PyHacker实现网站后台扫描器编写指南
目录
- 00x1:模块
- 00x2:请求基本代码
- 00x3:设置
- 00x4:200页面处理
- 00x5:保存结果
- 0x06:完整代码
包括如何处理假的200页面/404智能判断等
喜欢用Python写脚本的小伙伴可以跟着一起写一写呀。
编写环境:Python2.x
00x1:模块
需要用到的模块如下:
import request
00x2:请求基本代码
先将请求的基本代码写出来:
import requests
def dir(url):
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'}
req = requests.get(url=url,headers=headers)
print req.status_code
dir('http://www.hackxc.cc')

00x3:设置
设置超时时间,以及忽略不信任证书
import urllib3 urllib3.disable_warnings() req = requests.get(url=url,headers=headers,timeout=3,verify=False)
再加个异常处理
调试一下
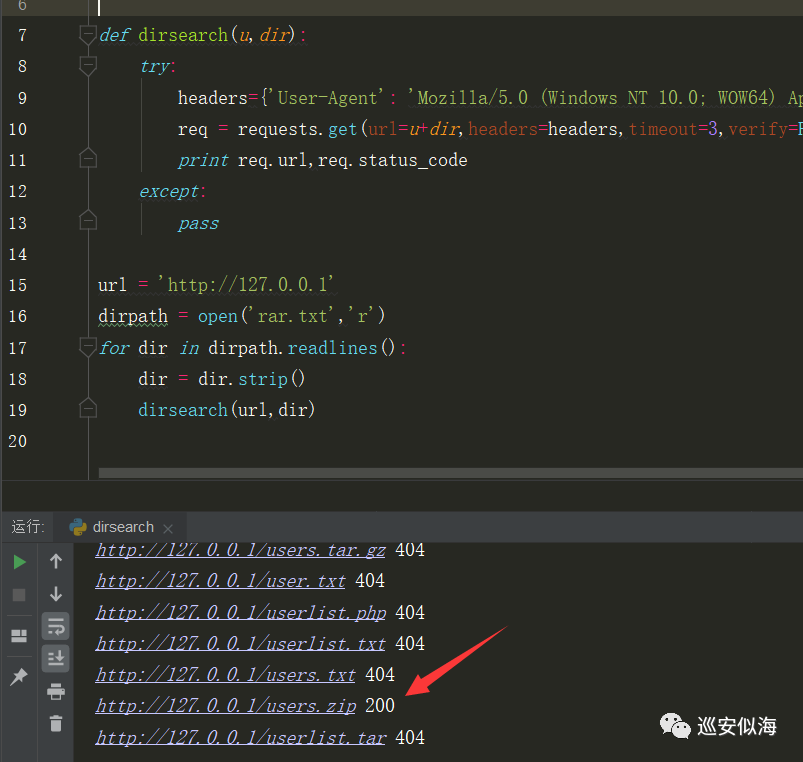
再进行改进,如果为200则输出
if req.status_code==200:
print "[*]",req.url
00x4:200页面处理
难免会碰到假的200页面,我们再处理一下
处理思路:
首先访问hackxchackxchackxc.php和xxxxxxxxxx记录下返回的页面的内容长度,然后在后来的扫描中,返回长度等于这个长度的判定为404
def dirsearch(u,dir):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'}
#假的200页面进行处理
hackxchackxchackxc = '/hackxchackxchackxc.php'
hackxchackxchackxc_404 =requests.get(url=u+hackxchackxchackxc,headers=headers)
# print len(hackxchackxchackxc_404.content)
xxxxxxxxxxxx = '/xxxxxxxxxxxx'
xxxxxxxxxxxx_404 = requests.get(url=u + xxxxxxxxxxxx, headers=headers)
# print len(xxxxxxxxxxxx_404.content)
#正常扫描
req = requests.get(url=u+dir,headers=headers,timeout=3,verify=False)
# print len(req.content)
if req.status_code==200:
if len(req.content)!=len(hackxchackxchackxc_404.content)and len(req.content)!= len(xxxxxxxxxxxx_404.content):
print "[+]",req.url
else:
print u+dir,404
except:
pass
很nice
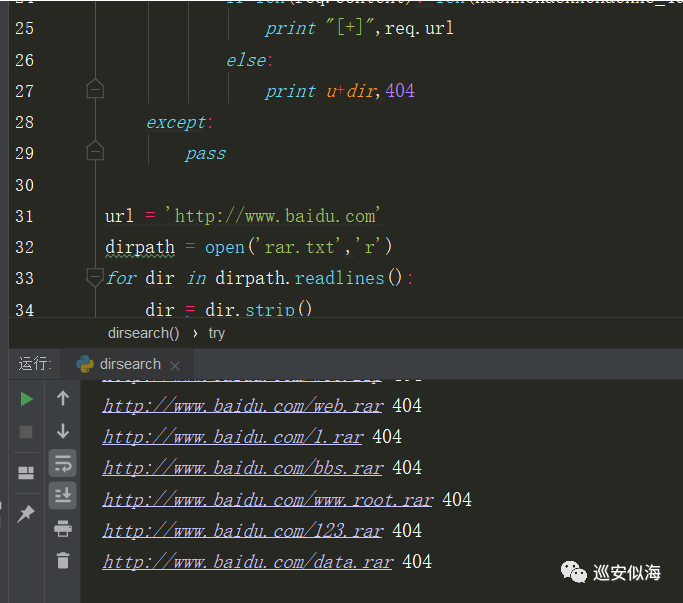
00x5:保存结果
再让结果自动保存
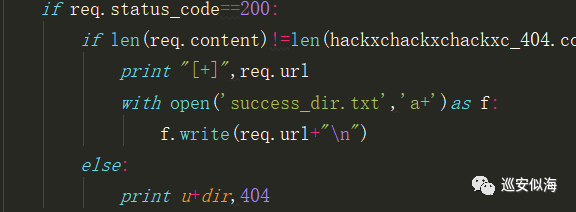
0x06:完整代码
#!/usr/bin/python
#-*- coding:utf-8 -*-
import requests
import urllib3
urllib3.disable_warnings()
urls = []
def dirsearch(u,dir):
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3314.0 Safari/537.36 SE 2.X MetaSr 1.0'}
#假的200页面进行处理
hackxchackxchackxc = '/hackxchackxchackxc.php'
hackxchackxchackxc_404 =requests.get(url=u+hackxchackxchackxc,headers=headers)
# print len(hackxchackxchackxc_404.content)
xxxxxxxxxxxx = '/xxxxxxxxxxxx'
xxxxxxxxxxxx_404 = requests.get(url=u + xxxxxxxxxxxx, headers=headers)
# print len(xxxxxxxxxxxx_404.content)
#正常扫描
req = requests.get(url=u+dir,headers=headers,timeout=3,verify=False)
