nlp自然语言处理基于SVD的降维优化学习
目录
- 基于SVD的降维优化
- SVD的直观意义
基于SVD的降维优化
向量降维:尽量保留数据“重要信息”的基础上减少向量维度。可以发现重要的轴(数据分布广的轴),将二维数据 表示为一维数据,用新轴上的投影值来表示各个数据点的值,示意图如下。
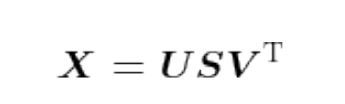
稀疏矩阵和密集矩阵转换:大多数元素为0的矩阵称为稀疏矩阵,从稀疏矩阵中找出重要的轴,用更少的维度对其进行重新表示。结果,稀疏矩阵就会被转化为大多数元素均不为0的密集矩阵。这个密集矩阵就是我们想要的单词的分布式表示。
奇异值分解(Singular Value Decomposition,SVD):任意的矩阵X分解为U、S、V,3个矩阵的乘积,其中U和V是列向量彼此正交的正交矩阵,S是除了对角线元素以外其余元素均为0的对角矩阵。

关于SVD是怎么回事,从代码中分析:
代码中使用 NumPy 的 linalg 模块中的 svd 方法,如下。
U, S, V = np.linalg.svd(W)
我们输出C、W、U、S、V,如下所示,可以看出,C是共现矩阵、W是PPMI矩阵。可以看到S矩阵是降序排列的。
[0 1 0 0 0 0 0] [1 0 1 0 1 1 0] [0 1 0 1 0 0 0] [0 0 1 0 1 0 0] [0 1 0 1 0 0 0] [0 1 0 0 0 0 1] [0 0 0 0 0 1 0] [[0. 1.807 0. 0. 0. 0. 0. ] [1.807 0. 0.807 0. 0.807 0.807 0. ] [0. 0.807 0. 1.807 0. 0. 0. ] [0. 0. 1.807 0. 1.807 0. 0. ] [0. 0.807 0. 1.807 0. 0. 0. ] [0. 0.807 0. 0. 0. 0. 2.807] [0. 0. 0. 0. 0. 2.807 0. ]] [[-3.409e-01 -1.110e-16 -3.886e-16 -1.205e-01 0.000e+00 9.323e-01 2.664e-16] [ 0.000e+00 -5.976e-01 1.802e-01 0.000e+00 -7.812e-01 0.000e+00 0.000e+00] [-4.363e-01 -4.241e-17 -2.172e-16 -5.088e-01 -1.767e-17 -2.253e-01 -7.071e-01] [-2.614e-16 -4.978e-01 6.804e-01 -4.382e-17 5.378e-01 9.951e-17 -3.521e-17] [-4.363e-01 -3.229e-17 -1.654e-16 -5.088e-01 -1.345e-17 -2.253e-01 7.071e-01] [-7.092e-01 -3.229e-17 -1.654e-16 6.839e-01 -1.345e-17 -1.710e-01 9.095e-17] [ 3.056e-16 -6.285e-01 -7.103e-01 7.773e-17 3.169e-01 -2.847e-16 4.533e-17]] [3.168e+00 3.168e+00 2.703e+00 2.703e+00 1.514e+00 1.514e+00 1.484e-16] [[ 0.000e+00 -5.976e-01 -2.296e-16 -4.978e-01 -1.186e-16 2.145e-16 -6.285e-01] [-3.409e-01 -1.110e-16 -4.363e-01 0.000e+00 -4.363e-01 -7.092e-01 0.000e+00] [ 1.205e-01 -5.551e-16 5.088e-01 0.000e+00 5.088e-01 -6.839e-01 0.000e+00] [-0.000e+00 -1.802e-01 -1.586e-16 -6.804e-01 6.344e-17 9.119e-17 7.103e-01] [-9.323e-01 -5.551e-17 2.253e-01 0.000e+00 2.253e-01 1.710e-01 0.000e+00] [-0.000e+00 7.812e-01 2.279e-16 -5.378e-01 3.390e-16 -2.717e-16 -3.169e-01] [ 0.000e+00 2.632e-16 -7.071e-01 8.043e-18 7.071e-01 9.088e-17 1.831e-17]]
下面研究U、S、V矩阵究竟是什么,添加如下代码。
print("______________________")
jym = np.dot(V, U)
print(jym)
print("______________________")
