kubernetes实现分布式限流
目录
- 一、概念
- 1.1 使用场景
- 1.2 维度
- 1.3 分布式限流
- 二、分布式限流常用方案
- 三、基于kubernetes的分布式限流
- 3.1 kubernetes中的副本数
- 3.2 rateLimiter的创建
- 3.3 rateLimiter的获取
- 3.4 filter里的判断
- 四、性能压测
- 无限流
- 使用redis限流
- 自研限流
- 五、其他问题
- 5.1 对于保证qps限频准确的时候,应该怎么解决呢?
- 5.2 服务从1个节点动态扩为4个节点,这个时候新节点识别为4,但其实有些并没有启动完,会不会造成某个节点承受了太大的压力
- 5.3 如果有多个副本,怎么保证请求是均匀的
一、概念
限流(Ratelimiting)指对应用服务的请求进行限制,例如某一接口的请求限制为 100 个每秒,对超过限制的请求则进行快速失败或丢弃。
1.1 使用场景
限流可以应对:
- 热点业务带来的突发请求;
- 调用方 bug 导致的突发请求;
- 恶意攻击请求。
1.2 维度
对于限流场景,一般需要考虑两个维度的信息:
时间限流基于某段时间范围或者某个时间点,也就是我们常说的“时间窗口”,比如对每分钟、每秒钟的时间窗口做限定
资源基于可用资源的限制,比如设定最大访问次数,或最高可用连接数。
限流就是在某个时间窗口对资源访问做限制,比如设定每秒最多100个访问请求。
1.3 分布式限流
分布式限流相比于单机限流,只是把限流频次分配到各个节点中,比如限制某个服务访问100qps,如果有10个节点,那么每个节点理论上能够平均被访问10次,如果超过了则进行频率限制。
二、分布式限流常用方案
基于Guava的客户端限流Guava是一个客户端组件,在其多线程模块下提供了以RateLimiter为首的几个限流支持类。它只能对“当前”服务进行限流,即它不属于分布式限流的解决方案。
网关层限流服务网关,作为整个分布式链路中的第一道关卡,承接了所有用户来访请求。我们在网关层进行限流,就可以达到了整体限流的目的了。目前,主流的网关层有以软件为代表的Nginx,还有Spring Cloud中的Gateway和Zuul这类网关层组件,也有以硬件为代表的F5。
中间件限流将限流信息存储在分布式环境中某个中间件里(比如Redis缓存),每个组件都可以从这里获取到当前时刻的流量统计,从而决定是拒绝服务还是放行流量。
限流组件目前也有一些开源组件提供了限流的功能,比如Sentinel就是一个不错的选择。Sentinel是阿里出品的开源组件,并且包含在了Spring Cloud Alibaba组件库中。Hystrix也具有限流的功能。
Guava的Ratelimiter设计实现相当不错,可惜只能支持单机,网关层限流如果是单机则不太满足高可用,并且分布式网关的话还是需要依赖中间件限流,而redis之类的网络通信需要占用一小部分的网络消耗。阿里的Sentinel也是同理,底层使用的是redis或者zookeeper,每次访问都需要调用一次redis或者zk的接口。那么在云原生场景下,我们有没有什么更好的办法呢?
对于极致追求高性能的服务不需要考虑熔断、降级来说,是需要尽量减少网络之间的IO,那么是否可以通过一个总限频然后分配到具体的单机里面去,在单机中实现平均的限流,比如限制某个ip的qps为100,服务总共有10个节点,那么平均到每个服务里就是10qps,此时就可以通过guava的ratelimiter来实现了,甚至说如果服务的节点动态调整,单个服务的qps也能动态调整。
三、基于kubernetes的分布式限流
在Spring Boot应用中,定义一个filter,获取请求参数里的key(ip、userId等),然后根据key来获取rateLimiter,其中,rateLimiter的创建由数据库定义的限频数和副本数来判断,最后,再通过rateLimiter.tryAcquire来判断是否可以通过。
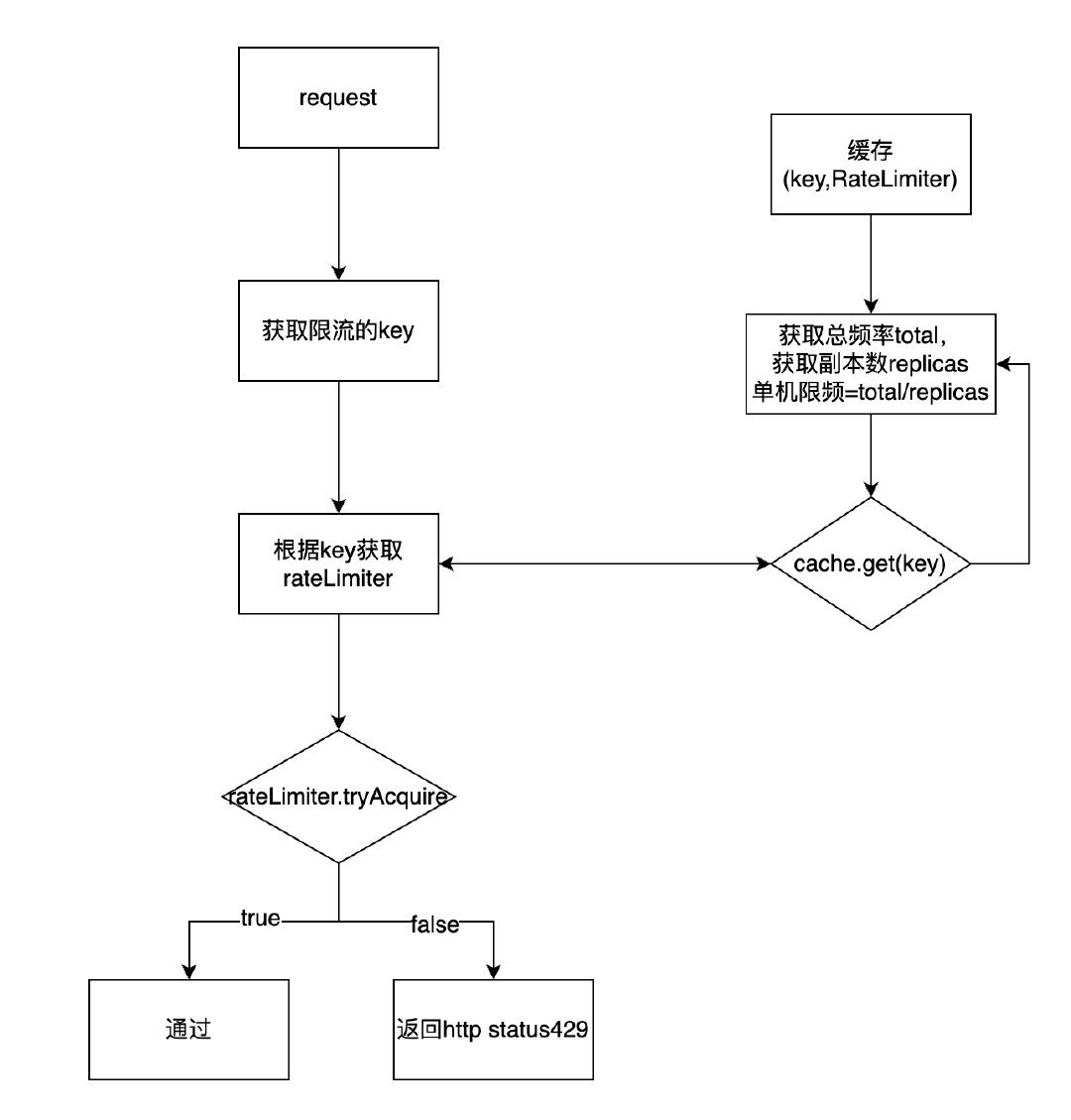
3.1 kubernetes中的副本数
在实际的服务中,数据上报服务一般无法确定客户端的上报时间、上报量,特别是对于这种要求高性能,服务一般都会用到HPA来实现动态扩缩容,所以,需要去间隔一段时间去获取服务的副本数。
func CountDeploymentSize(namespace string, deploymentName string) *int32 {
