Mysql数据库设计三范式实例解析
三范式
1NF:字段不可分;
2NF:有主键,非主键字段依赖主键;
3NF:非主键字段不能相互依赖;
解释:
1NF:原子性 字段不可再分,否则就不是关系数据库;
2NF:唯一性 一个表只说明一个事物;
3NF:每列都与主键有直接关系,不存在传递依赖;
第一范式(1NF)
即表的列的具有原子性,不可再分解,即列的信息,不能分解, 只要数据库是关系型数据库(mysql/oracle/db2/informix/sysbase/sql server),就自动的满足1NF。数据库表的每一列都是不可分割的原子数据项,而不能是集合,数组,记录等非原子数据项。如果实体中的某个属性有多个值时,必须拆分为不同的属性 。通俗理解即一个字段只存储一项信息。
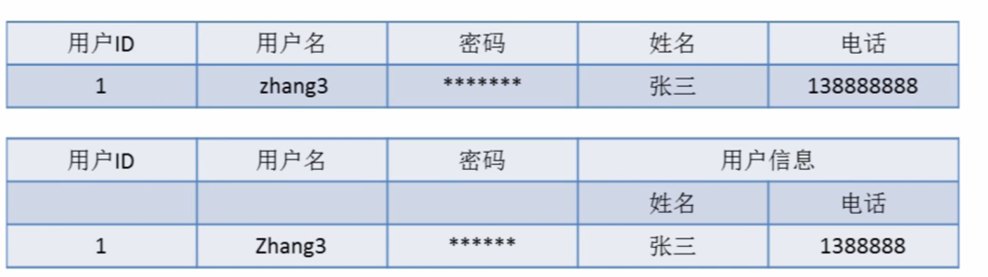
关系型数据库: mysql/oracle/db2/informix/sysbase/sql server 非关系型数据库: (特点: 面向对象或者集合) NoSql数据库: MongoDB/redis(特点是面向文档)
第二范式(2NF)
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要我们设计一个主键来实现(这里的主键不包含业务逻辑)。
即满足第一范式前提,当存在多个主键的时候,才会发生不符合第二范式的情况。比如有两个主键,不能存在这样的属性,它只依赖于其中一个主键,这就是不符合第二范式。通俗理解是任意一个字段都只依赖表中的同一个字段。(涉及到表的拆分)
看下面的学生选课表:
| 学号 | 课程 | 成绩 | 课程学分 |
|---|---|---|---|
| 10001 | 数学 | 100 | 6 |
| 10001 | 语文 | 90 | 2 |
| 10001 | 英语 | 85 | 3 |
| 10002 | 数学 | 90 | 6 |
| 10003 | 数学 | 99 | 6 |
| 10004 | 语文 | 89 | 2 |
表中主键为 (学号,课程),我们可以表示为 (学号,课程) -> (成绩,课程学分), 表示所有非主键列 (成绩,课程学分)都依赖于主键 (学号,课程)。 但是,表中还存在另外一个依赖:(课程)->(课程学分)。这样非主键列 ‘课程学分‘ 依赖于部分主键列 '课程‘, 所以上表是不满足第二范式的。
我们把它拆成如下2张表:
学生选课表:
| 学号 | 课程 | 成绩 |
|---|---|---|
| 10001 | 数学 | 100 |
| 10001 | 语文 | 90 |
| 10001 | 英语 | 85 |
| 10002 | 数学 | 90 |
| 10003 | 数学 | 99 |
| 10004 | 语文 | 89 |
课程信息表:
| 课程 | 课程学分 |
|---|---|
| 数学 | 6 |
| 语文 | 3 |
| 英语 | 2 |
那么上面2个表,学生选课表主键为(学号,课程),课程信息表主键为(课程),表中所有非主键列都完全依赖主键。不仅符合第二范式,还符合第三范式。
再看这样一个学生信息表:
| 学号 | 姓名 | 性别 | 班级 | 班主任 |
|---|---|---|---|---|
| 10001 | 张三 | 男 | 一班 | 小王 |
| 10002 | 李四 | 男 | 一班 | 小王 |
| 10003 | 王五 | 男 | 二班 | 小李 |
| 10004 | 张小三 | 男 | 二班 | 小李 |
上表中,主键为:(学号),所有字段 (姓名,性别,班级,班主任)都依赖与主键(学号),不存在对主键的部分依赖。所以是满足第二范式。
第三范式(3NF)
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主键字段。就是说,表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放(能尽量外键join就用外键join)。很多时候,我们为了满足第三范式往往会把一张表分成多张表。