jym2 = np.dot(U, V)
print(jym2)
print("______________________")
V2 = np.transpose(V)
jb = np.dot(V, V2)
print(jb)
输出如下,那就可以把U和V的性质给搞懂了。从jb = np.dot(V, V2),输出jb矩阵是单位矩阵,可知,V和U是正交矩阵。jym = np.dot(V, U),输出jym主对角线元素全为0。U和V是列向量彼此正交的,公式里面把V转置了也就是说,U的列向量和代码里的V的行向量是正交的,所以用V乘U,他们的对角元是0。
[[-6.212e-17 1.000e+00 1.015e-08 2.968e-16 -5.249e-09 1.712e-16 6.754e-17] [ 1.000e+00 1.597e-16 3.967e-16 -2.653e-08 1.099e-16 -1.336e-08 -5.293e-09] [ 2.653e-08 3.025e-16 -2.284e-16 -1.000e+00 4.270e-16 1.110e-08 5.760e-09] [ 3.718e-16 -1.015e-08 -1.000e+00 1.958e-16 4.416e-10 -2.641e-16 2.132e-16] [ 1.336e-08 1.143e-16 2.378e-16 1.110e-08 3.405e-17 -1.000e+00 -2.662e-09] [-1.096e-17 5.249e-09 4.416e-10 -4.753e-16 -1.000e+00 -4.458e-17 8.307e-17] [-5.293e-09 -1.657e-16 7.657e-17 -5.760e-09 -1.925e-16 2.662e-09 1.000e+00]] [[-8.977e-18 9.539e-01 -2.775e-17 -2.497e-01 3.879e-16 7.108e-18 -1.668e-01] [ 9.539e-01 9.667e-18 1.764e-01 0.000e+00 1.764e-01 1.670e-01 0.000e+00] [ 4.757e-18 1.764e-01 5.000e-01 6.846e-01 -5.000e-01 3.262e-17 -1.578e-02] [-2.497e-01 -1.105e-16 6.846e-01 1.064e-16 6.846e-01 -2.032e-02 1.016e-16] [ 3.622e-18 1.764e-01 -5.000e-01 6.846e-01 5.000e-01 1.192e-16 -1.578e-02] [ 3.622e-18 1.670e-01 -1.220e-16 -2.032e-02 6.079e-17 9.043e-17 9.857e-01] [-1.668e-01 2.741e-17 -1.578e-02 -5.192e-17 -1.578e-02 9.857e-01 -4.663e-17]] [[ 1.000e+00 6.620e-17 7.901e-18 -1.015e-08 -8.632e-18 5.249e-09 -9.431e-17] [ 6.620e-17 1.000e+00 2.653e-08 -3.141e-18 1.336e-08 -1.414e-16 -5.293e-09] [ 7.901e-18 2.653e-08 1.000e+00 -1.074e-17 -1.110e-08 4.054e-17 5.760e-09] [-1.015e-08 -3.141e-18 -1.074e-17 1.000e+00 4.150e-18 -4.416e-10 1.171e-16] [-8.632e-18 1.336e-08 -1.110e-08 4.150e-18 1.000e+00 3.792e-17 -2.662e-09] [ 5.249e-09 -1.414e-16 4.054e-17 -4.416e-10 3.792e-17 1.000e+00 2.740e-16] [-9.431e-17 -5.293e-09 5.760e-09 1.171e-16 -2.662e-09 2.740e-16 1.000e+00]]
SVD的直观意义
U是正交矩阵。这个正交矩阵构成了一些空间中的基轴 (基向量),可以将矩阵U作为“单词空间”。 S是对角矩阵,奇异值在对角线上降序排列,奇异值的大小也就意味着“对应的基轴”的重要性。奇异值小,对应基轴重要性就小,所以可以通过去除U矩阵中的多余的列向量来近似原始矩阵。从而把单词向量用降维后的矩阵表示。示意图如下。

稀疏向量W经过 SVD 被转化成了密集向量U。如果要对这个密集向量降维,比如把它降维到二维向量,取出U的前两个元素即可。
text = 'You say goodbye and I say hello.'
