详解Ubuntu16.04下Hadoop 2.7.3的安装与配置
一、Java环境搭建
(1)下载JDK并解压(当前操作系统为Ubuntu16.04,jdk版本为jdk-8u111-Linux-x64.tar.gz)
新建/usr/java目录,切换到jdk-8u111-linux-x64.tar.gz所在目录,将这个文件解压缩到/usr/java目录下。
tar -zxvf jdk-8u101-linux-x64.tar.gz -C /usr/java/
(2)设置环境变量
修改.bashrc,在最后一行写入下列内容。
sudo vim ~/.bashrc
export JAVA_HOME=/usr/java/jdk1.8.0_111 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$JAVA_HOME/bin:$PATH

运行如下命令使环境变量生效。
source ~/.bashrc
打开profile文件,插入java环境配置节。
sudo vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.8.0_111 export JAVA_BIN=$JAVA_HOME/bin export JAVA_LIB=$JAVA_HOME/lib export CLASSPATH=.:$JAVA_LIB/tools.jar:$JAVA_LIB/dt.jar export PATH=$JAVA_HOME/bin:$PATH

打开environment 文件,追加jdk目录和jdk下的lib的目录,如下所示。
sudo vim /etc/environment
PATH="/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games:/usr/java/jdk1.8.0_111/lib:/usr/java/jdk1.8.0_111"

使配置生效
source /etc/environment
验证java环境是否配置成功
java -version
二、安装ssh-server并实现免密码登录
(1)下载ssh-server
sudo apt-get install openssh-server
(2)启动ssh
sudo /etc/init.d/ssh start
(3)查看ssh服务是否启动,如果有显示相关ssh字样则表示成功。
ps -ef|grep ssh

(4)设置免密码登录
使用如下命令,一直回车,直到生成了rsa。
ssh-keygen -t rsa
导入authorized_keys
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
测试是否免密码登录localhost
ssh localhost
关闭防火墙
ufw disable
三、安装Hadoop单机模式和伪分布模式。
(1)下载hadoop-2.7.3.tar.gz,解压到/usr/local(单机模式搭建)。
sudo tar zxvf hadoop-2.7.3.tar.gz -C /usr/local
切换到/usr/local下,将hadoop-2.7.3重命名为hadoop,并给/usr/local/hadoop设置访问权限。
cd /usr/local sudo mv hadoop-2.7.3 hadoop sudo chmod 777 /usr/local/hadoop
(2)配置.bashrc文件
sudo vim ~/.bashrc
(如果没有安装vim,请用 sudo apt install vim 安装。)
在文件末尾追加下面内容,然后保存。
#HADOOP VARIABLES START export JAVA_HOME=/usr/java/jdk1.8.0_111 export HADOOP_INSTALL=/usr/local/hadoop export PATH=$PATH:$HADOOP_INSTALL/bin export PATH=$PATH:$HADOOP_INSTALL/sbin export HADOOP_MAPRED_HOME=$HADOOP_INSTALL export HADOOP_COMMON_HOME=$HADOOP_INSTALL export HADOOP_HDFS_HOME=$HADOOP_INSTALL export YARN_HOME=$HADOOP_INSTALL export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_INSTALL/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_INSTALL/lib" #HADOOP VARIABLES END
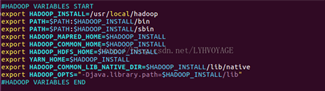
执行下面命令,使添加的环境变量生效:
source ~/.bashrc
(3)hadoop配置 (伪分布模式搭建)
配置hadoop-env.sh
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
# The java implementation to use. export JAVA_HOME=/usr/java/jdk1.8.0_111 export HADOOP=/usr/local/hadoop export PATH=$PATH:/usr/local/hadoop/bin

配置yarn-env.sh
sudo vim /usr/local/hadoop/etc/hadoop/yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/ JAVA_HOME=/usr/java/jdk1.8.0_111

配置core-site.xml,在home目录下创建 /home/lyh/hadoop_tmp目录,然后在core-site.xml中添加下列内容。
sudo mkdir /home/lyh/hadoop_tmp
sudo vim /usr/local/hadoop/etc/hadoop/core-site.xml
<configuration>
<!-- 指定HDFS老大(namenode)的通信地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/lyh/hadoop_tmp</value>
</property>
</configuration>

