利用正则表达式抓取博客园列表数据
鉴于我在要完成的asp.net MVC 3 仿照博客园企业系统要用到测试数据,我自己输入太累,所以我就抓取了博客园的部分列表数据,还请dudu不要见怪。
在抓取博客园数据的时候采用了正则表达式,所以有不熟悉正则表达式的朋友可以参考相关资料,其实很容易掌握,就是在具体的实例中会花些时间。
现在我就来把我抓取博客园数据的过程叙述一下,如果有朋友有更好的意见,欢迎提出来。
要使用正则表达式抓取数据,首先就要创建一个正则表达式进行匹配,我推荐使用regulator,这个正则表达式工具,我们可以先使用这个工具把我们要使用的正则表达式拼接出来,然后在程序中使用。
我发现博客园的首页列表可以通过http://www.cnblogs.com/p1,p2...这种方式来直接访问,这样我们就可以直接通过url获取数据,而不用模拟数据点击事件来虚拟的点击下一页的那个按钮获取数据,更加方便。因为我的目的就是抓取一些数据,所以就简单点。
1.首先就是要写对应的sql Helper类,相信这是很多程序员都会掌握的,无非就是增删改查的操作。在创建好了sqlhelper类之后,我们就可以开始进行抓取数据的逻辑处理。
2.创建BlogRegexController
public class BlogRegexController : Controller
{
public void ExecuteRegex()
{
string strBaseUrl = "http://www.cnblogs.com/p"; //定义博客园可以访问的列表数据的基地址
for (int i = ; i <= ; i++)//因为博客园首页列表最大只有页,所以我们这个循环就执行次
{
string strUrl = strBaseUrl + i.ToString();
BlogRege blogRegex = new BlogRege(); //定义的具体的Regex类 抓取博客园地址
string result = blogRegex.SendUrl(strUrl);
blogRegex.AnalysisHtml(result);
Response.Write("获取成功");
}
}
//
// GET: /BlogRegex/
public ActionResult Index()
{
ExecuteRegex();
return View();
}
}
在controller中的ExecuteRegex()方法就是执行抓取博客园列表数据的功臣。
3.首先就是其中定义的BlogRege类,他负责抓取博客园列表数据并将其插入到数据库中
public class BlogRege
{ //负责把数据插入到数据库中 使用到的是sqlhelper类
public void Insert(string title, string content,string linkurl, int categoryID = )
{
SqlHelper helper = new SqlHelper();
helper.Insert(title, content, categoryID,linkurl);
}
/// <summary>
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
/// </summary>
/// <param name="strUrl"></param>
/// <returns></returns>
public string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
