Python数据获取实现图片数据提取
目录
- 一、利用exifread提取图片的EXIF信息
- 二、循环遍历图片信息
比如我随便从手机上传一张图片到我的电脑里,通过python可以获取这张照片的所有信息。如果是数码相机拍摄的照片,我们在属性里可以找到照片拍摄的时间,拍摄的经纬度,海拔高度。
那么这些信息有什么作用呢?
有很多功能…比如用户画像,客户信息标签设定等等,用户喜欢拍摄照片的季节,时间点,所使用的相机的参数指标可以反应出一个人的金钱状况,对于其拍摄的内容,我们可以通过AI的方式对照片的内容信息进行提取,从而判断一个人的兴趣爱好。
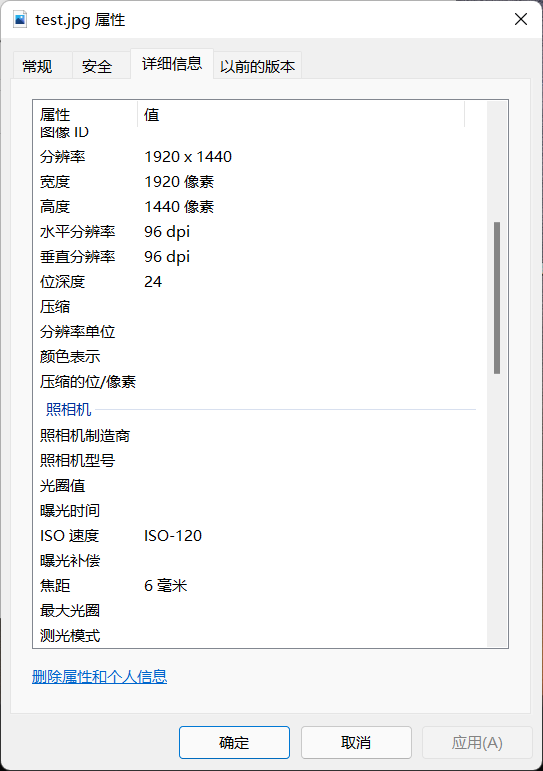
一、利用exifread提取图片的EXIF信息
exifread介绍:
EXIF信息,是可交换图像文件的缩写,是专门为数码相机的照片设定的,可以记录数码照片的属性信息和拍摄数据。EXIF可以附加于JPEG、TIFF、RIFF等文件之中,为其增加有关数码相机拍摄信息的内容和索引图或图像处理软件的版本信息。
首先要安装ExifRead:
pip3 install ExifRead
pic=r'D:\S072003Python\input\test\test.jpg' import exifread f = open(pic, 'rb') tags = exifread.process_file(f) print(tags) #内有相机型号,拍摄时间,经纬度等

tags
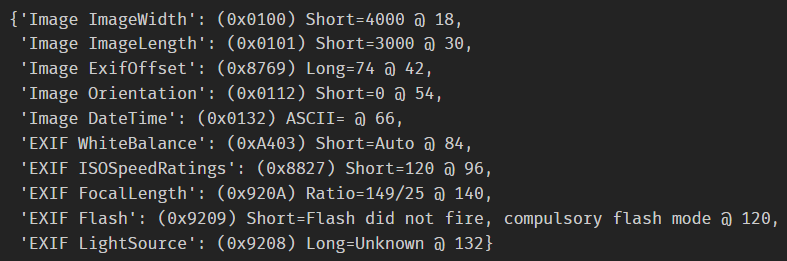
print(tags)和tags获取数据的格式不同。
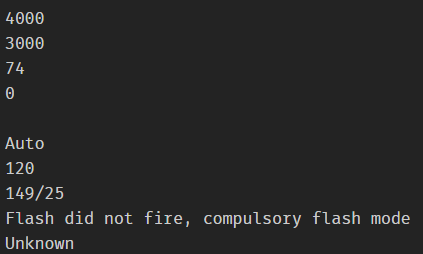
tags['Image ImageWidth'] tags['Image ImageLength'] tags['Image ExifOffset'] tags['Image Orientation'] tags['Image DateTime'] tags['EXIF WhiteBalance'] tags['EXIF ISOSpeedRatings'] tags['EXIF FocalLength'] tags['EXIF Flash'] tags['EXIF LightSource']
exifcolumns=['Image ImageWidth','Image ImageLength','Image ExifOffset','Image Orientation','Image DateTime','EXIF WhiteBalance','EXIF ISOSpeedRatings','EXIF FocalLength','EXIF Flash','EXIF LightSource'] # 把要提取的数据都封装在列表当中
for i in range(len(exifcolumns)):
print(tags[exifcolumns[i]]) # 使用循环拿到所有的数据
二、循环遍历图片信息
任务:一次性获得以下图片的"Image ImageWidth"信息。写一个循环即可:
import exifread
import os
import pandas as pd
import glob
pic_list=glob.glob(r'C:\Users\Lenovo\Pictures\Saved Pictures\*.jpg') # 如果是png,jpeg,bmp等数据格式,如何设置?
