MySQL详解如何优化查询条件
目录
- 前言
- 现状
- 问题一
- 多表联查
- 单表查询
- 结论
- 问题二
- 多表联查
- 单表查询
- 问题
- 如何解决
前言
技术能解决的事情改技术
技术解决不了的事情该需求
现状
假设我们目前有两张表
业务表 书( t_a_book ) 阅读历史记录表 (t_r_book_history) 用户表
其两张表的数据逻辑如下
t_a_book
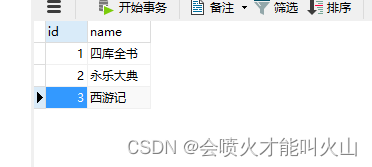
t_r_book_history
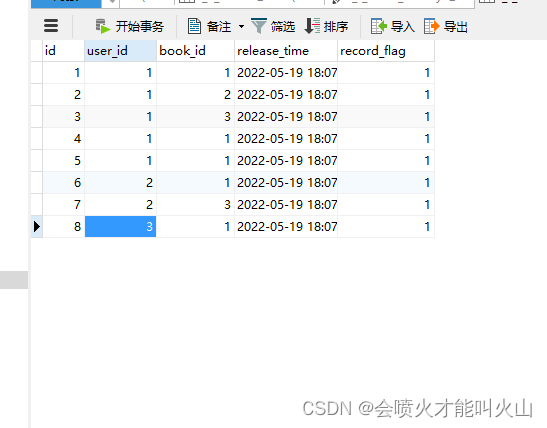
t_a_user
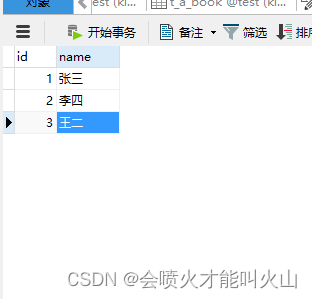
当然了,我们假设当前的数据量并不只是我们眼前看到的这几条数据,而是线上真实情况。
每张表至少都是10w+起步
问题一
这时候,我们需要面临第一个业务问题,
我们需要做一个报表,显示用户阅读图书的记录,并显示用户名,用户号,书名
这时候我们如何设计查询SQL
多表联查
SELECT * FROM t_r_book_history bh LEFT JOIN t_a_user u ON bh.user_id = u.id LEFT JOIN t_a_book b ON bh.book_id = b.id WHERE bh.record_flag = 1 ORDER BY bh.release_time DESC LIMIT 10;
查询出来的结果为

其逻辑为
- 数据库根据release_time倒序查询数据表,取出倒序的数据
- 根据左连接获取 用户信息
- 根据左连接获取 图书信息
单表查询
如果此时我们选择化繁为简,使用单表的查询方法,来查询数据其SQL为
SELECT * FROM t_r_book_history bh WHERE bh.record_flag = 1 ORDER BY bh.release_time DESC LIMIT 10; // 用户信息 SELECT * FROM t_a_user u WHERE u.id IN (); // 图书信息 SELECT * FROM t_a_books b WHERE u.id IN ();
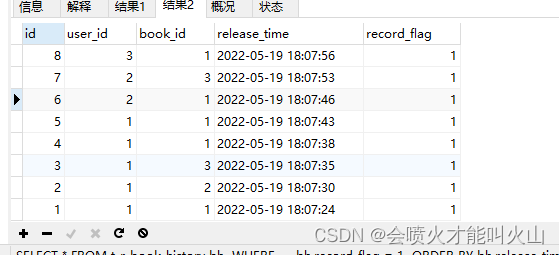
其数据逻辑与多表联查一致,唯一不同的便是需要查询三次
结论
我们可以看,当前两种查询方式的逻辑来看。
主要会存在的流量压力在与 t_r_book_history 这张表上面
当数据量大的时候,我们只需要根据release_time 做索引,简化这一步的操作。
后续都可以使用主键来简化操作
由此来看,两个语句其实在本质上没有明显的快慢之分
问题二
现在我们需要增加两个查询条件
- 用户名称,支持模糊查询
- 书名信息,支持模糊查询
如果这时候,我们如何编写SQL
多表联查
如果我们使用多表联查的思路来填写SQL
SELECT * FROM t_r_book_history bh LEFT JOIN t_a_user u ON bh.user_id = u.id LEFT JOIN t_a_book b ON bh.book_id = b.id WHERE bh.record_flag = 1 AND b.name like "四%" and u.name like "张%" ORDER BY bh.release_time DESC LIMIT 10;
显示的数据

其逻辑为
- 查询用户表,根据其用户名称进行模糊查询
- 查询书表,根据书名进行模糊查询
- 根据用户主键,书籍主键作为查询条件来进行查询
单表查询
SELECT * FROM t_a_user WHERE user_name LIKE "张%" SELECT * FROM t_a_book WHERE user_name LIKE "四%" SELECT * FROM t_r_book_history bh WHERE bh.record_flag = 1 ORDER BY bh.release_time DESC LIMIT 10; // 用户信息 SELECT * FROM t_a_user u WHERE u.id IN (); // 图书信息 SELECT * FROM t_a_books b WHERE u.id IN ();
其查询逻辑与多表联查一致
问题
现在主要的问题在于 , t_a_user , t_a_book , t_r_book_history 这三张表都是大表,
我们使用的查询条件也十分的模糊
简单的说 , 无论我们使用哪种方法, 都有可能会出现几十万个符合的结果
因此,我们无论使用哪种编写方法 , 这个SQL都是不可行的
如何解决
文章写到这里,我们会发现这个问题,已经不能停留再技术成面的问题。
因此,我们就只能修改需求
我们这里的问题 , 是这两张表的查询条件。他十分的模糊,我们无法将范围限制在几条,几十条,甚至几百条内。
既然这样,我们就只能跟需求方表示,这个查询条件必须使用十分“明确”的数据
例如对于用户,我们常常能用什么来明确指向一个用户呢?