配置hdfs-site.xml
sudo vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
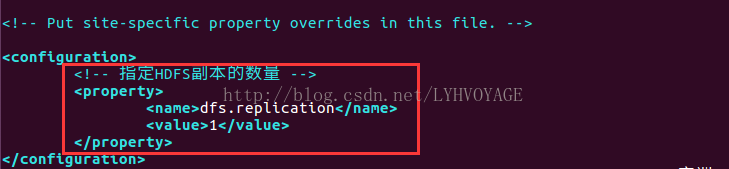
<configuration>
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
配置yarn-site.xml
sudo vim /usr/local/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>127.0.0.1:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>127.0.0.1:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>127.0.0.1:8031</value>
</property>
</configuration>

(4)关机重启系统。
四、测试Hadoop是否安装并配置成功。
(1)验证Hadoop单机模式安装完成
hadoop version
能够显示Hadoop的版本号即可说明单机模式已经配置完成。
(2)启动hdfs使用为分布模式。
格式化namenode
hdfs namenode -format
有 "……has been successfully formatted" 等字样出现即说明格式化成功。注意:每次格式化都会生成一个namenode对应的ID,多次格式化之后,如果不改变datanode对应的ID号,运行wordcount向input中上传文件时会失败。
启动hdfs
start-all.sh

显示进程
jps

在浏览器中输入http://localhost:50070/,出现如下页面

输入 http://localhost:8088/,出现如下页面
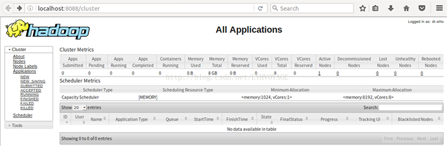
则说明伪分布安装配置成功了。
停止hdfs
stop-all.sh

五、运行wordcount
(1)启动hdfs。
start-all.sh
(2)查看hdfs底下包含的文件目录
hadoop dfs -ls /
如果是第一次运行hdfs,则什么都不会显示。

(3)在hdfs中创建一个文件目录input,将/usr/local/hadoop/README.txt上传至input中。
hdfs dfs -mkdir /input hadoop fs -put /usr/local/hadoop/README.txt /input


(4)执行以下命令运行wordcount,并将结果输出到output中。
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input /output
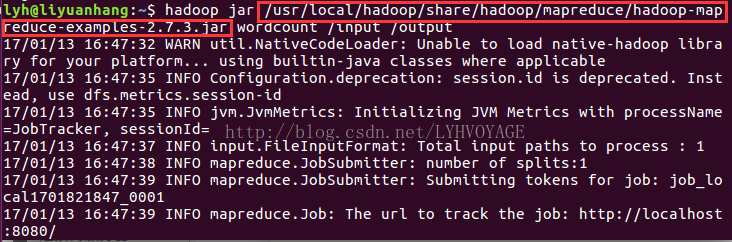
出现类似上图的页面说明wordcount运行成功。注意:请将图中红色线框中的内容替换为自己的hadoop-mapreduce-examples-2.7.3.jar文件的路径信息。
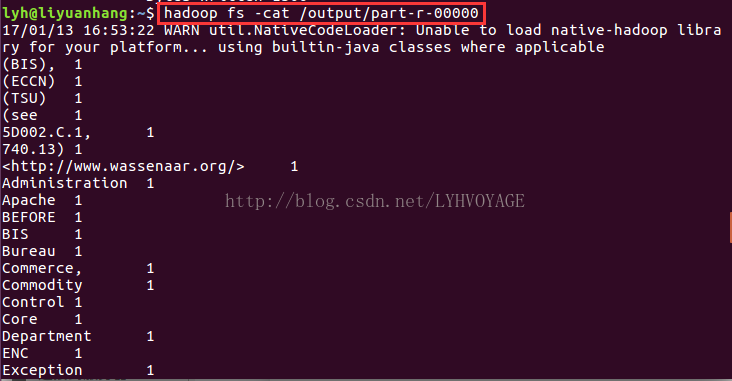
(5)执行成功后output 目录底下会生成两个文件 _SUCCESS 成功标志的文件,里面没有内容。 一个是 part-r-00000 ,通过以下命令查看执行的结果,如下图。
hadoop fs -cat /output/part-r-00000
附:hdfs常用命令
hadoop fs -mkdir /tmp/input 在HDFS上新建文件夹 hadoop fs -put input1.txt /tmp/input 把本地文件input1.txt传到HDFS的/tmp/input目录下 hadoop fs -get input1.txt /tmp/input/input1.txt 把HDFS文件拉到本地 hadoop fs -ls /tmp/output 列出HDFS的某目录 hadoop fs -cat /tmp/ouput/output1.txt 查看HDFS上的文件 hadoop fs -rmr /home/less/hadoop/tmp/output 删除HDFS上的目录 hadoop dfsadmin -report 查看HDFS状态,比如有哪些datanode,每个datanode的情况 hadoop dfsadmin -safemode leave 离开安全模式 hadoop dfsadmin -safemode enter 进入安全模式
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Hadoop SSH免密码登录以及失败解决方案
1. 创建ssh-key 这里我们采用rsa方式,使用如下命令: xiaosi@xiaosi:~$ ssh-keygen -t rsa -f ~/.ssh/id_rsa Generating public/private rsa key pair. Created directory '/home/xiaosi/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identifi
-

