python神经网络Keras实现LSTM及其参数量详解
目录
- 什么是LSTM
- 1、LSTM的结构
- 2、LSTM独特的门结构
- 3、LSTM参数量计算
- 在Keras中实现LSTM
- 实现代码
什么是LSTM
1、LSTM的结构

我们可以看出,在n时刻,LSTM的输入有三个:
- 当前时刻网络的输入值Xt;
- 上一时刻LSTM的输出值ht-1;
- 上一时刻的单元状态Ct-1。
LSTM的输出有两个:
- 当前时刻LSTM输出值ht;
- 当前时刻的单元状态Ct。
2、LSTM独特的门结构
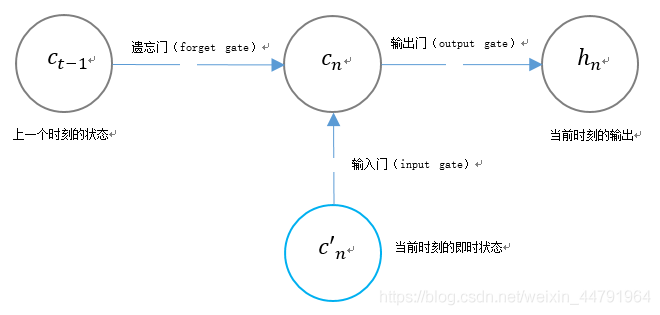
LSTM用两个门来控制单元状态cn的内容:
- 遗忘门(forget gate),它决定了上一时刻的单元状态cn-1有多少保留到当前时刻;
- 输入门(input gate),它决定了当前时刻网络的输入c’n有多少保存到新的单元状态cn中。
LSTM用一个门来控制当前输出值hn的内容:
输出门(output gate),它利用当前时刻单元状态cn对hn的输出进行控制。
3、LSTM参数量计算
a、遗忘门
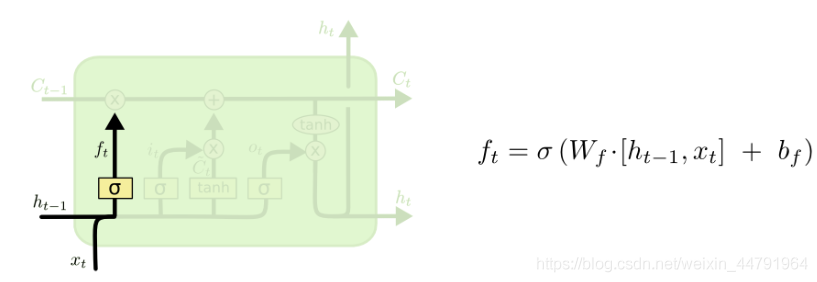
遗忘门这里需要结合ht-1和Xt来决定上一时刻的单元状态cn-1有多少保留到当前时刻;
由图我们可以得到,我们在这一环节需要计一个参数ft。


b、输入门
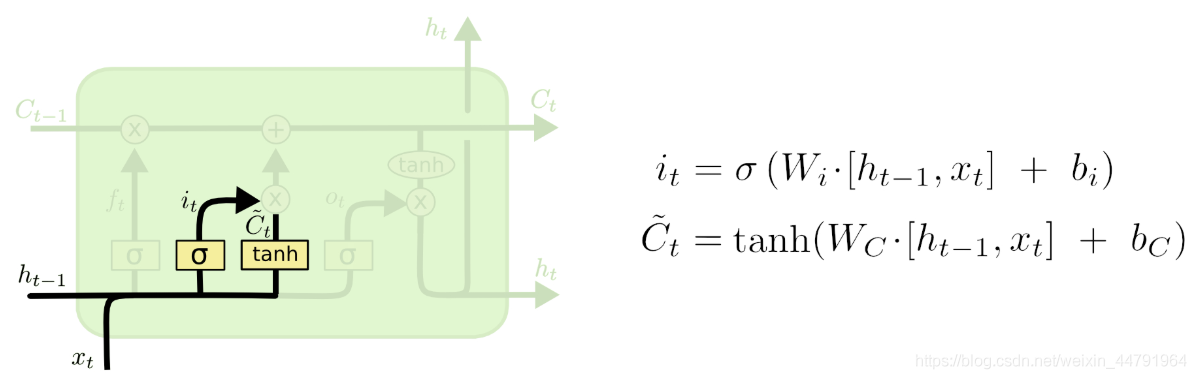
输入门这里需要结合ht-1和Xt来决定当前时刻网络的输入c’n有多少保存到单元状态cn中。
由图我们可以得到,我们在这一环节需要计算两个参数,分别是it。
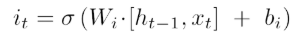
和C’t

