中,每一条数据的节点之间的连接关系从而更好的分析出人物或其他场景中存在的关联关系。
这里使用的是networkx的python非标准库来测试效果展示,通过模拟出一组DataFrame数据实现四种关系图可视化。
其余还包含了pandas的数据分析模块以及matplotlib的画图模块。
若是没有安装这三个相关的非标准库使用pip的方式安装一下即可。
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/ pip install networkx -i https://pypi.tuna.tsinghua.edu.cn/simple/
分别将使用到的python模块导入到我们的代码块中,就可以开始开发了。
# Importing the matplotlib.pyplot module as plt. import matplotlib.pyplot as plt # Importing the pandas module and giving it the alias pd. import pandas as pd
这里为了避免中文乱码的情况,分别对字体和编码进行了统一化的设置处理。
plt.rcParams["font.sans-serif"] = ["SimHei"] plt.rcParams["axes.unicode_minus"] = False # Importing the networkx module and giving it the alias nx. import networkx as nx
这里我们采用了有向图的模式来进行演示,有向图也是在生产过程中最常用的一种可视化模式。
G = nx.DiGraph() # 创建有向图
初始化一个DataFrame数据对象作为关系图生成的数据来源。
data_frame = pd.DataFrame(
{
'A': ['1', '2', '3', '4', '5', '6'],
'B': ['a', 'b', 'c', 'd', 'e', 'f'],
'C': [1, 2, 3, 4, 5, 6]
}
)
1、随机分布模型
使用随机分布模型的生成规则时,生成的数据节点会采用随机的方式进行展示,生成的数据节点之间相对比较分散更容易观察数据节点之间的关系指向。
for i, row in data_frame.iterrows():
G.add_edge(row['A'], row['B'], weight=row['C'])
pos = nx.random_layout(G)
nx.draw(G, pos, with_labels=True, alpha=0.7)
labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos, edge_labels=labels)
plt.axis('equal')
plt.show()
通过matplotlib展示出图形效果如下,并且默认已经添加了数据权重。
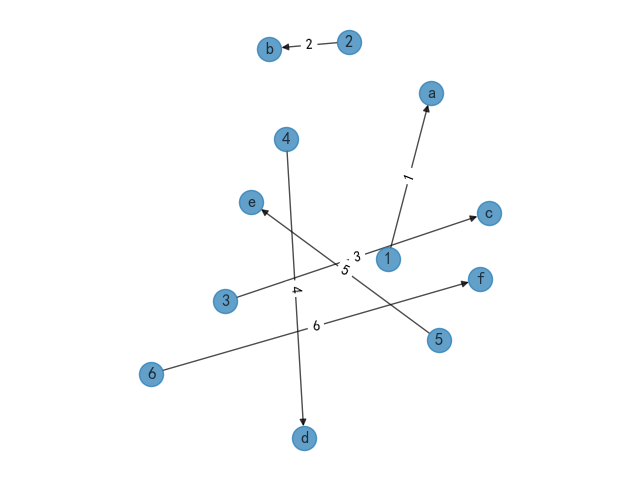
2、放射数据模型
放射状数据模型,顾名思义就是以一个数据节点为中心向周边以发散状的模式进行分布,使用数据节点指向多个节点的可视化展示。
缺点是如果数据不够规范的情况下会展示成一团乱麻的情况,需要经过特殊的可视化处理。
使用方法这里直接将上述随机分布模型的pos模型直接替换成下面的放射状数据模型即可。
pos = nx.spring_layout(G, seed=4000, k=2)
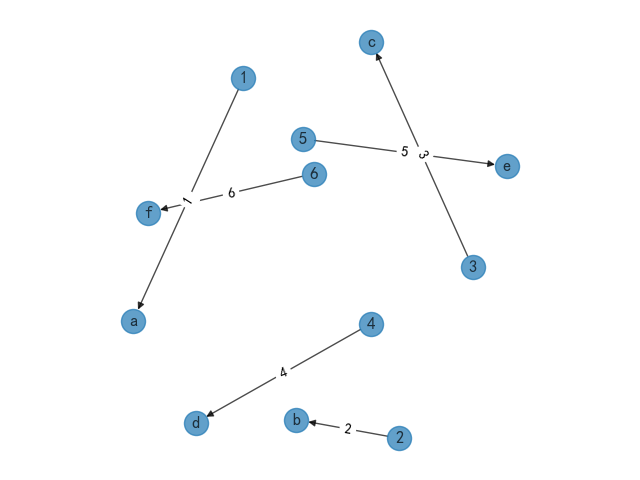
3、其他模型
其余两种方式使用同样的方式将随机分布模型中pos模型进行替换即可实现,这里分别展示以下实现效果。
特征值向量模型
pos = nx.spectral_layout(G)

图形边缘化分布模型
pos = nx.shell_layout(G)
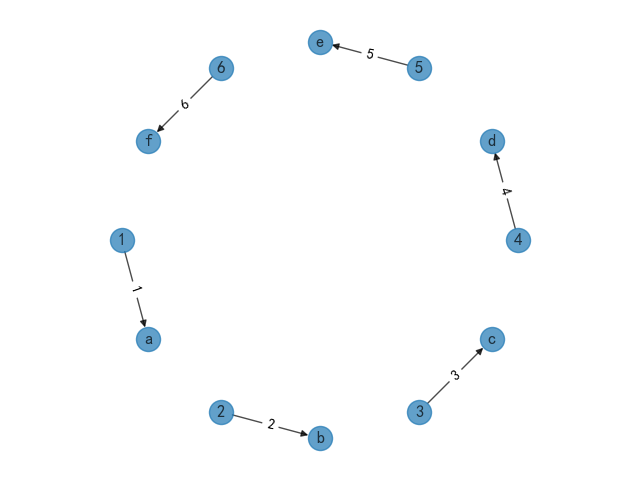
到此这篇关于详解Python中四种关系图数据可视化的效果对比的文章就介绍到这了,更多相关Python关系图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python networkx 包绘制复杂网络关系图的实现