for i in pic_list:
fr=open(i,'rb')
tags=exifread.process_file(fr)
if "Image ImageWidth" in tags: # 条件判断,因为并不是所有的照片都有"Image ImageWidth"
print(tags["Image ImageWidth"])
# 经纬度获取
import exifread
import os
import pandas as pd
import glob
pic_list=glob.glob(r'C:\Users\Lenovo\Pictures\Saved Pictures\*.jpg')
latlonlists=[]
for i in pic_list:
fr=open(i,'rb')
tags=exifread.process_file(fr)
if "GPS GPSLatitude" in tags: # 条件判断,因为并不是所有的照片都有"Image ImageWidth"
# 维度转换
lat_ref=tags["GPS GPSLatitudeRef"]
lat=tags["GPS GPSLatitude"].printable[1:-1].replace(" ","").replace("/",",").split(",")
lat=float(lat[0])+float(lat[1])/60+float(lat[2])/3600
if lat_ref in ["N"]: # 表示是南半球的数据
lat=lat*(-1)
# 经度转换
lon_ref=tags["GPS GPSLongitudeRef"]
lon=tags["GPS GPSLongitude"].printable[1:-1].replace("","").replace("/",",").split(",")
lon=float(lon[0])+float(lon[1])/60+float(lon[2])/3600
if lon_ref in ["E"]: # 表示是西半球的数据
lon=lon*(-1)
print("维度:",lat,"经度:",lon)
latlonlist=[lat,lon]
latlonlists.append(latlonlist)
到此这篇关于Python数据获取实现图片数据提取的文章就介绍到这了,更多相关Python 图片数据提取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 实现提取某个索引中某个时间段的数据方法
如下所示: from elasticsearch import Elasticsearch import datetime import time import dateutil.parser class App(object): def __init__(self): pass def _es_conn(self): es = Elasticsearch() return es def get_data(self, day,start,end): index_ = "gather-apk-20
-
Python JSON格式数据的提取和保存的实现
环境:python-3.6.5 JSON JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写.同时也方便了机器进行解析和生成.适用于进行数据交互的场景,比如网站前台与后台之间的数据交互. Python中自带了json模块,直接import json即可使用 官方文档:https://docs.python.org/3/library/json.html Json在线解析网站:https://www.json.cn/# j
-

Python进行数据提取的方法总结
准备工作 首先是准备工作,导入需要使用的库,读取并创建数据表取名为loandata. import numpy as np import pandas as pd loandata=pd.DataFrame(pd.read_excel('loan_data.xlsx')) 设置索引字段 在开始提取数据前,先将member_id列设置为索引字段.然后开始提取数据. Loandata = loandata.set_index('member_id') 按行提取信息 第一步是按行提取数据,例如提取某个
-
python 数据提取及拆分的实现代码
K线数据提取 依据原有数据集格式,按要求生成新表: 1.每分钟的close数据的第一条.最后一条.最大值及最小值, 2.每分钟vol数据的增长量(每分钟vol的最后一条数据减第一条数据) 3.汇总这些信息生成一个新表 (字段名:['time','open','close','high','low','vol']) import pandas as pd import time start=time.time() df=pd.read_csv('data.csv') df=df.drop('id'
-
python提取具有某种特定字符串的行数据方法
今天又帮女朋友处理了一下,她的实验数据,因为python是一年前经常用,最近找工作,用的是c,c++,python的有些东西忘记了,然后就一直催我,说我弄的慢,弄的慢,你自己弄啊,烦不烦啊,逼逼叨叨的,最后还不是我给弄好的?呵呵 好的,数据是这样的,我截个图 我用红括号括起来的,就是我所要提取的数据 其中lossstotal.txt是我要提取的原始数据,考虑两种方法去提取,前期以为所要提取行的数据是有一定规律的,后来发现,并不是,所以,我考虑用正则来提取,经过思考以后,完成了数据的提取,如下午所
-
python提取包含关键字的整行数据方法
问题描述: 如下图所示,有一个近2000行的数据表,需要把其中含有关键字'颈廓清术,中央组(VI组)'的数据所在行都都给抽取出来,且提取后的表格不能改变原先的顺序. 问题分析: 一开始想用excel的筛选功能,但是发现只提供单列筛选,由于关键词在P,S,V,Y,AB列都有,故需要筛选5次.但是筛选完后再整合再一起的表格顺序就乱了,而原先的表格排序规律不可知,无法通过简单的排序实现.于是决定用Python写个代码来解决这个问题~ python生成的表格是这个样子滴^_^那些空白的行就是不符合要求的
-
python 将json数据提取转化为txt的方法
如下所示: #-*- coding: UTF-8 -*- import json import pymysql import os import sys # 数据类型 # { # "name": "score.networkQuality", # "index": true, # "view": "app/views/score/networkQuality.tmpl.html", # "file
-
Python数据获取实现图片数据提取
目录 一.利用exifread提取图片的EXIF信息 二.循环遍历图片信息 比如我随便从手机上传一张图片到我的电脑里,通过python可以获取这张照片的所有信息.如果是数码相机拍摄的照片,我们在属性里可以找到照片拍摄的时间,拍摄的经纬度,海拔高度.那么这些信息有什么作用呢? 有很多功能…比如用户画像,客户信息标签设定等等,用户喜欢拍摄照片的季节,时间点,所使用的相机的参数指标可以反应出一个人的金钱状况,对于其拍摄的内容,我们可以通过AI的方式对照片的内容信息进行提取,从而判断一个人的兴趣爱好.