里面需要训练的参数分别是Wi、bi、WC和bC。
在定义LSTM的时候我们会使用到一个参数叫做units,其实就是神经元的个数,也就是LSTM的输出——ht的维度。
所以:

c、输出门

输出门利用当前时刻单元状态cn对hn的输出进行控制;
由图我们可以得到,我们在这一环节需要计一个参数ot。

里面需要训练的参数分别是Wo和bo。
在定义LSTM的时候我们会使用到一个参数叫做units,其实就是神经元的个数,也就是LSTM的输出——ht的维度。
所以:

d、全部参数量
所以所有的门总参数量为:
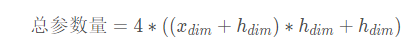
在Keras中实现LSTM
LSTM一般需要输入两个参数。
一个是unit、一个是input_shape。
LSTM(CELL_SIZE, input_shape = (TIME_STEPS,INPUT_SIZE))
unit用于指定神经元的数量。
input_shape用于指定输入的shape,分别指定TIME_STEPS和INPUT_SIZE。
实现代码
import numpy as np
from keras.models import Sequential
from keras.layers import Input,Activation,Dense
from keras.models import Model
from keras.datasets import mnist
from keras.layers.recurrent import LSTM
from keras.utils import np_utils
from keras.optimizers import Adam
TIME_STEPS = 28
INPUT_SIZE = 28
BATCH_SIZE = 50
index_start = 0
OUTPUT_SIZE = 10
CELL_SIZE = 75
LR = 1e-3
(X_train,Y_train),(X_test,Y_test) = mnist.load_data()
X_train = X_train.reshape(-1,28,28)/255
X_test = X_test.reshape(-1,28,28)/255
Y_train = np_utils.to_categorical(Y_train,num_classes= 10)
Y_test = np_utils.to_categorical(Y_test,num_classes= 10)
inputs = Input(shape=[TIME_STEPS,INPUT_SIZE])
x = LSTM(CELL_SIZE, input_shape = (TIME_STEPS,INPUT_SIZE))(inputs)
x = Dense(OUTPUT_SIZE)(x)
x = Activation("softmax")(x)
model = Model(inputs,x)
adam = Adam(LR)
model.summary()
model.compile(loss = 'categorical_crossentropy',optimizer = adam,metrics = ['accuracy'])
for i in range(50000):
X_batch = X_train[index_start:index_start + BATCH_SIZE,:,:]
Y_batch = Y_train[index_start:index_start + BATCH_SIZE,:]
index_start += BATCH_SIZE
cost = model.train_on_batch(X_batch,Y_batch)
if index_start >= X_train.shape[0]:
index_start = 0
if i%100 == 0:
cost,accuracy = model.evaluate(X_test,Y_test,batch_size=50)
print("accuracy:",accuracy)
实现效果:
10000/10000 [==============================] - 3s 340us/step accuracy: 0.14040000014007092 10000/10000 [==============================] - 3s 310us/step accuracy: 0.6507000041007995 10000/10000 [==============================] - 3s 320us/step accuracy: 0.7740999992191792 10000/10000 [==============================] - 3s 305us/step accuracy: 0.8516999959945679 10000/10000 [==============================] - 3s 322us/step accuracy: 0.8669999945163727 10000/10000 [==============================] - 3s 324us/step accuracy: 0.889699995815754 10000/10000 [==============================] - 3s 307us/step
以上就是python神经网络Keras实现LSTM及其参数量详解的详细内容,更多关于Keras实现LSTM参数量的资料请关注我们其它相关文章!
相关推荐
-
keras 简单 lstm实例(基于one-hot编码)
简单的LSTM问题,能够预测一句话的下一个字词是什么 固定长度的句子,一个句子有3个词. 使用one-hot编码 各种引用 import keras from keras.models import Sequential from keras.layers import LSTM, Dense, Dropout import numpy as np 数据预处理 data = 'abcdefghijklmnopqrstuvwxyz' data_set = set(data) word_2_int
-
keras在构建LSTM模型时对变长序列的处理操作
我就废话不多说了,大家还是直接看代码吧~ print(np.shape(X))#(1920, 45, 20) X=sequence.pad_sequences(X, maxlen=100, padding='post') print(np.shape(X))#(1920, 100, 20) model = Sequential() model.add(Masking(mask_value=0,input_shape=(100,20))) model.add(LSTM(128,dropout_W=
-
在Keras中CNN联合LSTM进行分类实例
我就废话不多说,大家还是直接看代码吧~ def get_model(): n_classes = 6 inp=Input(shape=(40, 80)) reshape=Reshape((1,40,80))(inp) # pre=ZeroPadding2D(padding=(1, 1))(reshape) # 1 conv1=Convolution2D(32, 3, 3, border_mode='same',init='glorot_uniform')(reshape) #model.add(
-
keras 解决加载lstm+crf模型出错的问题
错误展示 new_model = load_model("model.h5") 报错: 1.keras load_model valueError: Unknown Layer :CRF 2.keras load_model valueError: Unknown loss function:crf_loss 错误修改 1.load_model修改源码:custom_objects = None 改为 def load_model(filepath, custom_objects, c
-