corpus, word_to_id, id_to_word = preprocess(text)
vocab_size = len(id_to_word)
C = create_co_matrix(corpus, vocab_size, window_size=1)
W = ppmi(C)
# SVD
U, S, V = np.linalg.svd(W)
np.set_printoptions(precision=3) # 有效位数为3位
for i in range(7):
print(C[i])
print(U)
# plot
for word, word_id in word_to_id.items():
plt.annotate(word, (U[word_id, 0], U[word_id, 1]))
plt.scatter(U[:,0], U[:,1], alpha=0.5)
plt.show()
输出的U:
[[-3.409e-01 -1.110e-16 -3.886e-16 -1.205e-01 0.000e+00 9.323e-01 2.664e-16] [ 0.000e+00 -5.976e-01 1.802e-01 0.000e+00 -7.812e-01 0.000e+00 0.000e+00] [-4.363e-01 -4.241e-17 -2.172e-16 -5.088e-01 -1.767e-17 -2.253e-01 -7.071e-01] [-2.614e-16 -4.978e-01 6.804e-01 -4.382e-17 5.378e-01 9.951e-17 -3.521e-17] [-4.363e-01 -3.229e-17 -1.654e-16 -5.088e-01 -1.345e-17 -2.253e-01 7.071e-01] [-7.092e-01 -3.229e-17 -1.654e-16 6.839e-01 -1.345e-17 -1.710e-01 9.095e-17] [ 3.056e-16 -6.285e-01 -7.103e-01 7.773e-17 3.169e-01 -2.847e-16 4.533e-17]]
用二维向量表示各个单词,并把它们画在图上,画出的图如下:goodbye 和 hello、you 和 i 位置接近,这个结果复合之前做的基于余弦相似度的结果。

以上就是nlp自然语言处理基于SVD的降维优化学习的详细内容,更多关于nlp自然语言处理SVD的降维优化的资料请关注我们其它相关文章!
相关推荐
-

Python机器学习NLP自然语言处理基本操作词袋模型
概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词袋模型 词袋模型 (Bag of Words Model) 能帮助我们把一个句子转换为向量表示. 词袋模型把文本看作是无序的词汇集合, 把每一单词都进行统计. 向量化 词袋模型首先会进行分词, 在分词之后. 通过通过统计在每个词在文本中出现的次数. 我们就可以得到该文本基于词语的特征, 如果将各个文本样本的这些词与对应的词频放在一起
-
nlp自然语言处理学习CBOW模型类实现示例解析
目录 实现CBOW模型类 Trainer类的实现 实现CBOW模型类 初始化:初始化方法的参数包括词汇个数 vocab_size 和中间层的神经元个数 hidden_size.首先生成两个权重(W_in 和 W_out),并用一些小的随机值初始化这两个权重.设置astype(‘f’),初始化将使用 32 位的浮点数. 生成层:生成两个输入侧的 MatMul 层.一个输出侧的 MatMul 层,以及一个 Softmax with Loss 层. 保存权重和梯度:将该神经网络中使用的权重参数和梯度分
-
Python机器学习NLP自然语言处理基本操作关键词
目录 概述 关键词 TF-IDF 关键词提取 TF IDF TF-IDF jieba TF-IDF 关键词抽取 jieba 词性 不带关键词权重 附带关键词权重 TextRank 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 关键词 关键词 (keywords), 即关键词语. 关键词能描述文章的本质, 在文献检索, 自动文摘, 文本聚类 / 分类等方面有着重要的应用. 关键词抽
-
python SVD压缩图像的实现代码