deployment, err := client.AppsV1().Deployments(namespace).Get(context.TODO(), deploymentName, metav1.GetOptions{})
if err != nil {
return nil
}
return deployment.Spec.Replicas
}
用法:GET host/namespaces/test/deployments/k8s-rest-api直接即可。
3.2 rateLimiter的创建
在RateLimiterService中定义一个LoadingCache<String, RateLimiter>,其中,key可以为ip、userId等,并且,在多线程的情况下,使用refreshAfterWrite只阻塞加载数据的线程,其他线程则返回旧数据,极致发挥缓存的作用。
private final LoadingCache<String, RateLimiter> loadingCache = Caffeine.newBuilder()
.maximumSize(10_000)
.refreshAfterWrite(20, TimeUnit.MINUTES)
.build(this::createRateLimit);
//定义一个默认最小的QPS
private static final Integer minQpsLimit = 3000;
之后是创建rateLimiter,获取总限频数totalLimit和副本数replicas,之后是自己所需的逻辑判断,可以根据totalLimit和replicas的情况来进行qps的限定。
public RateLimiter createRateLimit(String key) {
log.info("createRateLimit,key:{}", key);
int totalLimit = 获取总限频数,可以在数据库中定义
Integer replicas = kubernetesService.getDeploymentReplicas();
RateLimiter rateLimiter;
if (totalLimit > 0 && replicas == null) {
rateLimiter = RateLimiter.create(totalLimit);
} else if (totalLimit > 0) {
int nodeQpsLimit = totalLimit / replicas;
rateLimiter = RateLimiter.create(nodeQpsLimit > minQpsLimit ? nodeQpsLimit : minQpsLimit);
} else {
rateLimiter = RateLimiter.create(minQpsLimit);
}
log.info("create rateLimiter success,key:{},rateLimiter:{}", key, rateLimiter);
return rateLimiter;
}
3.3 rateLimiter的获取
根据key获取RateLimiter,如果有特殊需求的话,需要判断key不存在的尝尽
public RateLimiter getRateLimiter(String key) {
return loadingCache.get(key);
}
3.4 filter里的判断
最后一步,就是使用rateLimiter来进行限流,如果rateLimiter.tryAcquire()为true,则进行filterChain.doFilter(request, response),如果为false,则返回HttpStatus.TOO_MANY_REQUESTS
public class RateLimiterFilter implements Filter {
@Resource
private RateLimiterService rateLimiterService;
@Override
public void doFilter(ServletRequest request, ServletResponse response, FilterChain filterChain) throws IOException, ServletException {
HttpServletRequest httpServletRequest = (HttpServletRequest) request;