1. 创建一个图 import networkx as nx g = nx.Graph() g.clear() #将图上元素清空 所有的构建复杂网络图的操作基本都围绕这个g来执行. 2. 节点 节点的名字可以是任意数据类型的,添加一个节点是 g.add_node(1) g.add_node("a") g.add_node("spam") 添加一组节点,就是提前构建好了一个节点列表,将其一次性加进来,这跟后边加边的操作是具有一致性的. g.add_nodes_from
-

Python实现数据可视化案例分析
目录 1. 问题描述 2. 实验环境 3. 实验步骤及结果 1. 问题描述 对右图进行修改: 请更换图形的风格 请将 x 轴的数据改为-10 到 10 请自行构造一个 y 值的函数 将直方图上的数字,位置改到柱形图的内部垂直居中的位置 对成绩数据 data1402.csv 进行分段统计:每 5 分作为一个分数段,展示出每个分数段的人数直方图. 自行创建出 10 个学生的 3 个学期排名数据,并通过直方图进行对比展示. 线图 把这个图像做一些调整,要求出现 5 个完整的波峰. 调大 cos 波形的
-
Python中不同图表的数据可视化的实现
目录 1.直方图 2. 柱形图 3. 箱线图 4.饼图 5.散点图 数据可视化是以图形格式呈现数据.它通过以简单易懂的格式汇总和呈现大量数据,帮助人们理解数据的重要性,并有助于清晰有效地传达信息. 考虑这个给定的数据集,我们将为其绘制不同的图表: 用于分析和呈现数据的不同类型的图表 1.直方图 直方图表示特定现象发生的频率,这些现象位于特定的数值范围内,并以连续和固定的间隔排列. 在下面的代码中绘制直方图Age, Income, Sales.因此,输出中的这些图显示了每个属性的每个唯一值的频率.
-
Python Matplotlib数据可视化模块使用详解
目录 前言 1 matplotlib 开发环境搭建 2 绘制基础 2.1 绘制直线 2.2 绘制折线 2.3 设置标签文字和线条粗细 2.4 绘制一元二次方程的曲线 y=x^2 2.5 绘制正弦曲线和余弦曲线 3 绘制散点图 4 绘制柱状图 5 绘制饼状图 6 绘制直方图 7 绘制等高线图 8 绘制三维图 总结 本文主要介绍python 数据可视化模块 Matplotlib,并试图对其进行一个详尽的介绍. 通过阅读本文,你可以: 了解什么是 Matplotlib 掌握如何用 Matplotlib
-
Python数据可视化之简单折线图的绘制
目录 创建RandomWalk类 选择方向 绘制随机漫步图 模拟多次随机漫步 给点着色 突出起点和终点 增加点数 调整尺寸以适用屏幕 创建RandomWalk类 为模拟随机漫步,我们将创建一个RandomWalk类,随机选择前进方向,这个类有三个属性,一个存储随机漫步的次数,另外两个存储随机漫步的每个点的x,y坐标,每次漫步都从点(0,0)出发 from random import choice class RandomWalk(): '''一个生成随机漫步数据的类''' def __init_
-
详解Python中四种关系图数据可视化的效果对比
python关系图的可视化主要就是用来分析一堆数据中,每一条数据的节点之间的连接关系从而更好的分析出人物或其他场景中存在的关联关系. 这里使用的是networkx的python非标准库来测试效果展示,通过模拟出一组DataFrame数据实现四种关系图可视化. 其余还包含了pandas的数据分析模块以及matplotlib的画图模块. 若是没有安装这三个相关的非标准库使用pip的方式安装一下即可. pip install pandas -i https://pypi.tuna.tsinghua.e
-
详解Python中4种超参自动优化算法的实现
目录 一.网格搜索(Grid Search) 二.随机搜索(Randomized Search) 三.贝叶斯优化(Bayesian Optimization) 四.Hyperband 总结 大家好,要想模型效果好,每个算法工程师都应该了解的流行超参数调优技术. 今天我给大家总结超参自动优化方法:网格搜索.随机搜索.贝叶斯优化 和 Hyperband,并附有相关的样例代码供大家学习. 一.网格搜索(Grid Search) 网格搜索是暴力搜索,在给定超参搜索空间内,尝试所有超参组合,最后搜索出最优
-
详解python的四种内置数据结构
对于每种编程语言一般都会规定一些容器来保存某些数据,就像java的集合和数组一样python也同样有这样的结构 而对于python他有四个这样的内置容器来存储数据,他们都是python语言的一部分可以直接使用而无需额外的导入 一.列表(list) 列表一种跟java和c中的数据很像的一种数据结构,他都是保存一系列相似,且有序元素的集合,不过不同的是列表中的元素可以不是同一种数据类型,且列表的长度是可变的 可以动态的增加可减少这一点则有点像java中的stringBuilder对象,列表中有一点值