前言 利用SVD是可以对图像进行压缩的,其核心原因在于,图像的像素之间具有高度的相关性. 代码 # -*- coding: utf-8 -*- ''' author@cclplus date:2019/11/3 ''' import cv2 import matplotlib as mpl import numpy as np import matplotlib.pyplot as plt #转为u8类型 def restore1(u, sigma, v, k): m = len(u) n =
-
nlp自然语言处理基于SVD的降维优化学习
目录 基于SVD的降维优化 SVD的直观意义 基于SVD的降维优化 向量降维:尽量保留数据“重要信息”的基础上减少向量维度.可以发现重要的轴(数据分布广的轴),将二维数据 表示为一维数据,用新轴上的投影值来表示各个数据点的值,示意图如下. 稀疏矩阵和密集矩阵转换:大多数元素为0的矩阵称为稀疏矩阵,从稀疏矩阵中找出重要的轴,用更少的维度对其进行重新表示.结果,稀疏矩阵就会被转化为大多数元素均不为0的密集矩阵.这个密集矩阵就是我们想要的单词的分布式表示. 奇异值分解(Singular Value D
-
Python机器学习NLP自然语言处理基本操作电影影评分析
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天天气真好&
-
Python机器学习NLP自然语言处理基本操作之精确分词
目录 概述 分词器 jieba 安装 精确分词 全模式 搜索引擎模式 获取词性 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 分词器 jieba jieba 算法基于前缀词典实现高效的词图扫描, 生成句子中汉字所有可能成词的情况所构成的有向无环图. 通过动态规划查找最大概率路径, 找出基于词频的最大切分组合. 对于未登录词采用了基于汉字成词能力的 HMM 模型, 使用 Viter
-
Python机器学习NLP自然语言处理基本操作之京东评论分类
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 数据介绍 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天
-
Python机器学习NLP自然语言处理基本操作之命名实例提取
目录 概述 命名实例 HMM 随机场 马尔科夫随机场 CRF 命名实例实战 数据集 crf 预处理 主程序 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 命名实例 命名实例 (Named Entity) 指的是 NLP 任务中具有特定意义的实体, 包括人名, 地名, 机构名, 专有名词等. 举个例子: Luke Rawlence 代表人物 Aiimi 和 University o
-
Python机器学习NLP自然语言处理基本操作精确分词
目录 概述 分词器 jieba 安装 精确分词 全模式 搜索引擎模式 获取词性 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 分词器 jieba jieba 算法基于前缀词典实现高效的词图扫描, 生成句子中汉字所有可能成词的情况所构成的有向无环图. 通过动态规划查找最大概率路径, 找出基于词频的最大切分组合. 对于未登录词采用了基于汉字成词能力的 HMM 模型, 使用 Viter
-
Python机器学习NLP自然语言处理基本操作家暴归类
目录 概述 数据介绍 词频统计 朴素贝叶斯 代码实现 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 数据介绍 该数据是家庭暴力的一份司法数据.分为 4 个不同类别: 报警人被老公打,报警人被老婆打,报警人被儿子打,报警人被女儿打. 今天我们就要运用我们前几次学到的知识, 来实现一个 NLP 分类问题. 词频统计 CountVectorizer是一个文本特征提取的方
-
Python机器学习NLP自然语言处理基本操作词向量模型
目录 概述 词向量 词向量维度 Word2Vec CBOW 模型 Skip-Gram 模型 负采样模型 词向量的训练过程 1. 初始化词向量矩阵 2. 神经网络反向传播 词向量模型实战 训练模型 使用模型 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词向量 我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了.