HttpServletResponse httpServletResponse = (HttpServletResponse) response;
String key = httpServletRequest.getHeader("key");
RateLimiter rateLimiter = rateLimiterService.getRateLimiter(key);
if (rateLimiter != null) {
if (rateLimiter.tryAcquire()) {
filterChain.doFilter(request, response);
} else {
httpServletResponse.setStatus(HttpStatus.TOO_MANY_REQUESTS.value());
}
} else {
filterChain.doFilter(request, response);
}
}
}
四、性能压测
为了方便对比性能之间的差距,我们在本地单机做了下列测试,其中,总限频都设置为3万。
无限流

使用redis限流
其中,ping redis大概6-7ms左右,对应的,每次请求需要访问redis,时延都有大概6-7ms,性能下降明显

自研限流
性能几乎追平无限流的场景,guava的rateLimiter确实表现卓越

五、其他问题
5.1 对于保证qps限频准确的时候,应该怎么解决呢?
在k8s中,服务是动态扩缩容的,相应的,每个节点应该都要有所变化,如果对外宣称限频100qps,而且后续业务方真的要求百分百准确,只能把LoadingCache<String, RateLimiter>的过期时间调小一点,让它能够近实时的更新单节点的qps。这里还需要考虑一下k8s的压力,因为每次都要获取副本数,这里也是需要做缓存的
5.2 服务从1个节点动态扩为4个节点,这个时候新节点识别为4,但其实有些并没有启动完,会不会造成某个节点承受了太大的压力
理论上是存在这个可能的,这个时候需要考虑一下初始的副本数的,扩缩容不能一蹴而就,一下子从1变为4变为几十个这种。一般的话,生产环境肯定是不能只有一个节点,并且要考虑扩缩容的话,至于要有多个副本预备的
5.3 如果有多个副本,怎么保证请求是均匀的
这个是依赖于k8s的service负载均衡策略的,这个我们之前做过实验,流量确实是能够均匀的落到节点上的。还有就是,我们整个限流都是基于k8s的,如果k8s出现问题,那就是整个集群所有服务都有可能出现问题了。
到此这篇关于kubernetes实现分布式限流的文章就介绍到这了。希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Kubernetes(K8S)入门基础内容介绍
Introduction basic of kubernetes 我们要学习 Kubernetes,就有首先了解 Kubernetes 的技术范围.基础理论知识库等,要学习 Kubernetes,肯定要有入门过程,在这个过程中,学习要从易到难,先从基础学习. 那么 Kubernetes 的入门基础内容(表示学习一门技术前先了解这门技术)包括哪些? 根据 Linux 开源基金会的认证考试,可以确认要了解 Kubernetes ,需要达成以下学习目标: Discuss Kubernetes. Lea
-
Kubernetes部署实例并配置Deployment、网络映射、副本集
Deployment Deployment 是 Kubernetes 提供的一种自我修复机制来解决机器故障维护的问题. 当我们单独使用 docker 部署应用时,为了应用挂了后能够重启,我们可以使用 --restart=always 参数,例如: docker run -itd --restart=always -p 666:80 nginx:latest 但是这种方式只能单纯重启容器,并不具备从机器故障中恢复的能力. Kubernetes Deployment 是一个配置,它可以指挥 Kube
-
Kubernetes(K8S)基础知识
目录 Kubernetes 是什么 Kubernetes 集群的组成 Kubernetes 结构 组件 Master 节点 kube-apiserver etcd kube-scheduler kube-controller-manager Kubernetes 是什么 在 2008 年,LXC(Linux containers) 发布第一个版本,这是最初的容器版本:2013 年,Docker 推出了第一个版本:而 Google 则在 2014 年推出了 LMCTFY. 为了解决大集群(Clus