-
详解python中的三种命令行模块(sys.argv,argparse,click)
Python作为一门脚本语言,经常作为脚本接受命令行传入参数,Python接受命令行参数大概有三种方式.因为在日常工作场景会经常使用到,这里对这几种方式进行总结. 命令行参数模块 这里命令行参数模块平时工作中用到最多就是这三种模块:sys.argv,argparse,click.sys.argv和argparse都是内置模块,click则是第三方模块. sys.argv模块(内置模块) 先看一个简单的示例: #!/usr/bin/python import sys def hello(name,
-
详解Python中的GIL(全局解释器锁)详解及解决GIL的几种方案
先看一道GIL面试题: 描述Python GIL的概念, 以及它对python多线程的影响?编写一个多线程抓取网页的程序,并阐明多线程抓取程序是否可比单线程性能有提升,并解释原因. GIL:又叫全局解释器锁,每个线程在执行的过程中都需要先获取GIL,保证同一时刻只有一个线程在运行,目的是解决多线程同时竞争程序中的全局变量而出现的线程安全问题.它并不是python语言的特性,仅仅是由于历史的原因在CPython解释器中难以移除,因为python语言运行环境大部分默认在CPython解释器中. 通过
-
详解python中读取和查看图片的6种方法
目录 1 OpenCV 2 imageio 3 PIL 4 scipy.misc 5 tensorflow 6 skimage 本文主要介绍了python中读取和查看图片的6种方法,分享给大家,具体如下: file_name1='test_imgs/spect/1.png' # 这是彩色图片 file_name2='test_imgs/mri/1.png' # 这是灰度图片 1 OpenCV 注:用cv2读取图片默认通道顺序是B.G.R,而不是通常的RGB顺序,所以读进去的彩色图直接显示会出现变
-
详解Python中list[::-1]的几种用法
本文主要介绍了Python中list[::-1]的几种用法,分享给大家,具体如下: s = "abcde" list的[]中有三个参数,用冒号分割 list[param1:param2:param3] param1,相当于start_index,可以为空,默认是0 param2,相当于end_index,可以为空,默认是list.size param3,步长,默认为1.步长为-1时,返回倒序原序列 举例说明 param1 = -1,只有一个参数,作用是通过下标访问数据,-1为倒数第一个
-
一文详解Python中实现单例模式的几种常见方式
目录 Python 中实现单例模式的几种常见方式 元类(Metaclass): 装饰器(Decorator): 模块(Module): new 方法: Python 中实现单例模式的几种常见方式 元类(Metaclass): class SingletonType(type): """ 单例元类.用于将普通类转换为单例类. """ _instances = {} # 存储单例实例的字典 def __call__(cls, *args, **kwa
-
通俗易懂详解Python基础五种下划线作用
目录 1.后单下划线例如: data_ 2.前单下划线例如: _data 3.前双下划线例如: __data 4.前后双下划线: __data__ 5.单下划线例如: _ 1.后单下划线例如: data_ 其实这种就是为了防止跟系统关键字重名了,比如 python 里是不是有个关键字 class 但是我也想用 class做变量怎么办,如果不做处理肯定是不行的有冲突 所以我们在后面添加 _ 变成 class_, 就可以用了. 我觉得但凡懂点编程的人都能明白这个 2.前单下划线例如: _data 这
-
详解Python中string模块除去Str还剩下什么
string模块可以追溯到早期版本的Python. 以前在本模块中实现的许多功能已经转移到str物品. 这个string模块保留了几个有用的常量和类来处理str物品. 字符串-文本常量和模板 目的:包含用于处理文本的常量和类. 功能 功能capwords()将字符串中的所有单词大写. 字符串capwords.py import string s = 'The quick brown fox jumped over the lazy dog.' print(s) print(string.capw