id,数据主键,手机号码
我们如何确定一本书呢?我们可以用一个ISBN
修改这两个查询条件,才能将这个不能解决的问题,修改为解决
但是,有人说,我们是技术。不能对产品提这样的想法,
但是我想说,你是打算在将来来查询卡半分钟的时候说,说服所有人这个东西不关我的事
还是说,在未开发前说服产品
到此这篇关于MySQL详解如何优化查询条件的文章就介绍到这了,更多相关MySQL查询条件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解Mysql查询条件中字符串尾部有空格也能匹配上的问题
一.表结构 TABLE person id name 1 你 2 你(一个空格) 3 你(二个空格) 二.查询与结果 select * from person where `name` = ? 无论 ? = "你 + 几个空格",都会检索出全部三个结果. 三.原因 MySQL 校对规则属于PADSPACE,会忽略尾部空格 针对的是 varchar char text -- 等文本类的数据类型 此为 SQL 标准化行为.无需要设置也无法改变. 四.想要精确查询怎么办? 方法一:like
-

mysql根据json字段内容作为查询条件(包括json数组)检索数据
最近用到了mysql5.7的json字段的检索查询,发现挺好用的,记录一下笔记我们有一个日志表,里面的data字段是保存不同对象的json数据,遇到想根据里面的json的字段内容作为条件查询的情况 mysql根据json字段的内容检索查询数据 使用 字段->'$.json属性'进行查询条件 使用json_extract函数查询,json_extract(字段,"$.json属性") 根据json数组查询,用JSON_CONTAINS(字段,JSON_OBJECT('json属性'
-
MySQL查询条件中放置on和where的区别分析
导语 今天在写 SQL 的时候,遇到一个问题.需求是这样的,查询数据,按照评分倒序.近一周访问量倒序,这样进行排序.问题是常规的写法,将 day >= xxx 条件放到 where 中, 如果某些数据近一周没有访问量,那么这条数据就查不出来.解决办法呢,就是将条件放到 LEFT JOIN 中. MySQL 语句执行顺序 首先先说明一个概念,MySQL 语句执行的顺序,并不是按照 SQL 语句的顺序.下面是示例 SQL SELECT DISTINCT < select_list > FRO
-
MySQL查询条件常见用法详解
本文实例讲述了MySQL查询条件常见用法.分享给大家供大家参考,具体如下: 条件 使用where子句对表中的数据筛选,结果为true的行会出现在结果集中 语法如下: select * from 表名 where 条件; 例: select * from students where id=1; where后面支持多种运算符,进行条件的处理 比较运算符 逻辑运算符 模糊查询 范围查询 空判断 比较运算符 等于: = 大于: > 大于等于: >= 小于: < 小于等于: <= 不等于:
-
MySQL查询条件中in会用到索引吗
当用人问你MySQL 查询条件中 in 会不会用到索引,你该怎么回答? 答案:可能会用到索引 动手来测试下 1.创建一张表,给字段port建立索引 CREATE TABLE `pre_request_logs_20180524` ( `id` int(11) NOT NULL AUTO_INCREMENT, `ip` char(16) NOT NULL COMMENT '代理IP', `port` int(8) NOT NULL COMMENT '端口号', `status` enum('成功'
-
mysql查询条件not in 和 in的区别及原因说明
先写一个SQL SELECT DISTINCT from_id FROM cod WHERE cod.from_id NOT IN (37, 56, 57) 今天在写SQL的时候,发现这个查的结果不全,少了NULL值的情况,not in 的时候竟然把null也排除了 用 in 的时候却没有包含null 感觉是mysql设计的不合理 因为一直认为in 和 not in 正好应该互补才是,就像这样查的应该是全部的一样: SELECT DISTINCT from_id FROM cod WHERE c
-
MySQL详解如何优化查询条件
目录 前言 现状 问题一 多表联查 单表查询 结论 问题二 多表联查 单表查询 问题 如何解决 前言 技术能解决的事情改技术 技术解决不了的事情该需求 现状 假设我们目前有两张表 业务表 书( t_a_book ) 阅读历史记录表 (t_r_book_history) 用户表 其两张表的数据逻辑如下 t_a_book t_r_book_history t_a_user 当然了,我们假设当前的数据量并不只是我们眼前看到的这几条数据,而是线上真实情况. 每张表至少都是10w+起步 问题一 这时候,我
-
Python 操作MySQL详解及实例
Python 操作MySQL详解及实例 使用Python进行MySQL的库主要有三个,Python-MySQL(更熟悉的名字可能是MySQLdb),PyMySQL和SQLAlchemy. Python-MySQL资格最老,核心由C语言打造,接口精炼,性能最棒,缺点是环境依赖较多,安装复杂,近两年已停止更新,只支持Python2,不支持Python3. PyMySQL为替代Python-MySQL而生,纯python打造,接口与Python-MySQL兼容,安装方便,支持Python3. SQLA
