Python实现字符串模糊匹配方式
目录
- Python字符串模糊匹配
- 包含四个参数
- python-re模块,模糊匹配
Python字符串模糊匹配
Python的difflib库中get_close_matches方法
包含四个参数
x:被匹配的字符串。words:去匹配的字符串列表。n,前topn个最佳匹配返回,默认为3。cutoff:匹配度大小,为[0, 1]浮点数,默认数值0.6。
import difflib
list1 = ['ape', 'apple', 'peach', 'puppy']
difflib.get_close_matches('appel', list1)

import keyword
difflib.get_close_matches('wheel', keyword.kwlist)
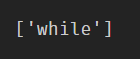
difflib.get_close_matches('pineapple', keyword.kwlist)
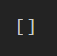
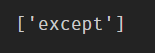
difflib.get_close_matches('accept', keyword.kwlist)
利用这个功能就能够实现SQL中的LIKE模糊查询。
python-re模块,模糊匹配
import re
def fuzzyMatch():
value = '西西'
list = ['大海西西的', '大家西西', '打架', '西都好快', '西西大化']
pattern = '.*' + value + '.*'
for s in list:
obj = re.findall(pattern, s)
if len(obj) > 0:
a = s
print(a)
break
fuzzyMatch()
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python 已知一个字符,在一个list中找出近似值或相似值实现模糊匹配
已知一个元素,在一个list中找出相似的元素 使用场景: 已知一个其它来源的字符串, 它有可能是不完全与我数据库中相应的字符串匹配的,因此,我需要将其转为适合我数据库中的字符串 使用场景太绕了, 直接举例来说吧 随便举例: 按青岛城市的城区来说, 我数据库中存储的城区是个list:['市北区', '市南区', '莱州市', '四方区']等 从其它的数据来源得到一个城区是:市北 我怎么得到与市北相似相近的市北区 解决方案: In [1]: import difflib In [2]: cityar
-
Python字符串匹配之6种方法的使用详解
1. re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none. import re line="this hdr-biz 123 model server 456" pattern=r"123" matchObj = re.match( pattern, line) 2. re.search 扫描整个字符串并返回第一个成功的匹配. import re line="this hdr-biz model
-
python 字符串模糊匹配Fuzzywuzzy的实现
目录 (1)安装 (2)接口说明 (3)使用 Python提供fuzzywuzzy模块,不仅可用于计算两个字符串之间的相似度,而且还提供排序接口能从大量候选集中找到最相似的句子. (1)安装 pip install fuzzywuzzy (2)接口说明 两个模块:fuzz, process,fuzz主要用于两字符串之间匹配,process主要用于搜索排序. fuzz.ratio(s1,s2)直接计算s1和s2之间的相似度,返回值为0-100,100表示完全相同: fuzz.partial_rat
-
Python实现字符串模糊匹配方式
目录 Python字符串模糊匹配 包含四个参数 python-re模块,模糊匹配 Python字符串模糊匹配 Python的difflib库中get_close_matches方法 包含四个参数 x:被匹配的字符串. words:去匹配的字符串列表. n,前topn个最佳匹配返回,默认为3. cutoff:匹配度大小,为[0, 1]浮点数,默认数值0.6. import difflib list1 = ['ape', 'apple', 'peach', 'puppy'] difflib.get_
-

Python+FuzzyWuzzy实现模糊匹配的示例详解
目录 1. 前言 2. FuzzyWuzzy库介绍 2.1 fuzz模块 2.2 process模块 3. 实战应用 3.1 公司名称字段模糊匹配 3.2 省份字段模糊匹配 4. 全部函数代码 在日常开发工作中,经常会遇到这样的一个问题:要对数据中的某个字段进行匹配,但这个字段有可能会有微小的差异.比如同样是招聘岗位的数据,里面省份一栏有的写“广西”,有的写“广西壮族自治区”,甚至还有写“广西省”……为此不得不增加许多代码来处理这些情况. 今天跟大家分享FuzzyWuzzy一个简单易用的模糊字符
-
C/C++实现字符串模糊匹配
需求: 准入授权配置文件有时候分了好几个维度进行配置,例如 company|product|sys这种格式的配置: 1.配置 "sina|weibo|pusher" 表示 sina公司weibo产品pusher系统能够准入,而"sina|weibo|sign"不允许准入 2.配置 "sina|*|pusher" 表示sina公司所有产品的pusher系统都能够准入 3.配置 "*|*|pusher" 表示所有公司的所有产品的p
-
正则表达式实现字符的模糊匹配功能示例
本文实例讲述了正则表达式实现字符的模糊匹配功能.分享给大家供大家参考,具体如下: package com.cn.util; import java.util.regex.Pattern; /** * 正则表达式 工具类 * * @author lifangyu */ public class RegexUtil { /* * IP地址的匹配标达式 ( // \\d{1,3}) // :\d // 0~9数字,{1,3} // 至少一位,最多三位) */ private static String
-
Mybatis如何解决sql中like通配符模糊匹配问题
目录 sql中like通配符模糊匹配问题 将查询条件通过功能类处理 后台Contronller获得查询条件 mapper.xml中对应的使用方法 使用like实现模糊匹配 方式一 方式二 方式三 sql中like通配符模糊匹配问题 针对oracle数据库: 将查询条件通过功能类处理 /** * Description: 处理转义字符%和_,针对ORACLE数据库 * * @param str * @return */ public st
-
Python使用中文正则表达式匹配指定中文字符串的方法示例
本文实例讲述了Python使用中文正则表达式匹配指定中文字符串的方法.分享给大家供大家参考,具体如下: 业务场景: 从中文字句中匹配出指定的中文子字符串 .这样的情况我在工作中遇到非常多, 特梳理总结如下. 难点: 处理GBK和utf8之类的字符编码, 同时正则匹配Pattern中包含汉字,要汉字正常发挥作用,必须非常谨慎.推荐最好统一为utf8编码,如果不是这种最优情况,也有酌情处理. 往往一个具有普适性的正则表达式会简化程序和代码的处理,使过程简洁和事半功倍,这往往是高手和菜鸟最显著的差别.
-
python中数据库like模糊查询方式
在Python中%是一个格式化字符,所以如果需要使用%则需要写成%%. 将在Python中执行的sql语句改为: sql = "SELECT * FROM table_test WHERE value LIKE '%%%%%s%%%%'" % test_value 执行成功,print出SQL语句之后为: SELECT * FROM table_test WHERE value LIKE '%%public%%' Python在执行sql语句的时候,同样也会有%格式化的问题,仍然需要使
-
Python批量模糊匹配的3种方法实例
目录 前言 使用编辑距离算法进行模糊匹配 使用fuzzywuzzy进行批量模糊匹配 fuzz模块 process模块 整体代码 使用Gensim进行批量模糊匹配 Gensim简介 使用词袋模型直接进行批量相似度匹配 使用TF-IDF主题向量变换后进行批量相似度匹配 同时获取最大的3个结果 完整代码 总结 前言 当然,基于排序的模糊匹配(类似于Excel的VLOOKUP函数的模糊匹配模式)也属于模糊匹配的范畴,但那种过于简单,不是本文讨论的范畴. 本文主要讨论的是以公司名称或地址为主的字符串的模糊