python神经网络Keras实现LSTM及其参数量详解
目录 什么是LSTM 1.LSTM的结构 2.LSTM独特的门结构 3.LSTM参数量计算 在Keras中实现LSTM 实现代码 什么是LSTM 1.LSTM的结构 我们可以看出,在n时刻,LSTM的输入有三个: 当前时刻网络的输入值Xt: 上一时刻LSTM的输出值ht-1: 上一时刻的单元状态Ct-1. LSTM的输出有两个: 当前时刻LSTM输出值ht: 当前时刻的单元状态Ct. 2.LSTM独特的门结构 LSTM用两个门来控制单元状态cn的内容: 遗忘门(forget gate),它决定了
-
python神经网络学习数据增强及预处理示例详解
目录 学习前言 处理长宽不同的图片 数据增强 1.在数据集内进行数据增强 2.在读取图片的时候数据增强 3.目标检测中的数据增强 学习前言 进行训练的话,如果直接用原图进行训练,也是可以的(就如我们最喜欢Mnist手写体),但是大部分图片长和宽不一样,直接resize的话容易出问题. 除去resize的问题外,有些时候数据不足该怎么办呢,当然要用到数据增强啦. 这篇文章就是记录我最近收集的一些数据预处理的方式 处理长宽不同的图片 对于很多分类.目标检测算法,输入的图片长宽是一样的,如224,22
-
python神经网络Keras实现GRU及其参数量
目录 什么是GRU 1.GRU单元的输入与输出 2.GRU的门结构 3.GRU的参数量计算 a.更新门 b.重置门 c.全部参数量 在Keras中实现GRU 实现代码 什么是GRU GRU是LSTM的一个变种. 传承了LSTM的门结构,但是将LSTM的三个门转化成两个门,分别是更新门和重置门. 1.GRU单元的输入与输出 下图是每个GRU单元的结构. 在n时刻,每个GRU单元的输入有两个: 当前时刻网络的输入值Xt: 上一时刻GRU的输出值ht-1: 输出有一个: 当前时刻GRU输出值ht: 2
-
python神经网络Keras GhostNet模型的实现
目录 什么是GhostNet模型 GhostNet模型的实现思路 1.Ghost Module 2.Ghost Bottlenecks 3.Ghostnet的构建 GhostNet的代码构建 1.模型代码的构建 2.Yolov4上的应用 什么是GhostNet模型 GhostNet是华为诺亚方舟实验室提出来的一个非常有趣的网络,我们一起来学习一下. 2020年,华为新出了一个轻量级网络,命名为GhostNet. 在优秀CNN模型中,特征图存在冗余是非常重要的.如图所示,这个是对ResNet-50
-
python神经网络Keras构建CNN网络训练
目录 Keras中构建CNN的重要函数 1.Conv2D 2.MaxPooling2D 3.Flatten 全部代码 利用Keras构建完普通BP神经网络后,还要会构建CNN Keras中构建CNN的重要函数 1.Conv2D Conv2D用于在CNN中构建卷积层,在使用它之前需要在库函数处import它. from keras.layers import Conv2D 在实际使用时,需要用到几个参数. Conv2D( nb_filter = 32, nb_row = 5, nb_col = 5