/// <summary>
/// 分析Html 解析出里面具体的数据
/// </summary>
/// <param name="htmlContent"></param>
public void AnalysisHtml(string htmlContent)
{//这个就是我在regulator正则表达式工具中拼接获取到的正则表达式 还有一点请注意就是转义字符的问题
string strPattern = "<div\\s*class=\"post_item\">\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*<div\\s*class=\"post_item_body\">\\s*<h><a\\s*class=\"titlelnk\"\\s*href=\"(?<href>.*)\"\\s*target=\"_blank\">(?<title>.*)</a>.*\\s*<p\\s*class=\"post_item_summary\">\\s*(?<content>.*)\\s*</p>";
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(htmlContent))
{
MatchCollection matchCollection = regex.Matches(htmlContent);
foreach (Match match in matchCollection)
{
string title = match.Groups[].Value;//获取到的是列表数据的标题
string content = match.Groups[].Value;//获取到的是内容
string linkurl=match.Groups[].Value;//获取到的是链接到的地址
Insert(title, content,linkurl);//执行插入到数据库的操作
}
}
}
}
4.通过上面的代码我们可以很轻松的从博客园中获取我们用来测试的数据,方便快捷,而且真实,比我们手动输入的速度要快很多。
正则表达式其实不应该算是一种语言,只能算是一种语法,因为任何的语言包括C#,javascript等语言都对正则表达式有很好的支持,只是他们的使用语法稍有不同,其实只要我们可以正确的拼接出正则表达式,那么我们抓取任何网站的内容都可以很轻松的做到。前一段我试着抓取了淘宝的数据,一共抓取了有几百万条,我想应该还有很多没有抓取到,不得不佩服淘宝,数据量太大。
回到我们使用的C#语言上,其实对正则表达式也有着非常好的支持,Regex就是用来对正则表达式进行操作的类,所有的对正则表达式的操作都在这个类中。
如果你对正则表达式还不是太熟悉,网上有一篇正则表达式30分钟入门教程,大家可以参考一下,写的很不错。再加上使用一个正则表达式工具,相信可以抓取到任何你想的内容。
在拼接正则表达式的时候,可能会花费很长时间,毕竟要分析html结构,从中抓取内容。希望大家可以沉住气,因为只要正则表达式拼接正确,那么一定可以抓取正确的内容。
为了避免大家说只说不做,那么我就把我抓取的博客园首页内容秀一下,因为博客园首页数据会有更新,所以大家可以看到这些数据都是在博客园中顺序存在的。
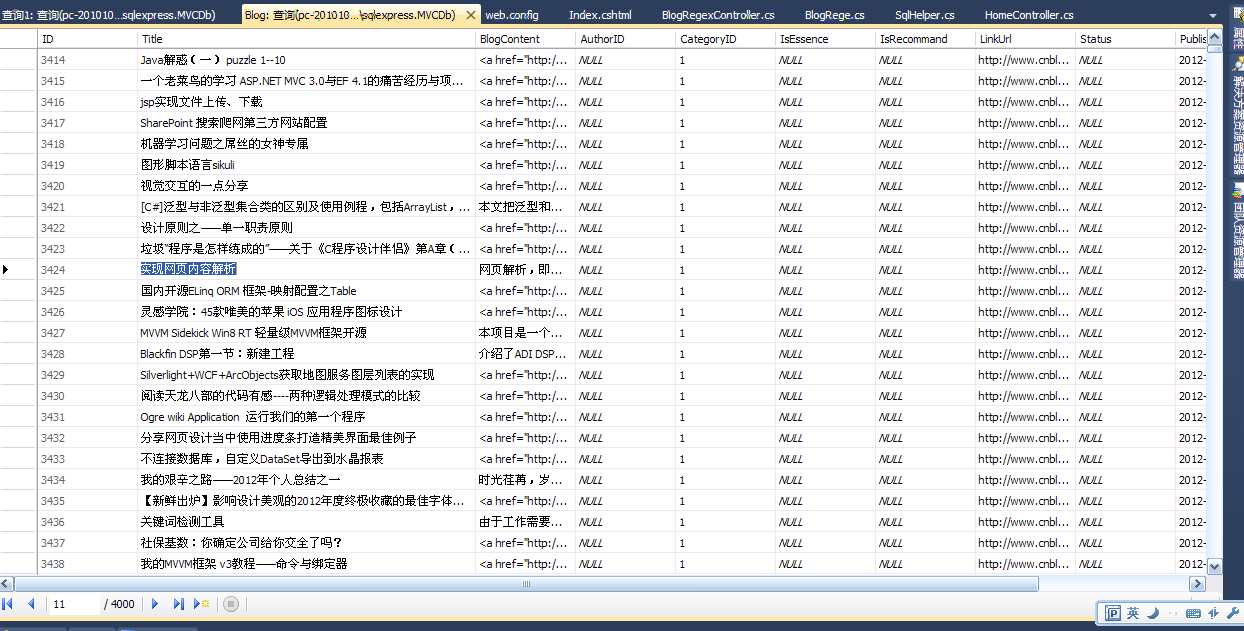
博客园每页列表是20条,一共200页,所以一共是4000条。数据抓取正确。