即满足第二范式前提,如果某一属性依赖于其他非主键属性,而其他非主键属性又依赖于主键,那么这个属性就是间接依赖于主键,这被称作传递依赖于主属性。 通俗解释就是一张表最多只存两层同类型信息。
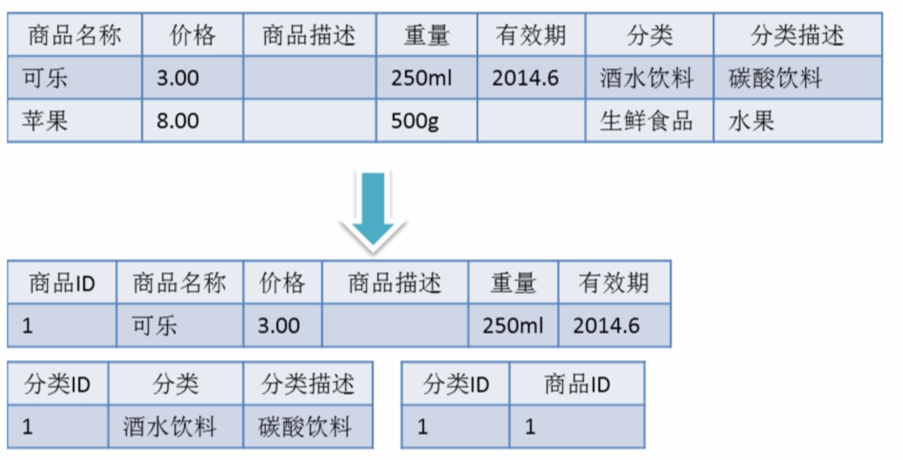
反三范式
没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,提高读性能,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,减少了查询时的关联,提高查询效率,因为在数据库的操作中查询的比例要远远大于DML的比例。但是反范式化一定要适度,并且在原本已满足三范式的基础上再做调整的。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
MySQL数据库对敏感数据加密及解密的实现方式
大数据时代的到来,数据成为企业最重要的资产之一,数据加密的也是保护数据资产的重要手段.本文主要在结合学习通过MySQL函数及Python加密方法来演示数据加密的一些简单方式. 1. 准备工作 为了便于后面对比,将各种方式的数据集存放在不同的表中. 创建原始明文数据表 /* 创建原始数据表 */ CREATE TABLE `f_user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAULT NULL, `tel` v
-
在python中使用pymysql往mysql数据库中插入(insert)数据实例
咱还是直接看代码吧! from pymysql import * def main(): # 创建connection连接 conn = connect(host='', port=3306, database='', user='', password='', charset='utf8') # 获取cursor对象 cs1 = conn.cursor() # 执行sql语句 query = 'insert into 表名(列名1, 列名2, 列名3, 列名4, 列名5, 列名6) value
-
Django中从mysql数据库中获取数据传到echarts方式
尝试了几种方法,感觉过于复杂,于是自己写了一个方法. (1)首先在要绘图的页面传入从数据库中提取的参数,这一步通过views可以实现: (2)然后是页面加载完成时执行的函数ready,调用方法f; (3)在函数f中获取参数,此时是string类型,需要将其转换为json对象,使用eval即可: (4)json对象的每一个元素均为string(可以使用typeof()判断),需要取出每一个成员将其转换为json对象: (5)在echarts模块函数中调用函数f,获取所需的数据 补充知识:djang
-
pycharm工具连接mysql数据库失败问题
在使用pycharm开发工具连接mysql数据库时提示错误,信息如下: Server returns invalid timezone. Go to 'Advanced' tab and set 'serverTimezone' property manually 提示信息返回无效的时区,这是由于MySQL默认的时区是UTC时区,比北京时间晚8个小时. 解决的方法是修改mysql时区的时长,连接上mysql后,操作命令如下: set global time_zone='+8:00'; 但可能这样
-

python3.6连接mysql数据库及增删改查操作详解