-
Python编写一个验证码图片数据标注GUI程序附源码
做验证码图片的识别,不论是使用传统的ORC技术,还是使用统计机器学习或者是使用深度学习神经网络,都少不了从网络上采集大量相关的验证码图片做数据集样本来进行训练. 采集验证码图片,可以直接使用Python进行批量下载,下载完之后,就需要对下载下来的验证码图片进行标注.一般情况下,一个验证码图片的文件名就是图片中验证码的实际字符串. 在不借助工具的情况下,我们对验证码图片进行上述标注的流程是: 1.打开图片所在的文件夹: 2.选择一个图片: 3.鼠标右键重命名: 4.输入正确的字符串: 5.保存 州
-
Python抓取今日头条街拍图片数据
目录 (1)抓取今日头条街拍图片 (2)分析今日头条街拍图片结构 (3)按功能不同编写不同方法组织代码 (4)抓取20page今日头条街拍图片数据 (1)抓取今日头条街拍图片 (2)分析今日头条街拍图片结构 keyword: 街拍 pd: atlas dvpf: pc aid: 4916 page_num: 1 search_json: {"from_search_id":"20220104115420010212192151532E8188","orig
-
利用Python对文件夹下图片数据进行批量改名的代码实例
1. 前言 我们最近在做一个使用flask 模拟 instagram 的图片分享网站, 需要一些基本的图片数据, 我们这里采用的是本地提供, 但是,使用爬虫从网上爬下来的图片,名字都是乱七八糟的,不利于编程,这里就需要对他们进行批量改名操作. 2. 基本思路 使用python 的os 模块,对文件夹进行遍历(listdir), 同时使用rename 进行改名操作 3. 实现效果 4. 实现代码 代码非常简单 # -*- coding:utf8 -*- import os class BatchR
-
利用python对Excel中的特定数据提取并写入新表的方法
最近刚开始学python,正好实习工作中遇到对excel中的数据进行处理的问题,就想到利用python来解决,也恰好练手. 实际的问题是要从excel表中提取日期.邮件地址和时间,然后统计在一定时间段内某个人在某个项目上用了多少时间,最后做成一张数据透视表(这是问题的大致意思). 首先要做的就是数据提取了,excel中本身有一个text to column的功能,但是对列中规律性不好的数据处理效果很差,不能分割出想要的数据,所以我果断选择用python来完成. 要用的库一个是对excel读写处理
-
python读取raw binary图片并提取统计信息的实例
用python语言读取二进制图片文件,并提取非零数据统计信息(例如:max,min,skewness and kurtosis) python新手,注释较少,欢迎指教 import struct import math import numpy import scipy.stats filename = input('enter file name') f = open(filename, 'rb') f.seek(0, 0) c = 0 numOfZero = 0 s = 0 num = []
-
Python数据提取-lxml模块
知识点: 了解lxml模块和xpath语法的关系: 了解lxml模块的使用场景: 了解lxml模块的安装: 了解 谷歌浏览器xpath helper插件的安装和使用: 掌握xpath语法-基础节点选择语法: 掌握 xpath语法 -节点修饰语法: 掌握xpath语法 - 其他常用语法: 掌握 lmxl模块中使用xpath语法定位元素提取数学值或文本内容: 掌握lxml模块etree.tostring函数的使用: 1.了解lxml模块和xpath语法 对html或xml形式的文本提取特定的内容,就
-
Python探针完成调用库的数据提取
目录 1.简单粗暴的方法--对mysql库进行封装 2.Python的探针 3.制作探针模块 4.直接替换方法 5.总结 1.简单粗暴的方法--对mysql库进行封装 要统计一个执行过程, 就需要知道这个执行过程的开始位置和结束位置, 所以最简单粗暴的方法就是基于要调用的方法进行封装,在框架调用MySQL库和MySQL库中间实现一个中间层, 在中间层完成耗时统计,如: # 伪代码 def my_execute(conn, sql, param): # 针对MySql库的统计封装组件 with M