我以前说过,只是会代码的程序员不一定是合格程序员,程序员应该尽可能的减少自己的工作量,因为我们都是高智商的人。所以我们应该积极的学习各种对我们的工作有帮助的框架或者是方法,比如IOC、Entity Framework或Nhibernate框架来减轻我们开发维护代码的负担,毕竟我们听到需求要更改的反映,一般都是愤怒,然后大骂,最后才是修改。有些框架能够帮助我们,给我们维护代码带来好心情,何乐而不为呢。
我最后说一句,因为我要开发一个简单的仿照博客园的网站(MVC3),所以会用到各种技术准备,我提前写出来把这些要用到的内容整理一下,为以后的开发加速。
下一次,我准备整理一下在MVC中使用文本编辑器KindEditor的方法,希望大家如果有好的意见或者资料可以提供一下,让我也增加一些见识。谢谢各位
相关推荐
-
python正则表达式抓取成语网站
1.首先找到一个在线成语网站 2.查看网页结构,定义正则式 看一下要抓的成语的标签有什么特点,查看源码,可以发现要抓的成语都在<a>标签中,如:<a href="/cy0/93.html">安如磐石</a>,成语事实上就是一个瞄文本,不同成语指向的链接不同,其实也就"/cy0/93.html"中的数字不同,所以正则式里匹配两次数字就行了,定义正则式 reg = "<a href=\"/cy(\d+)/
-
php使用curl和正则表达式抓取网页数据示例
利用curl和正则表达式做的一个针对磨铁中文网非vip章节的小说抓取器,支持输入小说ID下载小说. 依赖项:curl 可以简单的看下,里面用到了curl ,正则表达式,ajax等技术,适合新手看看.在本地测试,必须保证联网并且确保php开启curl的mode SpiderTools.class.php 复制代码 代码如下: <?php session_start(); //封装成类 开启这些自动抓取文章 #header("Refresh:30;http://www.test.co
-
dw(dreamweaver)正则表达式函数列表
刚用teleport pro拉了一个整站到本地所有的超链都被强行加了一句tppabs="..."新装的系统和dreamweaver 8就玩了一把dw的替换功能查找范围:整个当前本地站点搜索:源代码查找:\btppabs="h[^"]*"替换:(为空)勾选:使用正则表达式点替换全部按钮OK~~搞定-- 例子2: 里面包含了括号 单引号等 查找:href="javascript:if\(confirm\('(.*?) '\)\)window\.loc
-

利用正则表达式抓取博客园列表数据
鉴于我在要完成的asp.net MVC 3 仿照博客园企业系统要用到测试数据,我自己输入太累,所以我就抓取了博客园的部分列表数据,还请dudu不要见怪. 在抓取博客园数据的时候采用了正则表达式,所以有不熟悉正则表达式的朋友可以参考相关资料,其实很容易掌握,就是在具体的实例中会花些时间. 现在我就来把我抓取博客园数据的过程叙述一下,如果有朋友有更好的意见,欢迎提出来. 要使用正则表达式抓取数据,首先就要创建一个正则表达式进行匹配,我推荐使用regulator,这个正则表达式工具,我们可以先使用这个
-
使用HtmlAgilityPack XPath 表达式抓取博客园数据的实现代码
Web 前端代码 复制代码 代码如下: <%@ Page Language="C#" AutoEventWireup="true" CodeFile="Default.aspx.cs" Inherits="_Default" %> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.