Hadoop组件简介
安装hbase 首先下载hbase的最新稳定版本 http://www.apache.org/dyn/closer.cgi/hbase/ 安装到本地目录中,我安装的是当前用户的hadoop/hbase中 tar -zxvf hbase-0.90.4.tar.gz 单机模式 修改配置文件 conf/hbase_env.sh 配置JDK的路径 修改conf/hbase-site.xml hbase.rootdir file:///home/${user.name}/hbase-tmp 完成后启动 b
-
Linux中安装配置hadoop集群详细步骤
一. 简介 参考了网上许多教程,最终把hadoop在ubuntu14.04中安装配置成功.下面就把详细的安装步骤叙述一下.我所使用的环境:两台ubuntu 14.04 64位的台式机,hadoop选择2.7.1版本.(前边主要介绍单机版的配置,集群版是在单机版的基础上,主要是配置文件有所不同,后边会有详细说明) 二. 准备工作 2.1 创建用户 创建用户,并为其添加root权限,经过亲自验证下面这种方法比较好. sudo adduser hadoop sudo vim /etc/sudoers
-
基于CentOS的Hadoop分布式环境的搭建开发
首先,要说明的一点的是,我不想重复发明轮子.如果想要搭建Hadoop环境,网上有很多详细的步骤和命令代码,我不想再重复记录. 其次,我要说的是我也是新手,对于Hadoop也不是很熟悉.但是就是想实际搭建好环境,看看他的庐山真面目,还好,还好,最好看到了.当运行wordcount词频统计的时候,实在是感叹hadoop已经把分布式做的如此之好,即使没有分布式相关经验的人,也只需要做一些配置即可运行分布式集群环境. 好了,言归真传. 在搭建Hadoop环境中你要知道的一些事儿: 1.hadoop运行于
-
详解从 0 开始使用 Docker 快速搭建 Hadoop 集群环境
Linux Info: Ubuntu 16.10 x64 Docker 本身就是基于 Linux 的,所以首先以我的一台服务器做实验.虽然最后跑 wordcount 已经由于内存不足而崩掉,但是之前的过程还是可以参考的. 连接服务器 使用 ssh 命令连接远程服务器. ssh root@[Your IP Address] 更新软件列表 apt-get update 更新完成. 安装 Docker sudo apt-get install docker.io 当遇到输入是否继续时,输入「Y/y」继
-
详解使用docker搭建hadoop分布式集群
使用Docker搭建部署Hadoop分布式集群 在网上找了很长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,只能自己写一个了. 一:环境准备: 1:首先要有一个Centos7操作系统,可以在虚拟机中安装. 2:在centos7中安装docker,docker的版本为1.8.2 安装步骤如下: <1>安装制定版本的docker yum install -y docker-1.8.2-10.el7.centos <2>安装的时候可能会报错,需要删除这个依赖 r
-
详解Ubuntu16.04下Hadoop 2.7.3的安装与配置
一.Java环境搭建 (1)下载JDK并解压(当前操作系统为Ubuntu16.04,jdk版本为jdk-8u111-Linux-x64.tar.gz) 新建/usr/java目录,切换到jdk-8u111-linux-x64.tar.gz所在目录,将这个文件解压缩到/usr/java目录下. tar -zxvf jdk-8u101-linux-x64.tar.gz -C /usr/java/ (2)设置环境变量 修改.bashrc,在最后一行写入下列内容. sudo vim ~/.bashrc
-
详解ubuntu20.04下CLion2020.1.3安装配置ROS过程说明
一 下载安装激活CLion 按照网上给的教程就可以 二 配置ROS 1.配置CLion的启动方式 在主目录打开隐藏文件.bashrc,命令是:sudo gedit ~/.bashrc 将CLion的启动文件clion.sh的路径设置为环境变量 PATH 这样在终端里,无论在哪个工作目录下都可以输入clion.sh即可启动CLion. 设置的代码是: export PATH=/home/zyw/CLionPack/clion-2020.1.3/bin:$PATH 这个路径是安装CLion的路径,不
-
详解Ubuntu16.04启动器图标异常解决方法
在Ubuntu16.04中,将某个程序锁定到启动器后,偶尔会出现无法正常运行.不能正确输入中文等问题.这里以SQLyog为例,总结一些常见问题和解决方法. 1. 锁定后图标消失/无法启动 在~/.local/share/applications/文件夹下可以找到以.desktop结尾的配置文件,以SQLyog为例,初始的配置文件如下: [Desktop Entry] Encoding=UTF-8 Version=1.0 Type=Application Name=SQLyog Icon=sqly