-
Kubernetes中Deployment的升级与回滚
目录 更新 上线 回滚 缩放 Deployment 直接设置 Pod 水平自动缩放 比例缩放 暂停 Deployment 上线 更新 打开 https://hub.docker.com/_/nginx 可以查询 nginx 的镜像版本,我们可以先选择一个旧一点的版本. 首先,我们创建一个 Nginx 的 Deployment,副本数量为 3. kubectl create deployment nginx --image=nginx:1.19.0 --replicas=3 首次部署的时候,跟之前
-
Kubernetes关键组件与结构组成介绍
架构组成 我们可以看一下这两张图,所表示的都是关于 Kubernetes 集群的架构. 一个 kubernetes 集群是由一组被称为节点(Node)的机器或虚拟机组成,集群由 master.worker 节点组成,每个机器至少具有一个 worker 节点. Master 在前面两个图中,可以看到 Master 是由一组称为控制平面组件组成的,我们可以打开 /etc/kubernetes/manifests/ 目录,里面是 k8s 默认的控制平面组件. . ├── etcd.yaml ├── k
-
Kubernetes探针使用介绍
目录 一.基本介绍 Kubernetes 的探针有三种类型: 探针方式: 配置项: 二.K8s 探针使用介绍 1)就绪探针: 2)存活探针: 3)启动探针: 一.基本介绍 当我们在 K8s 上运行应用时,应用是否运行正常这是我们比较关心的,但是如果我们只是通过查看应用的运行状态,这是很难判断出应用是否处于运行状态的:因为在某些时候,容器正常运行并不能代表应用健康,所以我们可以通过 Kubernetes 提供的探针. 使用探针来判断容器内运行的应用是否运行正常.官方文档 Kubernetes 的探
-
使用kubeadm命令行工具创建kubernetes集群
目录 命令行工具 通过软件仓库安装 二进制文件下载安装 ubutu & centos 快速安装 创建 kubernetes 集群 1,创建 Master 2,然后初始化集群网络. 3,加入集群 清除环境 命令行工具 主要有三个工具,命令行工具使用 kube 前缀命名. kubeadm:用来初始化集群的指令. kubelet:在集群中的每个节点上用来启动 Pod 和容器等. kubectl:用来与集群通信的命令行工具. 通过软件仓库安装 方法 ① 此方法是通过 Google 的源下载安装工具包.
-
Kubernetes集群的组成介绍
Kubernetes集群的组成 我们谈起 Kubernetes 和应用部署时,往往会涉及到容器.节点.Pods 等概念,还有各种术语,令人眼花缭乱.为了更好地摸清 Kubernetes,下面我们将介绍 Kubernetes 中与应用程序部署(deployment)和执行(execution)相关的知识. Kubernetes 集群由多个组件(components).硬件(hardware).软件(software)组成,它们共同工作来管理容器化(containerized)应用的部署和执行,这些
-
Minikube搭建Kubernetes集群
Minikube 打开 https://github.com/kubernetes/minikube/releases/tag/v1.19.0 下载最新版本的二进制软件包(deb.rpm包),再使用 apt 或 yum 安装. 或者直接下载 minikube 最新版本二进制文件(推荐). curl -Lo minikube https://kubernetes.oss-cn-hangzhou.aliyuncs.com/minikube/releases/v1.19.0/minikube-linu
-
配置Kubernetes外网访问集群
查询 Service 关于 Service,读者可以查看官方文档的资料:https://kubernetes.io/zh/docs/concepts/services-networking/service/ Service 是 k8s 中为多个 pod 公开网络服务的抽象方法.在 k8s 中,每个 pod 都有自己的 ip 地址,而且 Service 可以为一组 pod 提供相同的 DNS ,使得多个 pod 之间可以相互通讯,k8s 可以在这些 pod 之间进行负载均衡. 查询 pod: ku