折腾好半天的数据库连接,由于之前未安装 pip ,而且自己用的python 版本为3.6. 只能用 pymysql 来连接数据库,下边 简单介绍一下 连接的过程,以及简单的增删改查操作. 1.通过 pip 安装 pymysql 进入 cmd 输入 pip install pymysql 回车等待安装完成: 安装完成后出现如图相关信息,表示安装成功. 2.测试连接 import pymysql #导入 pymysql 如果编译未出错,即表示 pymysql 安装成功 简单的增删改查操作 示
-
mysql数据库常见基本操作实例分析【创建、查看、修改及删除数据库】
本文实例讲述了mysql数据库常见基本操作.分享给大家供大家参考,具体如下: 本节相关: 创建数据库 查看数据库 修改数据库 删除数据库 首发时间:2018-02-13 20:47 修改: 2018-04-07:考虑到规范化,将所有语法中"关键字"变成大写;以及因为整理"mysql学习之路",移除字符集和校对集问题并归成一个新博文. 创建数据库 : 语法 : CREATE DATABASE 数据库名字[库选项]; 库选项说明 : 库选项是可选项,可以不写 ,如
-
如何更改MySQL数据库的编码为utf8mb4
utf8mb4编码是utf8编码的超集,兼容utf8,并且能存储4字节的表情字符. 采用utf8mb4编码的好处是:存储与获取数据的时候,不用再考虑表情字符的编码与解码问题. 更改数据库的编码为utf8mb4: 1. MySQL的版本 utf8mb4的最低mysql版本支持版本为5.5.3+,若不是,请升级到较新版本. 2. MySQL驱动 5.1.34可用,最低不能低于5.1.13 SHOW VARIABLES WHERE Variable_name LIKE 'character_set_%
-
Mysql数据库设计三范式实例解析
三范式 1NF:字段不可分; 2NF:有主键,非主键字段依赖主键; 3NF:非主键字段不能相互依赖; 解释: 1NF:原子性 字段不可再分,否则就不是关系数据库; 2NF:唯一性 一个表只说明一个事物; 3NF:每列都与主键有直接关系,不存在传递依赖; 第一范式(1NF) 即表的列的具有原子性,不可再分解,即列的信息,不能分解, 只要数据库是关系型数据库(mysql/oracle/db2/informix/sysbase/sql server),就自动的满足1NF.数据库表的每一列都是不可分割的
-
MySQL系列数据库设计三范式教程示例
目录 一.数据库设计三范式相关知识说明 1.什么是设计范式? 2.为什么要学习数据库的三个范式? 3.三范式都有哪些? 二.数据库表的经典设计方案 一对一怎么设计? 一.数据库设计三范式相关知识说明 1.什么是设计范式? 设计表的依据,按照这三个范式设计出来的表,不会出现数据的冗余. 2.为什么要学习数据库的三个范式? 数据库的设计范式是数据库设计所需要满足的规范,满足这些规范的数据库是简洁的.结构明晰的,同时,不会发生插入(insert).删除(delete)和更新(update)操作异常.反
-
Python3.6简单的操作Mysql数据库的三个实例
安装pymysql 参考:https://github.com/PyMySQL/PyMySQL/ pip install pymsql 实例一 import pymysql # 创建连接 # 参数依次对应服务器地址,用户名,密码,数据库 conn = pymysql.connect(host='127.0.0.1', user='root', passwd='123456', db='demo') # 创建游标 cursor = conn.cursor(cursor=pymysql.cursor
-
PHP连接MySQL数据库的三种方式实例分析【mysql、mysqli、pdo】
本文实例讲述了PHP连接MySQL数据库的三种方式.分享给大家供大家参考,具体如下: PHP与MySQL的连接有三种API接口,分别是:PHP的MySQL扩展 .PHP的mysqli扩展 .PHP数据对象(PDO) ,下面针对以上三种连接方式做下总结,以备在不同场景下选出最优方案. PHP的MySQL扩展是设计开发允许php应用与MySQL数据库交互的早期扩展.MySQL扩展提供了一个面向过程的接口,并且是针对MySQL4.1.3或者更早版本设计的.因此这个扩展虽然可以与MySQL4.1.3或更