-
详解Ubuntu16.04安装nvidia驱动+CUDA+cuDNN的教程
准备工作 1.查看GPU是否支持CUDA lspci | grep -i nvidia 2.查看Linux版本 uname -m && cat /etc/*release nvidia驱动 1. 先卸载原有N卡驱动 #for case1: original driver installed by apt-get: sudo apt-get remove --purge nvidia* #for case2: original driver installed by runfile: sud
-
详解Ubuntu18.04下配置Nginx+RTMP+HLS+HTTPFLV服务器实现点播/直播/录制功能
2019.9.4更新 继续玩又发现个好玩的东西,nginx-http-flv-module模块,集成了之前的RTMP模块,又有httpflv模块,还是咱们国内程序员大神开发维护,真是开心,国内的大神如此出色,为他们这些愿意分享技术的人点32个赞,具体的编译和安装方式与RTMP模块基本一样,配置readme中也说得很详细,就不赘述了,需要注意的一点是,httpflv方式客户端想看也是需要服务设置cors的,这点readme中没有提到好像. 2019.6.27更新 再更新个windows版本的搭建方
-
详解Ubuntu16.04安装Docker、nvidia-docker的教程
Docker安装 1.更换国内软件源,推荐中国科技大学的源,稳定速度快(可选) sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak sudo sed -i 's/archive.ubuntu.com/mirrors.ustc.edu.cn/g' /etc/apt/sources.list sudo apt update 2.安装需要的包 sudo apt install apt-transport-https ca-certificat
-
详解Python中的Numpy、SciPy、MatPlotLib安装与配置
用Python来编写机器学习方面的代码是相当简单的,因为Python下有很多关于机器学习的库.其中下面三个库numpy,scipy,matplotlib,scikit-learn是常用组合,分别是科学计算包,科学工具集,画图工具包,机器学习工具集. numpy :主要用来做一些科学运算,主要是矩阵的运算.NumPy为Python带来了真正的多维数组功能,并且提供了丰富的函数库处理这些数组.它将常用的数学函数都进行数组化,使得这些数学函数能够直接对数组进行操作,将本来需要在Python级别进行的循
-
详解Ubuntu16.04安装Python3.7及其pip3并切换为默认版本
0.配置依赖环境,如果不进行这步可能会出现一些问题 中间可能有多余空格,去除下再运行,一般都能安装成功,如果不能可以先更新下sudo apt-get update sudo apt-get install zlib1g-dev libbz2-dev libssl-dev libncurses5-dev libsqlite3-dev libreadline-dev tk-dev libgdbm-dev libdb-dev libpcap-dev xz-utils libexpat1-dev lib
-
详解Linux环境下使Nginx服务器支持中文url的配置流程
1:确定你的系统是UTF编码 [root@Tserver ~]# env|grep LANG LANG=en_US.UTF-8 2:NGINX配置文件里默认编码设置为utf-8 server { listen 80; server_name .inginx.com ; index index.html index.htm index.php; root /usr/local/nginx/html/inginx.com; charset utf-8; } 如果是用securecrt 上传文件,请选
-
Ubuntu16.04下安装Wechat的实现方法
Ubuntu16.04下安装Wechat 很久没写博客了,前两天电脑因为teamviewer不了,原因显示是libqt5gui5版本过低,研究了一波更新,卸载了libqt5gui5,和它的依赖qtbase5-dev,打算重新安装新版本,结果重启后电脑无法启动...进入tty折腾半天后,被迫重装了系统,心血来潮的装了16.04,之前用的是14.04,记录下安装Wechat的过程,之前安装的忘记记录了,导致这次花了一两个小时配置各种环境 Ps:teamviewer的升级问题还没解决,有时间继续折腾