-
python神经网络Keras常用学习率衰减汇总
目录 前言 为什么要调控学习率 下降方式汇总 2.指数型下降 3.余弦退火衰减 4.余弦退火衰减更新版 前言 增加了论文中的余弦退火下降方式.如图所示: 学习率是深度学习中非常重要的一环,好好学习吧! 为什么要调控学习率 在深度学习中,学习率的调整非常重要. 学习率大有如下优点: 1.加快学习速率. 2.帮助跳出局部最优值. 但存在如下缺点: 1.导致模型训练不收敛. 2.单单使用大学习率容易导致模型不精确. 学习率小有如下优点: 1.帮助模型收敛,有助于模型细化. 2.提高模型精度. 但存在如
-
python神经网络Keras搭建RFBnet目标检测平台
目录 什么是RFBnet目标检测算法 RFBnet实现思路 一.预测部分 1.主干网络介绍 2.从特征获取预测结果 3.预测结果的解码 4.在原图上进行绘制 二.训练部分 1.真实框的处理 2.利用处理完的真实框与对应图片的预测结果计算loss 训练自己的RFB模型 一.数据集的准备 二.数据集的处理 三.开始网络训练 四.训练结果预测 什么是RFBnet目标检测算法 RFBnet是SSD的一种加强版,主要是利用了膨胀卷积这一方法增大了感受野,相比于普通的ssd,RFBnet也是一种加强吧 RF
-
Python使用LSTM实现销售额预测详解
大家经常会遇到一些需要预测的场景,比如预测品牌销售额,预测产品销量. 今天给大家分享一波使用 LSTM 进行端到端时间序列预测的完整代码和详细解释. 我们先来了解两个主题: 什么是时间序列分析? 什么是 LSTM? 时间序列分析:时间序列表示基于时间顺序的一系列数据.它可以是秒.分钟.小时.天.周.月.年.未来的数据将取决于它以前的值. 在现实世界的案例中,我们主要有两种类型的时间序列分析: 单变量时间序列 多元时间序列 对于单变量时间序列数据,我们将使用单列进行预测. 正如我们所见,只有一列,
-
python编程之requests在网络请求中添加cookies参数方法详解
哎,好久没有学习爬虫了,现在想要重新拾起来.发现之前学习爬虫有些粗糙,竟然连requests中添加cookies都没有掌握,惭愧.废话不宜多,直接上内容. 我们平时使用requests获取网络内容很简单,几行代码搞定了,例如: import requests res=requests.get("https://cloud.flyme.cn/browser/index.jsp") print res.content 你没有看错,真的只有三行代码.但是简单归简单,问题还是不少的. 首先,这
-
基于pytorch的lstm参数使用详解
lstm(*input, **kwargs) 将多层长短时记忆(LSTM)神经网络应用于输入序列. 参数: input_size:输入'x'中预期特性的数量 hidden_size:隐藏状态'h'中的特性数量 num_layers:循环层的数量.例如,设置' ' num_layers=2 ' '意味着将两个LSTM堆叠在一起,形成一个'堆叠的LSTM ',第二个LSTM接收第一个LSTM的输出并计算最终结果.默认值:1 bias:如果' False',则该层不使用偏置权重' b_ih '和' b