-
MySQL数据库设计之利用Python操作Schema方法详解
弓在箭要射出之前,低声对箭说道,"你的自由是我的".Schema如箭,弓似Python,选择Python,是Schema最大的自由.而自由应是一个能使自己变得更好的机会. Schema是什么? 不管我们做什么应用,只要和用户输入打交道,就有一个原则--永远不要相信用户的输入数据.意味着我们要对用户输入进行严格的验证,web开发时一般输入数据都以JSON形式发送到后端API,API要对输入数据做验证.一般我都是加很多判断,各种if,导致代码很丑陋,能不能有一种方式比较优雅的验证用户数据呢
-
计算机二级考试MySQL常考点 8种MySQL数据库设计优化方法
MySQL数据库设计的8种优化方法,具体内容如下 1.选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快.因此,在创建表的时候,为了获得更好的性能,我们可以将表中字段的宽度设得尽可能小.例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很好的完成任务了.同样的,如果可以的话,我们应该使用MEDIUMINT而不是B
-
Python操作MySQL数据库的三种方法总结
1. MySQLdb 的使用 (1) 什么是MySQLdb? MySQLdb 是用于 Python 连接 MySQL 数据库的接口,它实现了 Python 数据库 API 规范 V2.0,基于 MySQL C API 上建立的. (2) 源码安装 MySQLdb: https://pypi.python.org/pypi/MySQL-python $ tar zxvf MySQL-python-*.tar.gz $ cd MySQL-python-* $ python setup.py buil
-
Django数据库表反向生成实例解析
本文我们研究下如何在django中反向生成mysql model代码,接下来我们看看具体介绍. 我们在展示django ORM反向生成之前,我们先说一下怎么样正向生成代码. 正向生成,指的是先创建model.py文件,然后通过django内置的编译器,在数据库如mysql中创建出符合model.py的表. 反向生成,指的是先在数据库中create table,然后通过django内置的编译器,生成model代码. 1.准备工作 创建django工程以及app 创建django工程,名字是hell
-
MySQL数据库设计概念及多表查询和事物操作
目录 数据库设计概念 数据库设计简介 表关系(多对多) 表关系(一对多) 表关系之一对一 多表查询 笛卡尔积现象 内连接查询 嵌套查询(子查询) 事务操作 事务的概念 手动提交事务 自动提交事务 事务原理和四大特征 事务原理 事务的四大特征 事务的并发访问引发的三个问题(面试) 事务的隔离级别 数据库设计概念 数据库设计简介 1.数据库设计概念 数据库设计就是根据业务系统具体需求,结合我们所选用的DBMS,为这个业务系统构造出最优的数据存储模型. 建立数据库中的表结构以及表与表之间的关联关系的过
-
一文详解PHP连接MySQL数据库的三种方式
目录 1.MySQL扩展 2.mysqli扩展 3.PDO扩展 知识点补充 PHP与MySQL的连接有三种API接口,分别是:PHP的MySQL扩展 .PHP的mysqli扩展 .PHP数据对象(PDO). 1.MySQL扩展 PHP 的 MySQL 扩展是设计开发允许 PHP 应用与 MySQL 数据库交互的早期扩展.MySQL 扩展提供了一个面向过程的接口,由于不支持后期MySQL服务端提供的一些特性.且太古老,又不安全,所以已被后来的 mysqli 完全取代: 使用方式如下 //自 PHP