# print len(req.content)
if req.status_code==200:
if len(req.content)!=len(hackxchackxchackxc_404.content)and len(req.content)!= len(xxxxxxxxxxxx_404.content):
print "[+]",req.url
with open('success_dir.txt','a+')as f:
f.write(req.url+"\n")
else:
print u+dir,404
else:
print u + dir, 404
except:
pass
if __name__ == '__main__':
url = raw_input('\nurl:')
print ""
if 'http' not in url:
url = 'http://'+url
dirpath = open('rar.txt','r')
for dir in dirpath.readlines():
dir = dir.strip()
dirsearch(url,dir)
以上就是PyHacker实现网站后台扫描器编写指南的详细内容,更多关于PyHacker网站后台扫描器的资料请关注我们其它相关文章!
相关推荐
-
Python端口扫描简单程序
本文实例为大家分享了Python端口扫描的实现代码,供大家参考,具体内容如下 获取本机的IP和端口号: import socket def get_my_ip(): try: csock = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) csock.connect(('8.8.8.8', 80)) (addr, port) = csock.getsockname() csock.close() return addr,port except s
-

PyHacker编写指南引用Nmap模块实现端口扫描器
目录 编写: 调试扫描: 方法扫描端口 输出状态: 引用Nmap库实现扫描功能,本节课比较简单一看就会. 编写环境:Python2.x 编写: 首先安装Nmap程序,并添加环境变量 pip install nmap pip install python-nmap 调试扫描: import nmap def nmapScan(host,port): nmScan=nmap.PortScanner() #实例化 state = nmScan.scan(host,port) #scan() 方法扫描端
-
Python利用socket模块开发简单的端口扫描工具的实现
一.socket 1.简介 Socket又称"套接字",应用程序通常通过"套接字"向网络发出请求或者应答网络请求,使主机间或者一台计算机上的进程间可以通讯. socket的工作流程 socket 采用C/S 模式,分为服务端和客户端 服务端数据处理流程 创建socket -> 绑定到地址和端口 -> 等待连接 -> 开始通信-> 关闭连接 客户端数据处理流程 创建socket -> 等待连接 -> 开始通信-> 关闭连接 客
-
PyHacker编写URL批量采集器
目录 00x1:需要用到的模块 00x2:选取搜索引擎 00x3:分析需要采集的url 00x4:搜索 00x5:自动保存 00x6:完整代码 喜欢用Python写脚本的小伙伴可以跟着一起写一写呀. 编写环境:Python2.x 00x1:需要用到的模块 需要用到的模块如下: import requests import re 本文将用re正则进行讲解,如果你用Xpath也可以 00x2:选取搜索引擎 首先我们要选取搜索引擎(其他搜索引擎原理相同) 以bing为例:Cn.bing.com 首先分
-
Pyhacker实现端口扫描器
目录 00x1:需要用到的模块 00x2:创建socket对象 00x3:处理ip 00x4:测试用例 00x5:设定扫描端口 00x6:完整代码 主要是以Nmap举例编写,其中涉及的协议暂不过多讨论 喜欢用Python写脚本的小伙伴可以跟着一起写一写呀. 编写环境:Python2.x 00x1:需要用到的模块 需要用到的模块如下: import socket import ipaddr 00x2:创建socket对象 首先我们先进写一个简单的通信 先创建socket对象 sockect = s
-
PyHacker实现网站后台扫描器编写指南
目录 00x1:模块 00x2:请求基本代码 00x3:设置 00x4:200页面处理 00x5:保存结果 0x06:完整代码 包括如何处理假的200页面/404智能判断等 喜欢用Python写脚本的小伙伴可以跟着一起写一写呀. 编写环境:Python2.x 00x1:模块 需要用到的模块如下: import request 00x2:请求基本代码 先将请求的基本代码写出来: import requests def dir(url): headers={'User-Agent': 'Mozill
