在python3中使用shuffle函数要注意的地方
1 shuffle函数与其他函数不一样的地方
shuffle函数没有返回值!shuffle函数没有返回值!shuffle函数没有返回值!仅仅是实现了对list元素进行随机排序的一种功能
请看下面的坑
1.1 误认为shuffle函数会有一个返回值的错误例子
num1 = list(range(1,39526)) #产生1-39525的数 num2 = random.shuffle(num1) num3 = num2[0:30000] #取前30000个行号的元素 num4 = num2[30000:39524] #取到后面9525个元素
执行结果:
File "E:/pythonProj/test2/readDatasetCSVfile.py", line 122, in <module> num3 = num2[0:30000] #取前30000个行号的元素 TypeError: 'NoneType' object is not subscriptable
从这个错误中我们也可以看出来,指明obiect没有类型,其实现在这个num2中是null,什么也没有,因为shuffle没有返回值,所以自然会报这种类型的错误。
1.2 正确使用shuffle函数的例子
num1 = list(range(1,39526)) #产生1-39525的数 random.shuffle(num1) #注意shuffle没有返回值,该函数完成一种功能,就是对list进行排序打乱 num3 = num1[0:30000] #取前30000个行号的元素 num4 = num1[30000:39524] #取到后面9525个元素
这个时候才顺利运行通过!
补充拓展:对python中使用shuffle和permutation对列表进行随机洗牌的区别
函数:shuffle将列表的所有元素随机排序,不生成新的数组返回
示例:
import random
list = [20, 16, 10, 5];
random.shuffle(list) # 参数只能是列表,元组、字典、字符串会报错
print("随机排序列表 : ", list)
random.shuffle(list)
print("随机排序列表 : ", list)
执行结果:

函数:permutation 返回排列范围的随机列表或返回一个新的打乱顺序的数组,并不改变原来的数组,
如果输入是一个多维数组,则它只沿其第一个索引进行无序排列
示例:
import numpy as np
new_arr = np.random.permutation(10)
print(new_arr)
new_arr1 = np.random.permutation([1, 4, 9, 12, 15]) # 参数为列表
print(new_arr1)
arr = np.arange(9).reshape((3, 3))
new_arr2 = np.random.permutation(arr)
print(new_arr2)
new_arr3 = np.random.permutation([{"a": 1, "b": 2}, [{"e": 5}, {"c": 3}, {"d": 4}], [{"f": 6}, {"g": 8}]])# 子数组中的排列顺序不变
print(new_arr3)
new_arr4 = np.random.permutation((1, 4, 9, 12, 15)) #可以传元组参数
print(new_arr4)
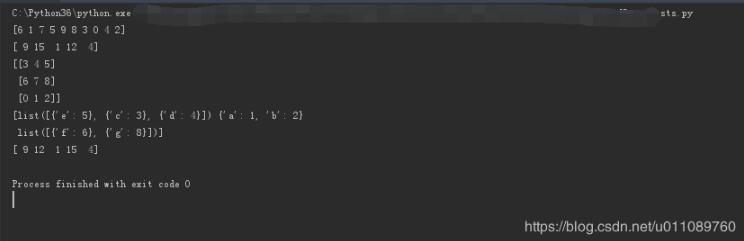
import numpy as np
new_arr = np.random.permutation(10)
print(new_arr)
new_arr1 = np.random.permutation([1, 4, 9, 12, 15])
print(new_arr1)
arr = np.arange(9).reshape((3, 3))
new_arr2 = np.random.permutation(arr)
print(new_arr2)
new_arr3 = np.random.permutation([{"a": 1, "b": 2}, [{"e": 5}, {"c": 3}, {"d": 4}], [{"f": 6}, {"g": 8}]]) # 子数组中的排列顺序不变
print(new_arr3)
执行结果:
以上这篇在python3中使用shuffle函数要注意的地方就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
赞 (0)