-
基于JQuery的抓取博客园首页RSS的代码
效果图:实现代码: 复制代码 代码如下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http
-
详解Python爬虫爬取博客园问题列表所有的问题
一.准备工作 首先,本文使用的技术为 python+requests+bs4,没有了解过可以先去了解一下. 我们的需求是将博客园问题列表中的所有问题的题目爬取下来. 二.分析: 首先博客园问题列表页面右键点击检查 通过Element查找问题所对应的属性或标签 可以发现在div class ="one_entity"中存在页面中分别对应每一个问题 接着div class ="news_item"中h2标签下是我们想要拿到的数据 三.代码实现 首先导入requests和
-
Node.js+jade抓取博客所有文章生成静态html文件的实例
这篇文章,我们就把上文中采集到的所有文章列表的信息整理一下,开始采集文章并且生成静态html文件了.先看下我的采集效果,我的博客目前77篇文章,1分钟不到就全部采集生成完毕了,这里我截了部分的图片,文件名用文章的id生成的,生成的文章,我写了一个简单的静态模板,所有的文章都是根据这个模板生成的. 项目结构: 好了,接下来,我们就来讲解下,这篇文章主要实现的功能: 1,抓取文章,主要抓取文章的标题,内容,超链接,文章id(用于生成静态html文件) 2,根据jade模板生成html文件 一.抓取文
-
利用python-pypcap抓取带VLAN标签的数据包方法
1.背景介绍 在采用通常的socket抓包方式下,操作系统会自动将收到包的VLAN信息剥离,导致上层应用收到的包不会含有VLAN标签信息.而libpcap虽然是基于socket实现抓包,但在收到数据包后,会进一步恢复出剥离的VLAN信息,能够满足需要抓取带VLAN标签信息的数据包的需求场景. python-pypcap包是对libpcap库的python语言封装,本文主要介绍如果利用python-pypcap在网络接口抓取带VLAN标签的数据包. 2.环境准备 libpcap-0.9.4 pyt
-
详解JAVA抓取网页的图片,JAVA利用正则表达式抓取网站图片
利用Java抓取网页上的所有图片: 用两个正则表达式: 1.匹配html中img标签的正则:<img.*src=(.*?)[^>]*?> 2.匹配img标签中得src中http路径的正则:http:\"?(.*?)(\"|>|\\s+) 实现: package org.swinglife.main; import java.io.File; import java.io.FileOutputStream; import java.io.InputStream;
-
如何利用http协议发布博客园博文评论
先给大家介绍下实现原理: 给博文提交评论的实质就是通过http协议服务器发送一个post请求.在发布评论前,我们需要做什么呢?对,是必须要登录的.但登录是另一件事情,我们这里先不讨论.用户登录后,服务器给客户端设置一个cookie.http是无状态的.也就是说客户端向服务器发送请求后,服务器返回响应.一次通信完成.服务器不会记得刚才是谁向自己发送请求.所以客户端需要拿着服务器给自己设定好的cookie向服务器发送请求并告知服务器自己的身份,服务器根据cookie产生响应. 准备工作: 为了完成本
-
C#.Net基于正则表达式抓取百度百家文章列表的方法示例
本文实例讲述了C#.Net基于正则表达式抓取百度百家文章列表的方法.分享给大家供大家参考,具体如下: 工作之余,学习了一下正则表达式,鉴于实践是检验真理的唯一标准,于是便写了一个利用正则表达式抓取百度百家文章的例子,具体过程请看下面源码: 一.获取百度百家网页内容 public List<string[]> GetUrl() { try { string url = "http://baijia.baidu.com/"; WebRequest webRequest = We
-
Python 批量刷博客园访问量脚本过程解析
今早无聊...7点起来突然想写个刷访问量的..那就动手吧 仅供测试,不建议刷访问量哦~~ 很简单的思路,第一步提取代理ip,第二步模拟访问. 提取HTTP代理IP 网上很多收费的代理和免费的代理IP 如: 无论哪个网站,我们需要的就是爬取上面的ip和端口号,整理到一起. 具体的网站根据具体的结构爬取 比如上面那个网站,ip和端口在td标签 这里利用bs4爬取即可.贴上脚本 ##获取代理ip def Get_proxy_ip(): print("==========批量提取ip刷博客园访问量 By