-
Jekyll静态网站后台引擎使用教程
以前总想搭建一个自己的个人网站,由于不懂php后台,所以在点点网开过自己的博客,后来慢慢向程序员转变,点点网的博客已经不能满足这个职业特定的需求,于是用worldpress搭建了自己的第一个网站,鼓捣过几天worldpress,从购买域名空间,修改空间域名解析,添加模板,修改模板,了解了worldpress的强大之处,但是鼓捣玩了worldpress之后,没有了写文章的动力,也没有用足够的时间来管理,以至于这个网站夭折.直到现在又开始鼓捣Jekyll静态网站后台引擎,下面就讲讲Jekyll的学习
-
js iframe网站后台左右收缩型页面脚本
mobaihuo网站后台免费提供_我们_www.jb51.net .navPoint {COLOR: white; CURSOR: hand; FONT-FAMILY: Webdings; FONT-SIZE: 9pt} .a2{BACKGROUND-COLOR: A4B6D7;} mobaihuo网站后台免费提供 if(self!=top){top.location=self.location;} function switchSysBar(){ if (switchPoint.innerTe
-
jQuery实现B2B网站后台管理系统侧导航
效果图 1.html部分 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>index</title> <link rel="stylesheet" href="https://cdn.bootcss.com/font-awesome/4.6.0/css/font-awe
-
PHP的Laravel框架中使用AdminLTE模板来编写网站后台界面
AdminLTE 是一个基于Bootstrap 3.x的免费高级管理控制面板主题,完全响应式管理,适合从小型移动设备到大型台式机很多的屏幕分辨率. AdminLTE的特点: 充分响应 可分类的仪表盘 18插件和3自定义插件 重量轻和快速 与大多数主流浏览器兼容 完全支持Glyphicons,Fontawesome和图标 我们使用的工具 Laravel AdminLTE 2.3.2 Bower Composer 下载一个全新的 Laravel 如果不太清楚可以去官方网站查看文档link 在此我们直
-
IIS 网站服务器性能优化指南
但配置.优化IIS的性能,使得网站访问性能达到最优状态却不是一件简单的事情,这里我就介绍一下如何一步一步的优化你的IIS服务器. 服务器端环境,我们以Windows Server 2003的IIS6.0为例,客户端环境为Mozilla Firefox 3.0,同时安装Yahoo的YSlow扩展. YSlow是Yahoo开发者团队发布的一款基于Firebug的插件.用于分析网页,并根据一些高性能网站的规则进行相应的评级打分,对于网页性能优化有很好的帮助作用,告诉你那些部分影响了你的网页速度,并告诉
-
Python开发网站目录扫描器的实现
有人问为什么要去扫描网站目录:懂的人自然懂 这个Python脚本的特点: 1.基本完善 2.界面美观(只是画了个图案) 3.可选参数增加了线程数 4.User Agent细节处理 5.多线程显示进度 扫描目标:Metasploitable Linux 代码:WebDirScanner.py: # -*- coding:utf-8 -*- __author__ = "Yiqing" import sys import threading import random from Queue
-
彻底解决ewebeditor网站后台不能上传图片的方法
经我们技术员检查,结果原来是eWebEditor文本编辑器对IE8浏览器的兼容性导致的脚本错误,并不是什么"网站空间.服务器中毒.出问题了"呢! 现就将解决方法公布给大家,方便大家修正自己网站的代码以使文本编辑器在各种浏览器下都能兼容.正常使用! 解决IE8不支持eWebEditor在线文本编辑器的方法如下: [1]首先在eWebEditor文本编辑器根目录下的Include目录下找到editor.js文件(注意:不同的eWebEditor版本的editor.js文件所处目录可能有所不
-
Ruby on Rails网站项目构建简单指南
创建 Rails 项目 创建一个普通的 Rails 项目,可以直接使用以下命令: rails new blog 但在国内因为连接 RubyGems 的速度太慢,而 Rails 默认在构建完项目结构后,会使用 bundle 命令从 RubyGems 下载安装依赖包.最后会因为网络问题而卡死.所以需要使用 --skip-bundle 参数跳过执行 bundle 这一步.然后使用国内的 Gems 镜像源来完成后面依赖包的安装.国内推荐的源是 Ruby China 提供的: https://gems.r