-
Spring data jpa的使用与详解(复杂动态查询及分页,排序)
一. 使用Specification实现复杂查询 (1) 什么是Specification Specification是springDateJpa中的一个接口,他是用于当jpa的一些基本CRUD操作的扩展,可以把他理解成一个spring jpa的复杂查询接口.其次我们需要了解Criteria 查询,这是是一种类型安全和更面向对象的查询.而Spring Data JPA支持JPA2.0的Criteria查询,相应的接口是JpaSpecificationExecutor. 而JpaSpecifica
-
详解Pymongo常用查询方法总结
Python 直接连接mongodb数据库进行查询操作 1.安装所需模块 使用到的是pymongo模块,安装方法:pip install pymongo 2.环境验证 3.连接数据库 import pymongo def operating_mongodb(): client = pymongo.MongoClient('ip_address', port) db_auth = client.database db_auth.authenticate("username", "
-
详解CocosCreator优化之DrawCall
前言 在游戏开发中,DrawCall 作为一个非常重要的性能指标,直接影响游戏的整体性能表现. 无论是 Cocos Creator.Unity.Unreal 还是其他游戏引擎,只要说到游戏性能优化,DrawCall 都是绝对少不了的一项. 本文将会介绍什么是 DrawCall,为什么要减少 DrawCall 以及在 Cocos Creator 项目中如何减少 DrawCall 来提升游戏性能. 什么是 DrawCall DrawCall就是CPU调用图形库(比如DirectX或OpenGL)的图
-
详解PHP优化巨量关键词的匹配
问题由来 前些天工作中遇到一个问题: 有 60万 条短消息记录日志,每条约 50 字,5万 关键词,长度 2-8 字,绝大部分为中文.要求将这 60万 条记录中包含的关键词全部提取出来并统计各关键词的命中次数. 原始 - grep 设计 一开始接到任务的时候,我的小心思立刻转了起来,日志 + 关键词 + 统计,我没有想到自己写代码实现,而是首先想到了 linux 下常用的日志统计命令 grep. grep命令的用法不再多提,使用 grep 'keyword' | wc -l 可以很方便地进行统计
-
ubuntu下apt-get安装和彻底卸载mysql详解
1.安装mysql: udo apt-get install mysql-server udo apt-get install mysql-client udo apt-get install php5-mysql(用于连接php和mysql) 查看mysql是否运行 aux | grep mysql 启动命令 /etc/init.d/mysql start 2.删除mysql 按顺序执行以下命令 udo apt-get autoremove --purge mysql-server-5.0 u
-
详解dex优化对Arouter查找路径的影响
目录 一.前言 1.1 APK的编译和打包流程 1.2 dex文件的应用场景 二.dex到vdex.odex 2.1 ART预优化 2.2 ART的运行方式 2.3 vdex.odex的作用 2.4 vdex.odex与classes.dex关系 三.Arouter是什么 四.踩坑 4.1 现象 4.2 解决方案 五.总结 一.前言 疑问:dex文件是什么?dex文件优化又是什么? dex文件优化会给项目带来什么问题,怎么解决这些问题? 1.1 APK的编译和打包流程 1.通过aapt打包资源文
-
Nginx配置文件详解以及优化建议指南
目录 1.概述 2.nginx.conf 1)配置文件位置 2)worker_processes 3)events 4)include 5)sendfile 和 tcp_nopush 6)keepalive_timeout 7)gzip 8)server 9)location的匹配规则详解 3.综述 1.概述 今天来详解一下Nginx的配置文件,以及给出一些配置建议,希望能对大家有所帮助. 2.nginx.conf 1)配置文件位置 nginx 安装目录的 conf 文件夹下,例如:/usr/l
-
MySQL详解进行JDBC编程与增删改查方法
目录 Java的数据库编程JDBC 概念 使用步骤 利用JDBC实现增加(insert) 利用JDBC实现删除(delete) 利用JDBC实现修改(update) 利用JDBC实现查找(select) Java的数据库编程JDBC 概念 JDBC是一种用于执行sql语句的Java API,他是java中的数据库连接规范,这个API由一些接口和类组成.它为java开发人员操作数据库提供了一个标准的API,可以为多种关系数据库提供统一访问 本质是通过代码自己实现一个MySQL客户端,通过网络和服务